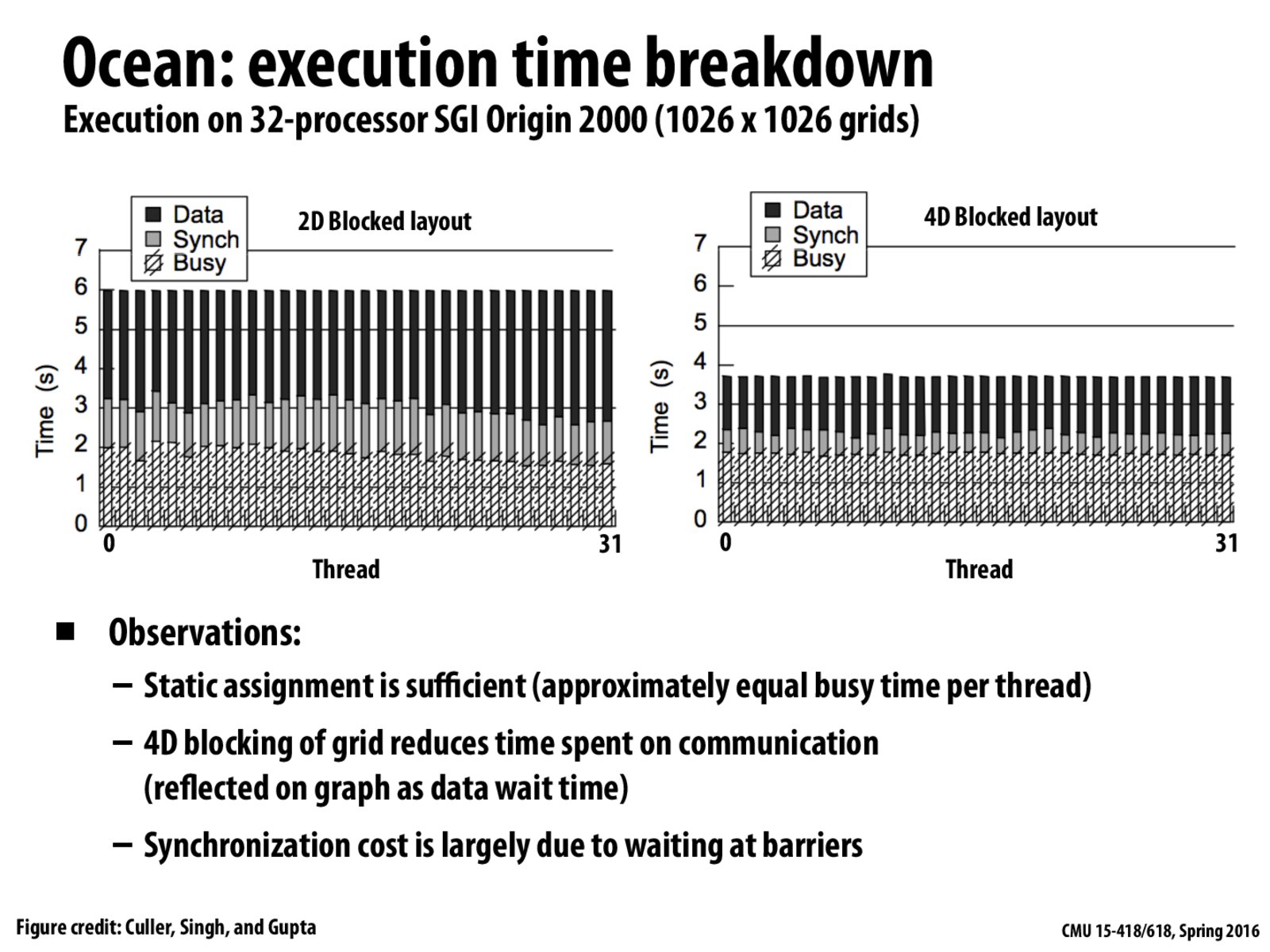
The graphs show that work (busy) is being done for about the same amount of time in both cases. The right graph spends less time waiting for memory accesses because the 4D blocked layout (shown on the previous slide) organizes the data in memory so spatial locality is improved and there are fewer cache misses. The processors all run for about the same time (the grey bars) so static assignment works well.
althalus
The difference in the gray bars between the two shows that by having better data layout, the sync time also decreases. I think this is probably due to the lower number of cache misses as mentioned in class. Are there any other reasons for this?
msfernan
As @althalus said reducing the number of cache misses reduces synchronization time as if some processors had cache hits and some had cache misses, the processors that had cache hits would have to wait at the barriers for processors that had cache misses thus increasing synchronization time for all processors.
Professor Kayvon also mentioned in class that the blocked layout reduces TLB misses. Maybe that too causes a decrease in sync time? Would someone be able to elaborate?
TanXiaoFengSheng
@msfernan, consider p1 in previous slide: the two consecutive rows in its tile span a huge amount of space, thus when p1 began to process the second row, it's more likely than blocked layout that to lay in another physical page, which requires another page table entry.
FarmerScrub
A large portion of the synchronization time is spent waiting for other threads to finish at barriers. A 4D blocked layout reduces the communication between threads, so there is there isn't as much waiting and synchronization time decreases.
misaka-10032
In the 4D blocked layout, threads have smaller difference in cache hit/miss patterns: only the beginning and the end of the whole block may be different. However, in 2D block layout, the beginning and the end of each row in each block may be different according to the block offset. Thus synchronization cost at barrier is decreased, because the blocks have smaller variance in total miss penalty (and thus in completion time).
The graphs show that work (busy) is being done for about the same amount of time in both cases. The right graph spends less time waiting for memory accesses because the 4D blocked layout (shown on the previous slide) organizes the data in memory so spatial locality is improved and there are fewer cache misses. The processors all run for about the same time (the grey bars) so static assignment works well.
The difference in the gray bars between the two shows that by having better data layout, the sync time also decreases. I think this is probably due to the lower number of cache misses as mentioned in class. Are there any other reasons for this?
As @althalus said reducing the number of cache misses reduces synchronization time as if some processors had cache hits and some had cache misses, the processors that had cache hits would have to wait at the barriers for processors that had cache misses thus increasing synchronization time for all processors.
Professor Kayvon also mentioned in class that the blocked layout reduces TLB misses. Maybe that too causes a decrease in sync time? Would someone be able to elaborate?
@msfernan, consider p1 in previous slide: the two consecutive rows in its tile span a huge amount of space, thus when p1 began to process the second row, it's more likely than blocked layout that to lay in another physical page, which requires another page table entry.
A large portion of the synchronization time is spent waiting for other threads to finish at barriers. A 4D blocked layout reduces the communication between threads, so there is there isn't as much waiting and synchronization time decreases.
In the 4D blocked layout, threads have smaller difference in cache hit/miss patterns: only the beginning and the end of the whole block may be different. However, in 2D block layout, the beginning and the end of each row in each block may be different according to the block offset. Thus synchronization cost at barrier is decreased, because the blocks have smaller variance in total miss penalty (and thus in completion time).