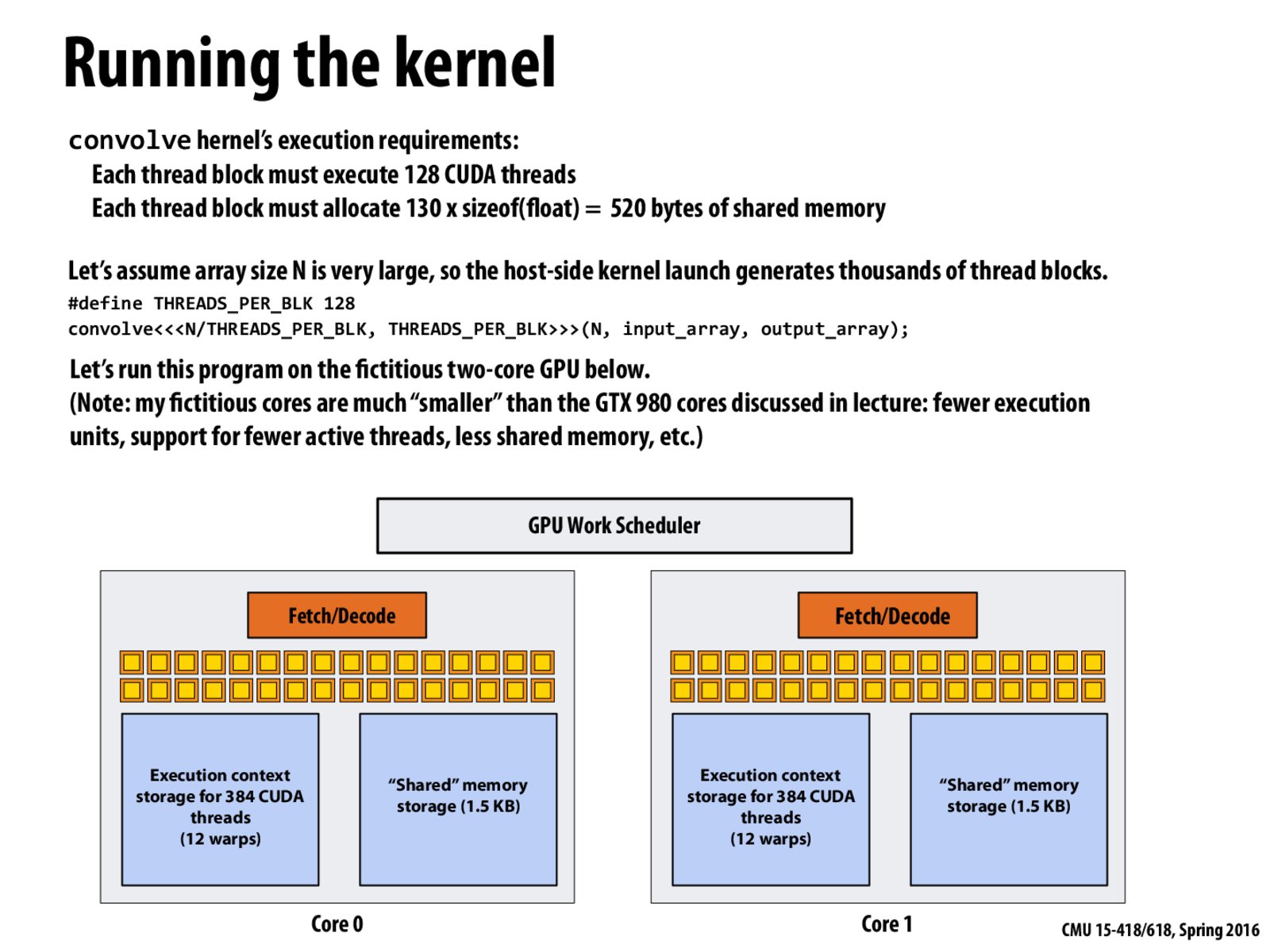
Why are there 12 warps? I imagine that the number of warps should equal the number of "Fetch/Decode" modules.
Is "warp" an abstract concept or a hardware concept? In another file, it seems to describe the warp as the "thread" in CPU, in that when doing hardware multi-threading, each "thread" here is a warp. (This "thread" is different from CUDA thread)
Fantasy
I think "Warp" is a hardware concept like "execution context" for CPU. As slide 56 shows, there are 64 warps (64 different instruction streams), and for each time clock, the 4 warp selector will select 4 runnable warps to run.
Richard
@Fantasy Thanks! So each warp can support one CPU-type thread, and can support 32 CUDA threads in the above example.
kayvonf
Yes, you guys got it. Take a look at this slide for more detail about warps. A warp corresponds to a set of 32 CUDA threads that share an instruction stream. It would be reasonable to think about a warp like a traditional x86 thread executing a SIMD instruction stream, and a warp execution context to be the state required to manage all of those CUDA threads.
The resources needed to execute a warp are akin to the resources needed to execute an ISPC gang. (Although a gang is an ISPC programming model concept and a warp is really a CUDA implementation detail.)
lol
Are CUDA threads staticly mapped to warps? If so, is it contiguous?
Why are there 12 warps? I imagine that the number of warps should equal the number of "Fetch/Decode" modules.
Is "warp" an abstract concept or a hardware concept? In another file, it seems to describe the warp as the "thread" in CPU, in that when doing hardware multi-threading, each "thread" here is a warp. (This "thread" is different from CUDA thread)
I think "Warp" is a hardware concept like "execution context" for CPU. As slide 56 shows, there are 64 warps (64 different instruction streams), and for each time clock, the 4 warp selector will select 4 runnable warps to run.
@Fantasy Thanks! So each warp can support one CPU-type thread, and can support 32 CUDA threads in the above example.
Yes, you guys got it. Take a look at this slide for more detail about warps. A warp corresponds to a set of 32 CUDA threads that share an instruction stream. It would be reasonable to think about a warp like a traditional x86 thread executing a SIMD instruction stream, and a warp execution context to be the state required to manage all of those CUDA threads.
The resources needed to execute a warp are akin to the resources needed to execute an ISPC gang. (Although a gang is an ISPC programming model concept and a warp is really a CUDA implementation detail.)
Are CUDA threads staticly mapped to warps? If so, is it contiguous?