Notice the first argument to cudaMalloc... It is a pointer to a pointer! Why not just pass a pointer, and then access the memory from that pointer? Well, this is one of the design choices that apparently wasn't received well, and the reason for having a double pointer is because: (taken from stackoverflow)
"All CUDA API functions return an error code (or cudaSuccess if no error occured). All other parameters are passed by reference. However, in plain C you cannot have references, that's why you have to pass an address of the variable that you want the return information to be stored. Since you are returning a pointer, you need to pass a double-pointer."
rmanne
Perhaps you could say that this is a better way, since you don't have to check errno. I've always thought returning error codes is a bit nicer, and in the case of a GPU where locking might take a lot more effort (so that errno isn't erased by the time you read it), it may be a good choice after all.
xx420y0los4wGxx
From what I understand, GPUs are good at processing many small operations (since they have tons of small "processors") and CPUs are good at processing larger operations. We've covered applications that run well on either GPUs or CPUs (saxpy), but are there any operations that would benefit from both CPU threads and GPU threads writing to the same memory space in parallel? Or is the overhead of cudaMemcpy too high?
An example might be the grid solver from the previous lecture. If there were 1/4 as many black dots as red dots, but each took X times the time to compute compared to a red dot, it might be beneficial to compute the black dots with CPU threads and share the data with memcpys.
c0d3r
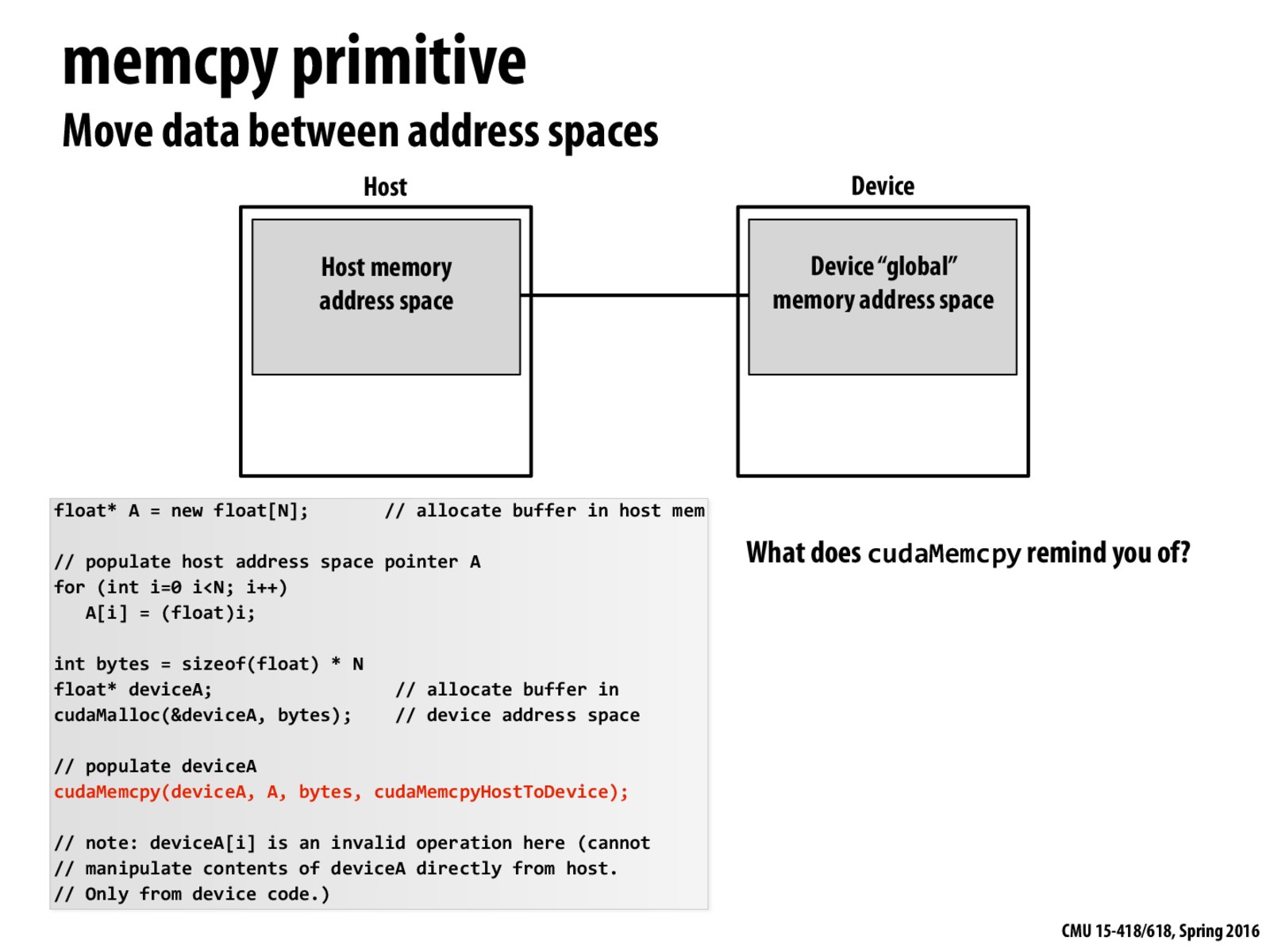
Could someone answer the question posted: "What does cudaMemcpy remind you of?" I would say it reminds me of copying data from main memory to a cache, but that is just my take on it.
notanonymous
cudaMemcpy should remind you of message sending as a means for sharing addresses. In this case, cudaMemcpy is sending a "message" (copying data) from the host (cpu) address space to the device (gpu) address space.
kayvonf
@notanonymous. I agree. But did you mean to write "since it's a means for communicating data between address spaces."?
Notice the first argument to
cudaMalloc... It is a pointer to a pointer! Why not just pass a pointer, and then access the memory from that pointer? Well, this is one of the design choices that apparently wasn't received well, and the reason for having a double pointer is because: (taken from stackoverflow)"All CUDA API functions return an error code (or
cudaSuccessif no error occured). All other parameters are passed by reference. However, in plain C you cannot have references, that's why you have to pass an address of the variable that you want the return information to be stored. Since you are returning a pointer, you need to pass a double-pointer."Perhaps you could say that this is a better way, since you don't have to check
errno. I've always thought returning error codes is a bit nicer, and in the case of a GPU where locking might take a lot more effort (so thaterrnoisn't erased by the time you read it), it may be a good choice after all.From what I understand, GPUs are good at processing many small operations (since they have tons of small "processors") and CPUs are good at processing larger operations. We've covered applications that run well on either GPUs or CPUs (saxpy), but are there any operations that would benefit from both CPU threads and GPU threads writing to the same memory space in parallel? Or is the overhead of cudaMemcpy too high?
An example might be the grid solver from the previous lecture. If there were 1/4 as many black dots as red dots, but each took X times the time to compute compared to a red dot, it might be beneficial to compute the black dots with CPU threads and share the data with memcpys.
Could someone answer the question posted: "What does cudaMemcpy remind you of?" I would say it reminds me of copying data from main memory to a cache, but that is just my take on it.
cudaMemcpyshould remind you of message sending as a means for sharing addresses. In this case,cudaMemcpyis sending a "message" (copying data) from the host (cpu) address space to the device (gpu) address space.@notanonymous. I agree. But did you mean to write "since it's a means for communicating data between address spaces."?