In the diagram above, I understand that the convolution layers are convolving with new weight filters. But what do the last 3 fully connected layers do? I thought that they are combining information from the two separate convolutions going on (top half and bottom half of the diagram), but why do you need 3 fully connected layers sequentially?
Araina
Here's the related reference from the paper.
BTW, the reason for two layer-parts is that the architecture has two GPUs.
The first convolutional layer filters the 224x224x3 input image with 96 kernels of size 11x11x3
with a stride of 4 pixels (this is the distance between the receptive field centers of neighboring neurons in a kernel map). The second convolutional layer takes as input the (response-normalized and pooled) output of the first convolutional layer and filters it with 256 kernels of size 5x5x48.
The third, fourth, and fifth convolutional layers are connected to one another without any intervening pooling or normalization layers. The third convolutional layer has 384 kernels of size 3x3x256 connected to the (normalized, pooled) outputs of the second convolutional layer. The fourth convolutional layer has 384 kernels of size 3x3x192 , and the fifth convolutional layer has 256 kernels of size 3x3x192. The fully-connected layers have 4096 neurons each.
RX
I'm curious why there are two horizontal layers
maxdecmeridius
What are those last 2 "dense" blocks doing?
TanXiaoFengSheng
@RX,that's explained in lecture, because it's too big to fit in one node, they split it into two GPUs.
TanXiaoFengSheng
@maxdecmeridius, I guess they are likely to be softmax layer which is doing actual classification work. It's like a generalization of logistic regression and it's popularly used in deep network. The most well-known application is to use a single softmax model to do MNIST classification and it can achieve more than 90% accuracy, quite impressive!
jsunseri
Interesting link - CNNs trained for object detection can also be used to generate those objects in images composed of random noise (preprocessed with a generic prior to make the noise have local correlation the way natural images do). The post points out that this kind of image generation is useful for identifying deficiencies in the training set after a round of training (e.g. the neural net thought that images of dumbbells always had to be accompanied by a flexing bicep). There are some novel research applications too, but I won't discuss them further to avoid getting scooped :P
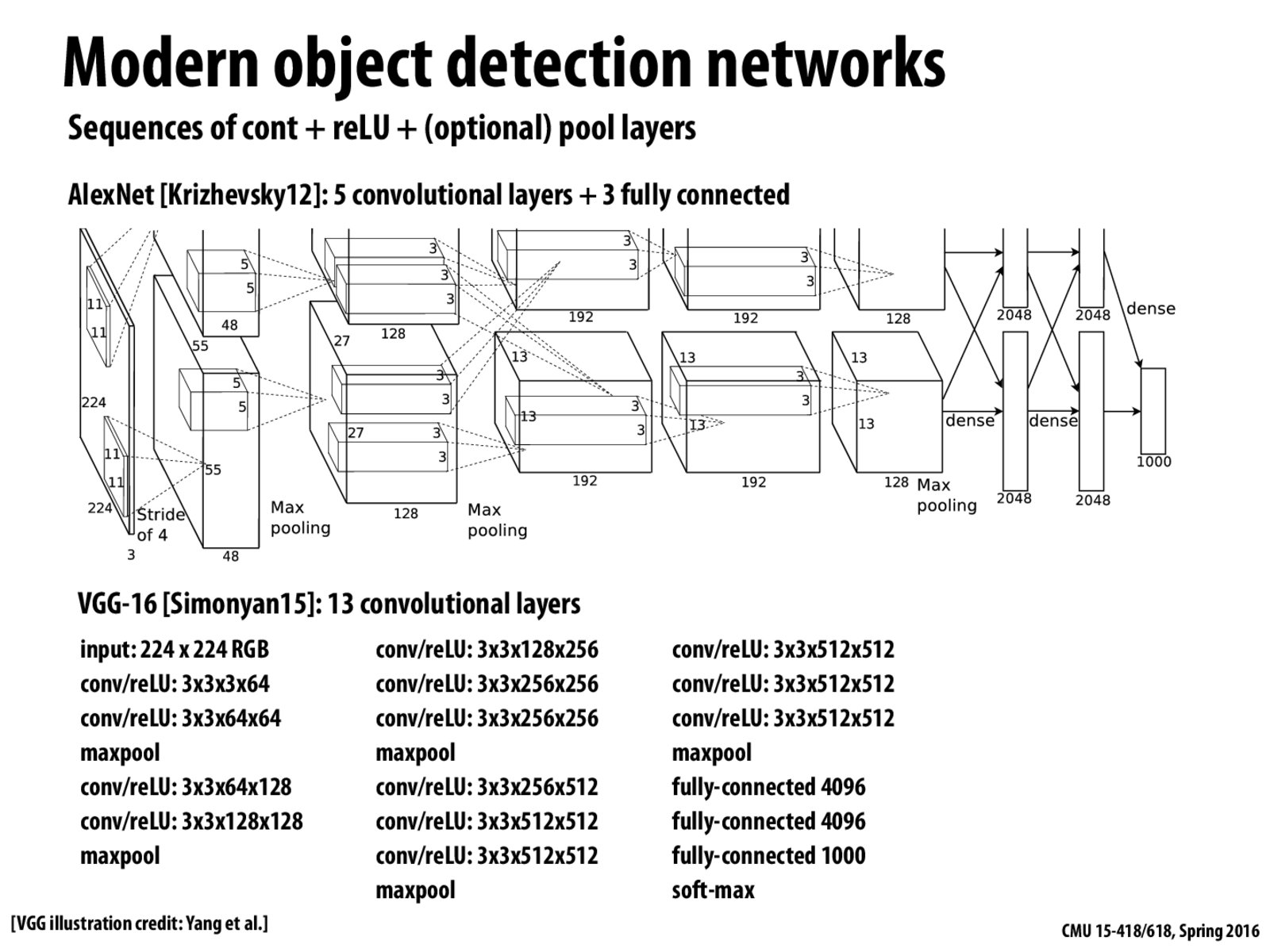
"AlexNet" was originally described in ImageNet Classification with Deep Convolutional Neural Networks by Krizhevsky et al. (NIPS 2012)
