ReLU stands for rectified linear unit which uses an activation function $f(x)=max(0, x)$. Recent research shows it has many advantages over previous activation functions such as biological plausibility, sparse activation, and efficient gradient propagation.
haboric
A more concrete formula for ReLU in CNN uses $f(x) = max(0,x) + negativeSlope * min(0,x)$. In this case, if $x$ is negative, we choose not to ignore it, but multiply it by factor $negativeSlope$.
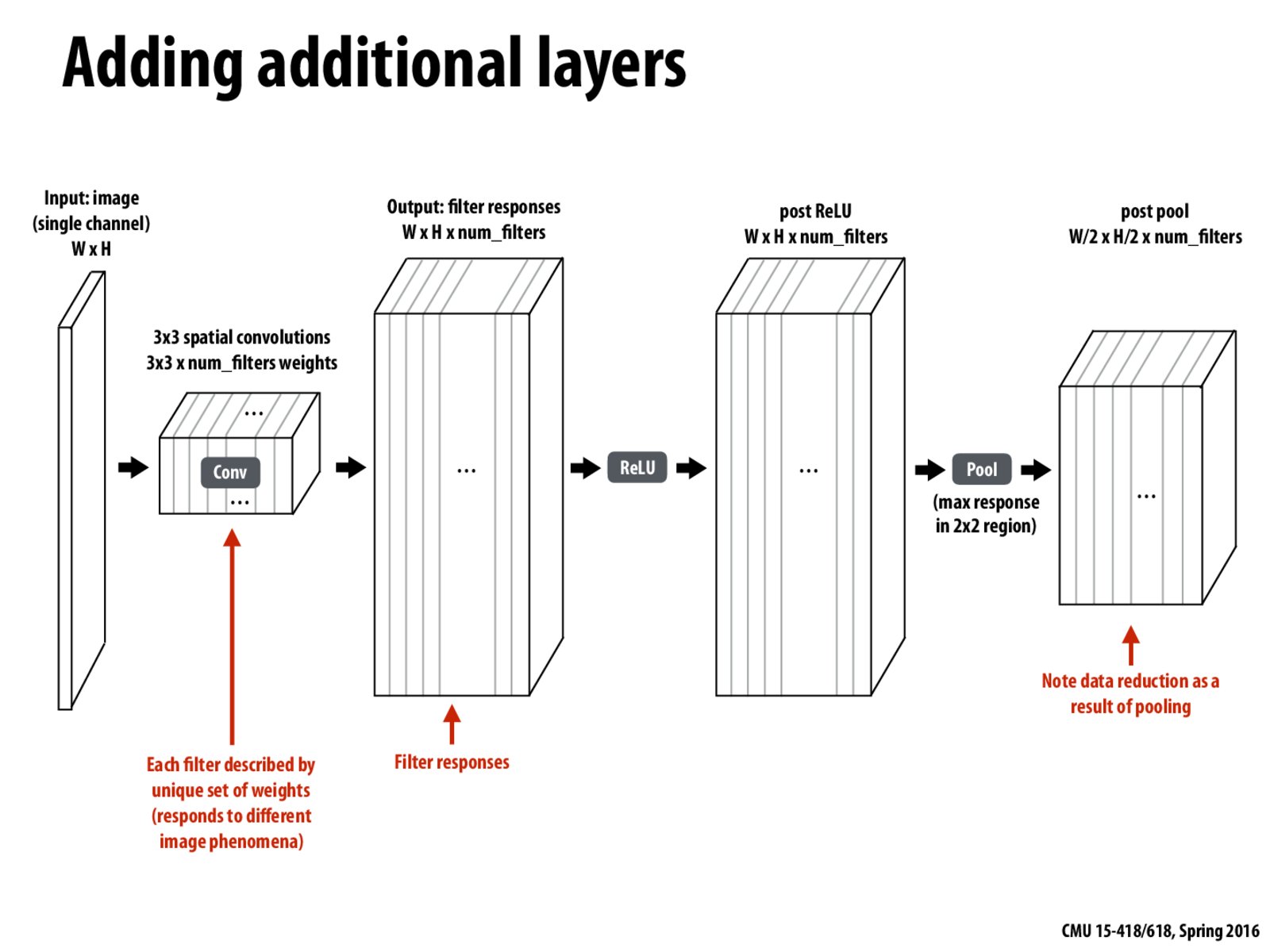
ReLU stands for rectified linear unit which uses an activation function $f(x)=max(0, x)$. Recent research shows it has many advantages over previous activation functions such as biological plausibility, sparse activation, and efficient gradient propagation.
A more concrete formula for ReLU in CNN uses $f(x) = max(0,x) + negativeSlope * min(0,x)$. In this case, if $x$ is negative, we choose not to ignore it, but multiply it by factor $negativeSlope$.