How is it that a single GPU core can execute multiple threads and do SIMD execution as well?
bmperez
This might be a little late, but it actually isn't very difficult for the GPU to achieve this. I think you might also be getting the concept of a thread confused.
First, a clarification on "threads". A thread, at its core, is simply an instruction stream; it is a instruction pointer pointing to a series of instructions in memory. The model for GPU's is SPMD (single-program multiple-data), or also as I've also heard it referred to as: SIMT (single-instruction multiple-threads). Typically, a GPU has many threads executing the same instruction stream, but it can also support threads from different instruction streams. In reality, the threads are executed with SIMD engines, but this is a detail not exposed to the programmer.
As is mentioned later in the lecture, GPU threads are divided (internally by the hardware) into 32-wide warps. The reason is because the SIMD units on the GPU are 32-wide. Thus, it is possible for the GPU to execute warps from different instruction streams on different SIMD engines, because there are multiple of them per core. Additionally, the GPU can interleave the execution of warps on the same SIMD engines.
The warp execution context storage is for this purpose. Interleaving will occur if, for example, a warp gets stalled on a memory load; while it is waiting, another warp can execute. This is part of the reason why it is good to spawn a large number of threads at kernel launch. This allows for more opportunities for this interleaving to hide the latency of each individual warp.
Professor Kayvon also talks about this some on another slide. See slide 71 and slide 60.
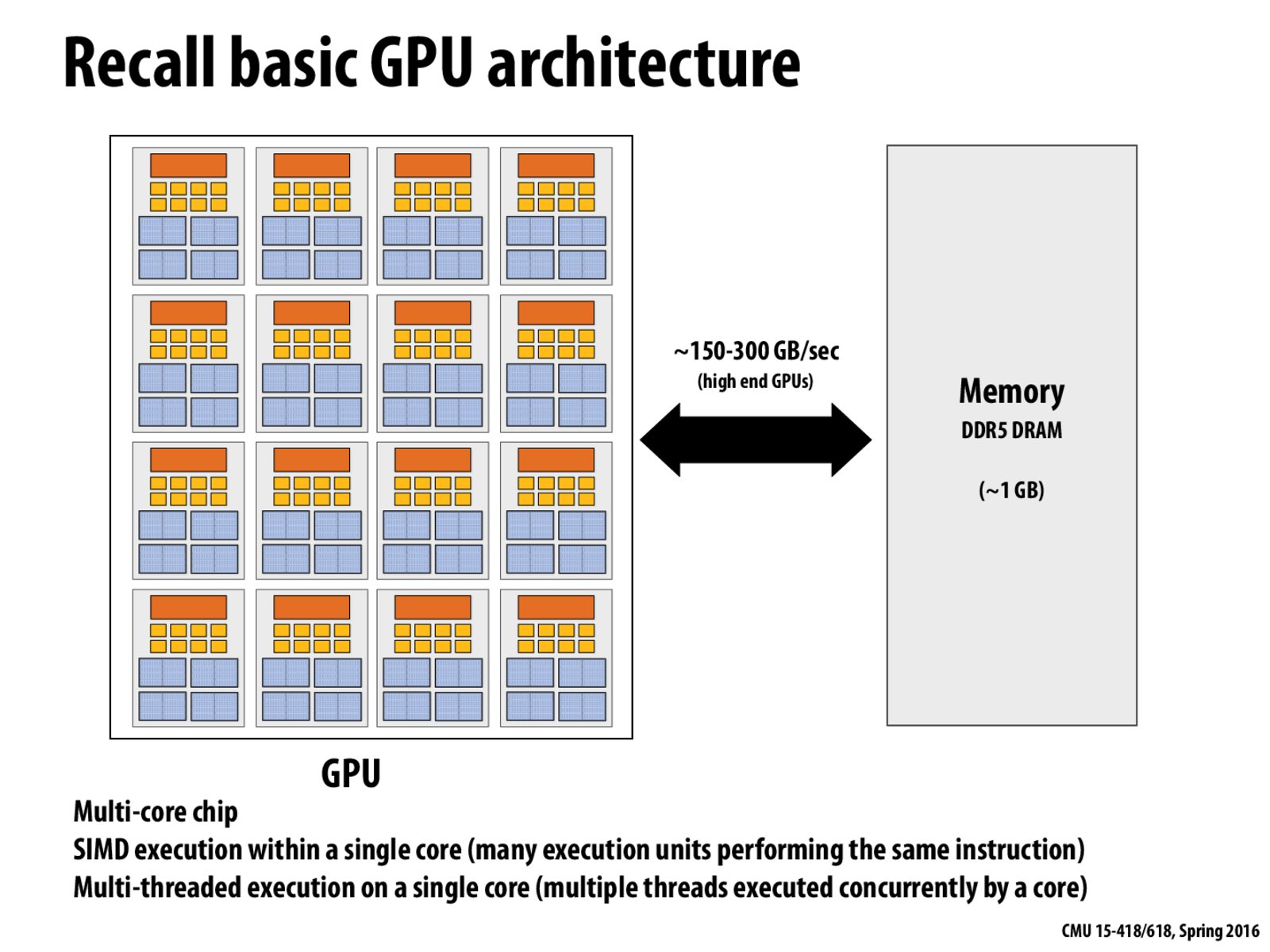
How is it that a single GPU core can execute multiple threads and do SIMD execution as well?
This might be a little late, but it actually isn't very difficult for the GPU to achieve this. I think you might also be getting the concept of a thread confused.
First, a clarification on "threads". A thread, at its core, is simply an instruction stream; it is a instruction pointer pointing to a series of instructions in memory. The model for GPU's is SPMD (single-program multiple-data), or also as I've also heard it referred to as: SIMT (single-instruction multiple-threads). Typically, a GPU has many threads executing the same instruction stream, but it can also support threads from different instruction streams. In reality, the threads are executed with SIMD engines, but this is a detail not exposed to the programmer.
As is mentioned later in the lecture, GPU threads are divided (internally by the hardware) into 32-wide warps. The reason is because the SIMD units on the GPU are 32-wide. Thus, it is possible for the GPU to execute warps from different instruction streams on different SIMD engines, because there are multiple of them per core. Additionally, the GPU can interleave the execution of warps on the same SIMD engines.
The warp execution context storage is for this purpose. Interleaving will occur if, for example, a warp gets stalled on a memory load; while it is waiting, another warp can execute. This is part of the reason why it is good to spawn a large number of threads at kernel launch. This allows for more opportunities for this interleaving to hide the latency of each individual warp.
Professor Kayvon also talks about this some on another slide. See slide 71 and slide 60.