VGG-16 is a network from: Very Deep Convolutional Networks for Large-Scale Visual Recognition by Simonyan and Zisserman (ICLR 2015)
In the diagram above, I understand that the convolution layers are convolving with new weight filters. But what do the last 3 fully connected layers do? I thought that they are combining information from the two separate convolutions going on (top half and bottom half of the diagram), but why do you need 3 fully connected layers sequentially?
Here's the related reference from the paper.
BTW, the reason for two layer-parts is that the architecture has two GPUs.
The first convolutional layer filters the 224x224x3 input image with 96 kernels of size 11x11x3 with a stride of 4 pixels (this is the distance between the receptive field centers of neighboring neurons in a kernel map). The second convolutional layer takes as input the (response-normalized and pooled) output of the first convolutional layer and filters it with 256 kernels of size 5x5x48. The third, fourth, and fifth convolutional layers are connected to one another without any intervening pooling or normalization layers. The third convolutional layer has 384 kernels of size 3x3x256 connected to the (normalized, pooled) outputs of the second convolutional layer. The fourth convolutional layer has 384 kernels of size 3x3x192 , and the fifth convolutional layer has 256 kernels of size 3x3x192. The fully-connected layers have 4096 neurons each.
I'm curious why there are two horizontal layers
What are those last 2 "dense" blocks doing?
@RX,that's explained in lecture, because it's too big to fit in one node, they split it into two GPUs.
@maxdecmeridius, I guess they are likely to be softmax layer which is doing actual classification work. It's like a generalization of logistic regression and it's popularly used in deep network. The most well-known application is to use a single softmax model to do MNIST classification and it can achieve more than 90% accuracy, quite impressive!
Interesting link - CNNs trained for object detection can also be used to generate those objects in images composed of random noise (preprocessed with a generic prior to make the noise have local correlation the way natural images do). The post points out that this kind of image generation is useful for identifying deficiencies in the training set after a round of training (e.g. the neural net thought that images of dumbbells always had to be accompanied by a flexing bicep). There are some novel research applications too, but I won't discuss them further to avoid getting scooped :P