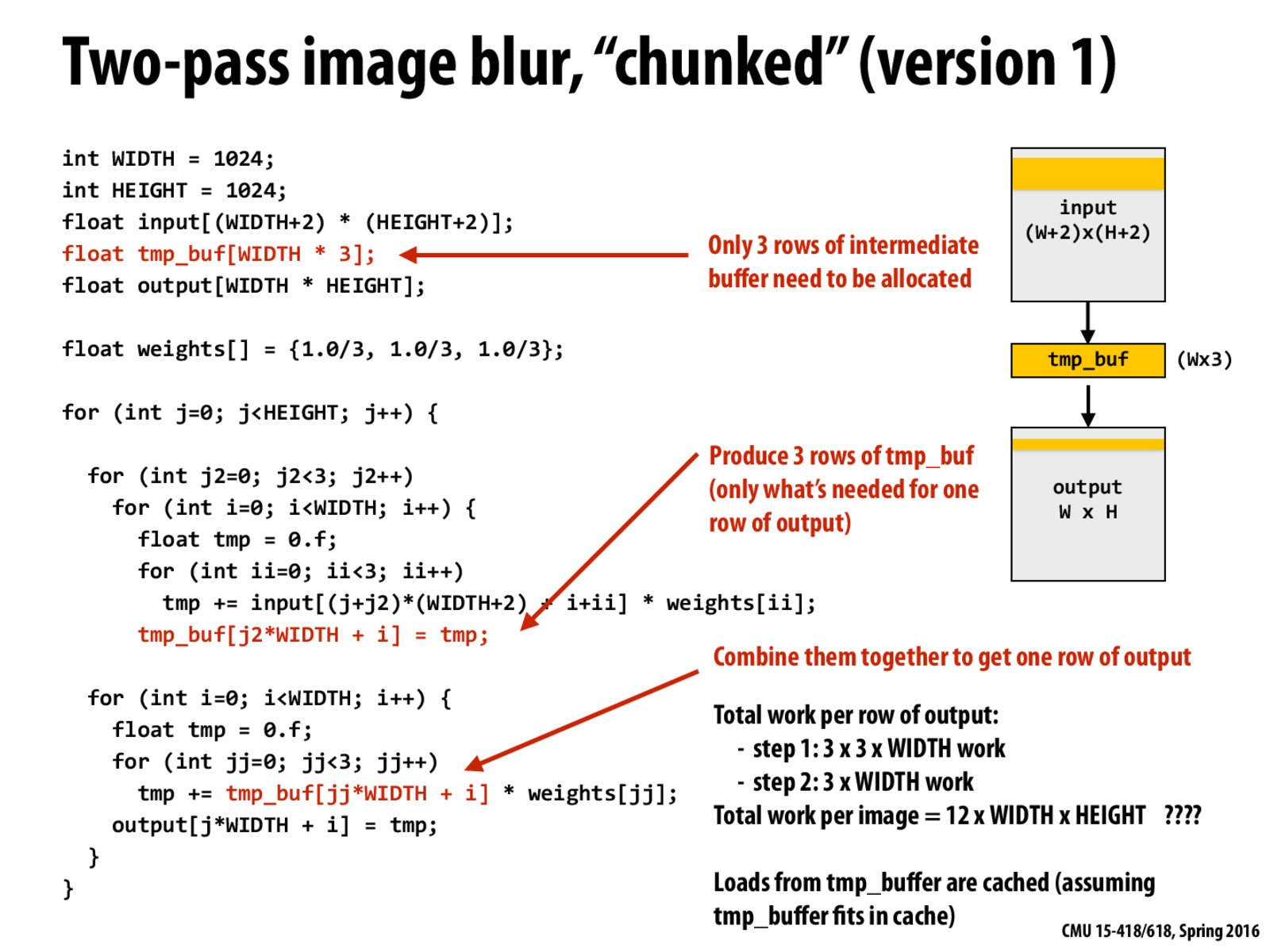
If someone is confused about why we use tmp_buf * weights instead of input * weights. It is because the weights now are 1.0/3 now.
So $\sum^3_{i,j=1}0.9~Input_{i,j} = \sum^3_i 0.3~ \sum^3_j 0.3 ~Input_{i,j}$
haboric
As mentioned in class, the goal of making tmp_buf small (3 rows) is to limit the footprint such that it fits into the cache.
teamG
I was initially confused by what the main problem of this implementation is other than the fact that we are doing extra work. In lecture, the reason is that we are actually throwing out the results that we computed for the temp_buf that could have been used to compute the final result for the other rows. So in this case, we have 3 rows of values computed for let's say row j=10, and we throw out some of the temp_buf values that could have also been used by row j=11.
misaka-10032
The main overhead comes from the re-computation of the next two rows. This case is equivalent to CHUNK_SIZE=1 in the next slide, while the extra two rows are overhead. When CHUNK_SIZE grows, the overhead portion shrinks, so the overall performance is increased.
If someone is confused about why we use
tmp_buf * weightsinstead ofinput * weights. It is because theweightsnow are1.0/3now.So $\sum^3_{i,j=1}0.9~Input_{i,j} = \sum^3_i 0.3~ \sum^3_j 0.3 ~Input_{i,j}$
As mentioned in class, the goal of making tmp_buf small (3 rows) is to limit the footprint such that it fits into the cache.
I was initially confused by what the main problem of this implementation is other than the fact that we are doing extra work. In lecture, the reason is that we are actually throwing out the results that we computed for the temp_buf that could have been used to compute the final result for the other rows. So in this case, we have 3 rows of values computed for let's say row j=10, and we throw out some of the temp_buf values that could have also been used by row j=11.
The main overhead comes from the re-computation of the next two rows. This case is equivalent to
CHUNK_SIZE=1in the next slide, while the extra two rows are overhead. WhenCHUNK_SIZEgrows, the overhead portion shrinks, so the overall performance is increased.