I am a little bit confused about why locating regions of memory near the processors increases scalability.
hofstee
@1pct it's very difficult to attach a couple thousand processors to a single block of memory. It's very easy to give each processor a few sticks of DRAM locally.
jaguar
Each processor having separate memory allows the bandwidth between the processor and the memory to be limited only by the processor closest to it in the ideal case. It also reduces the latency because the distance for communication is shorter.
colorblue
With NUMA we have the ability to put data we think will be accessed by a certain processor more often closer to the processor right? If so is this implemented in software in a way that when I go to access memory I have to modify it in order to determine which memory space to go in order to get the data? Is this just a variant of VM?
fleventyfive
@colorblue, no the programmer doesn't have to explicitly implement NUMA specific accesses in his/her software; it is done by the underlying hardware.
But, the programmer can definitely write intelligent code knowing that the underlying hardware is NUMA. Accessing local memory will definitely be faster, and the programmer can have access patterns in his/her code to exploit this fact. This is called writing NUMA-aware software.
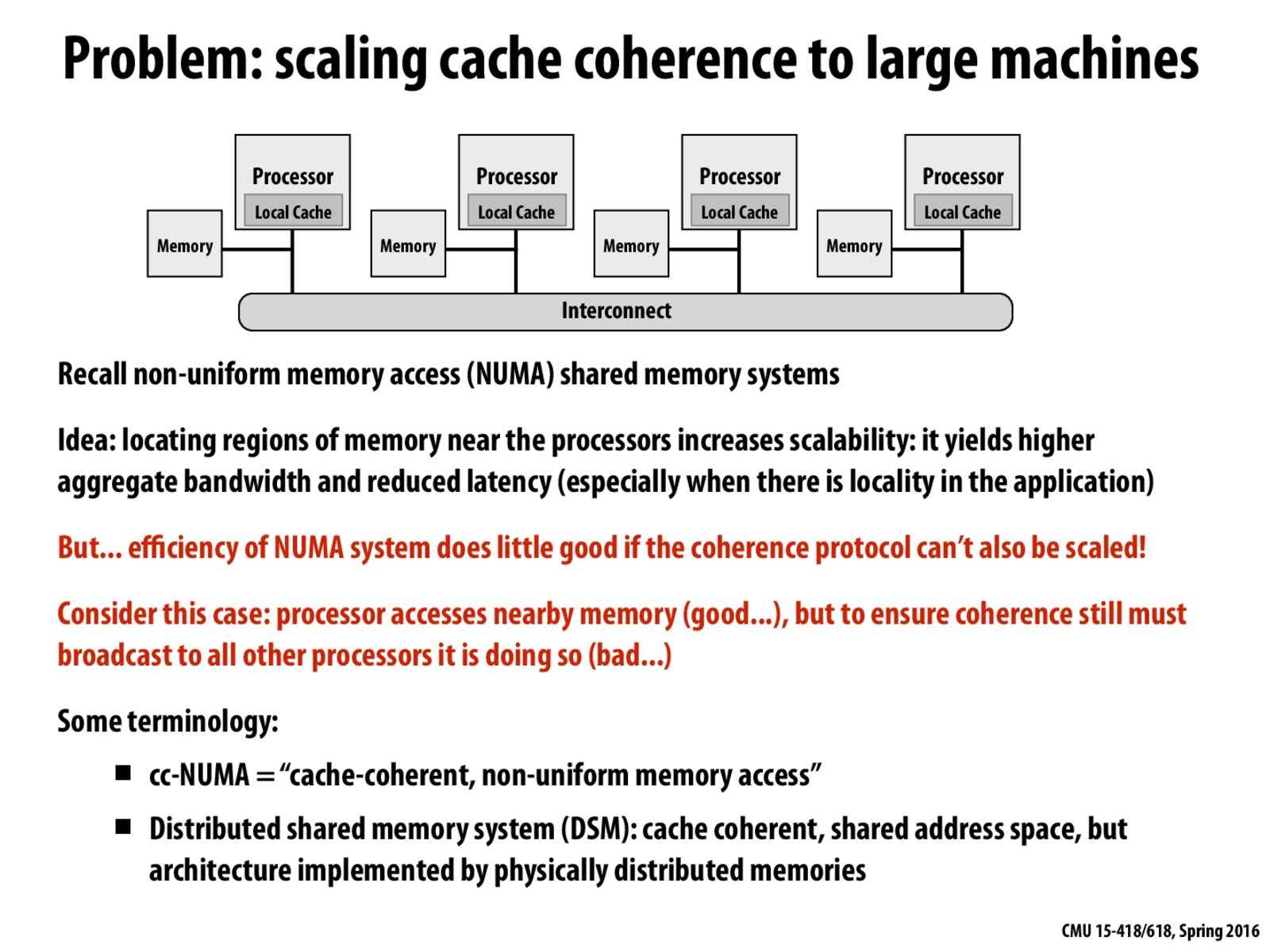
I am a little bit confused about why locating regions of memory near the processors increases scalability.
@1pct it's very difficult to attach a couple thousand processors to a single block of memory. It's very easy to give each processor a few sticks of DRAM locally.
Each processor having separate memory allows the bandwidth between the processor and the memory to be limited only by the processor closest to it in the ideal case. It also reduces the latency because the distance for communication is shorter.
With NUMA we have the ability to put data we think will be accessed by a certain processor more often closer to the processor right? If so is this implemented in software in a way that when I go to access memory I have to modify it in order to determine which memory space to go in order to get the data? Is this just a variant of VM?
@colorblue, no the programmer doesn't have to explicitly implement NUMA specific accesses in his/her software; it is done by the underlying hardware. But, the programmer can definitely write intelligent code knowing that the underlying hardware is NUMA. Accessing local memory will definitely be faster, and the programmer can have access patterns in his/her code to exploit this fact. This is called writing NUMA-aware software.