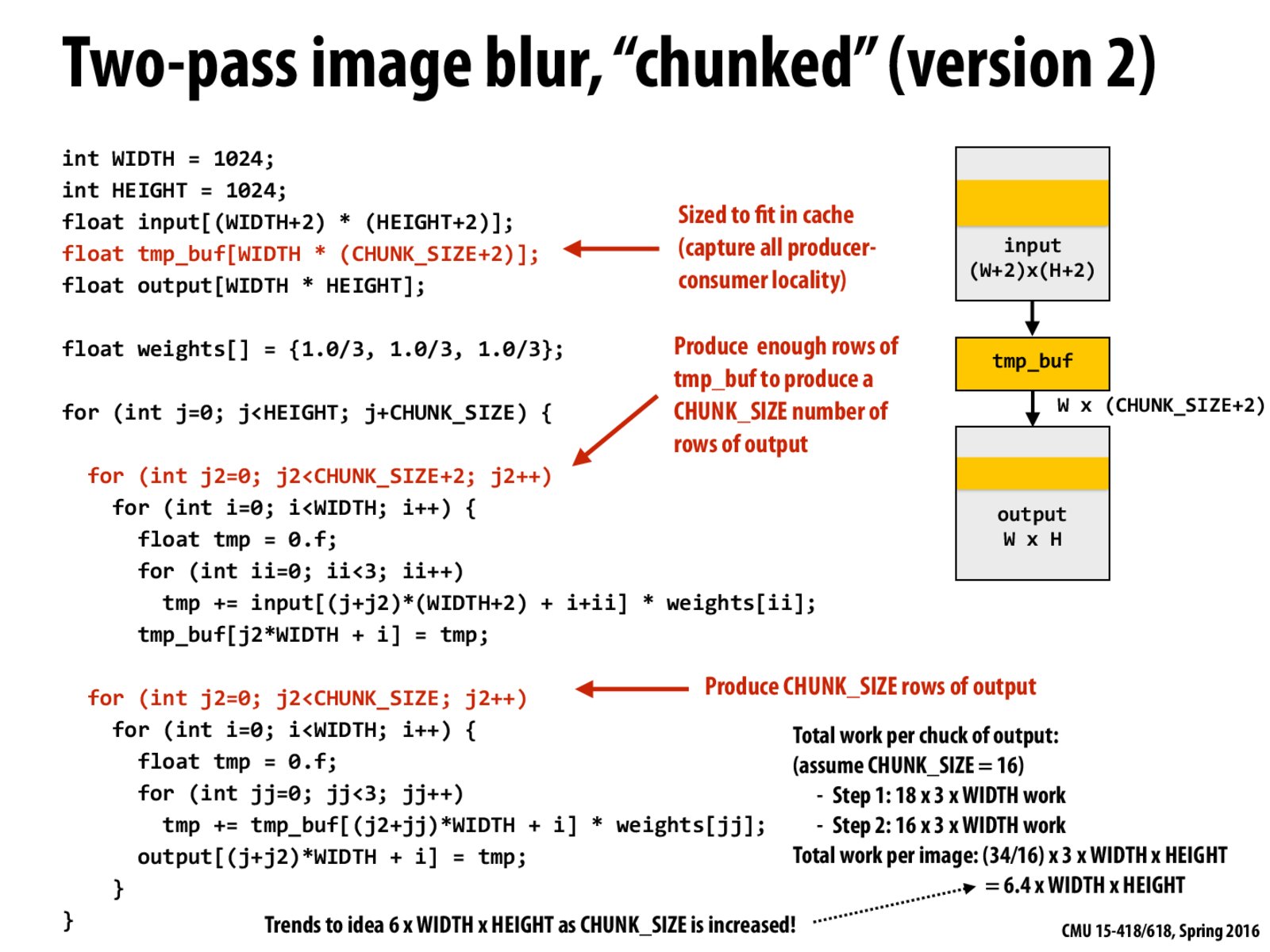
Not sure I understand the work analysis. Is the division by 16 in the total work per image to account for cache locality?
kayvonf
@thomasts. (18+14) * 3 * WIDTH operations to compute 16 rows of output (chunk size is 16 output rows).
Therefore, operations per image is (34 * 3 * WIDTH) * (HEIGHT/16)
xingdaz
@kayvonf, I think the slide is a bit misleading. It should say "Total work per CHUNK_SIZE number of rows of output" to emphasize cache reuse in comparison to the previous slide where for each row of output, we throw away the data in cache. I had similar confusion as @thomasts in the beginning.
kayvonf
@xingdaz. you are correct. I updated the slide with the fix. Please refresh.
bojianh
Can we use some kind of modulo and update only one row of the tmp_buf to reduce work for the previous slide?
doodooloo
@bojianh, I am thinking about the same thing. For the previous slide, instead of updating the whole buffer, we can update only one row (row = i % 3). That should reduce the cost to 6x, while keeping the size of the buffer to be 3*width.
Not sure I understand the work analysis. Is the division by 16 in the total work per image to account for cache locality?
@thomasts. (18+14) * 3 * WIDTH operations to compute 16 rows of output (chunk size is 16 output rows).
Therefore, operations per image is (34 * 3 * WIDTH) * (HEIGHT/16)
@kayvonf, I think the slide is a bit misleading. It should say "Total work per CHUNK_SIZE number of rows of output" to emphasize cache reuse in comparison to the previous slide where for each row of output, we throw away the data in cache. I had similar confusion as @thomasts in the beginning.
@xingdaz. you are correct. I updated the slide with the fix. Please refresh.
Can we use some kind of modulo and update only one row of the tmp_buf to reduce work for the previous slide?
@bojianh, I am thinking about the same thing. For the previous slide, instead of updating the whole buffer, we can update only one row (row = i % 3). That should reduce the cost to 6x, while keeping the size of the buffer to be 3*width.