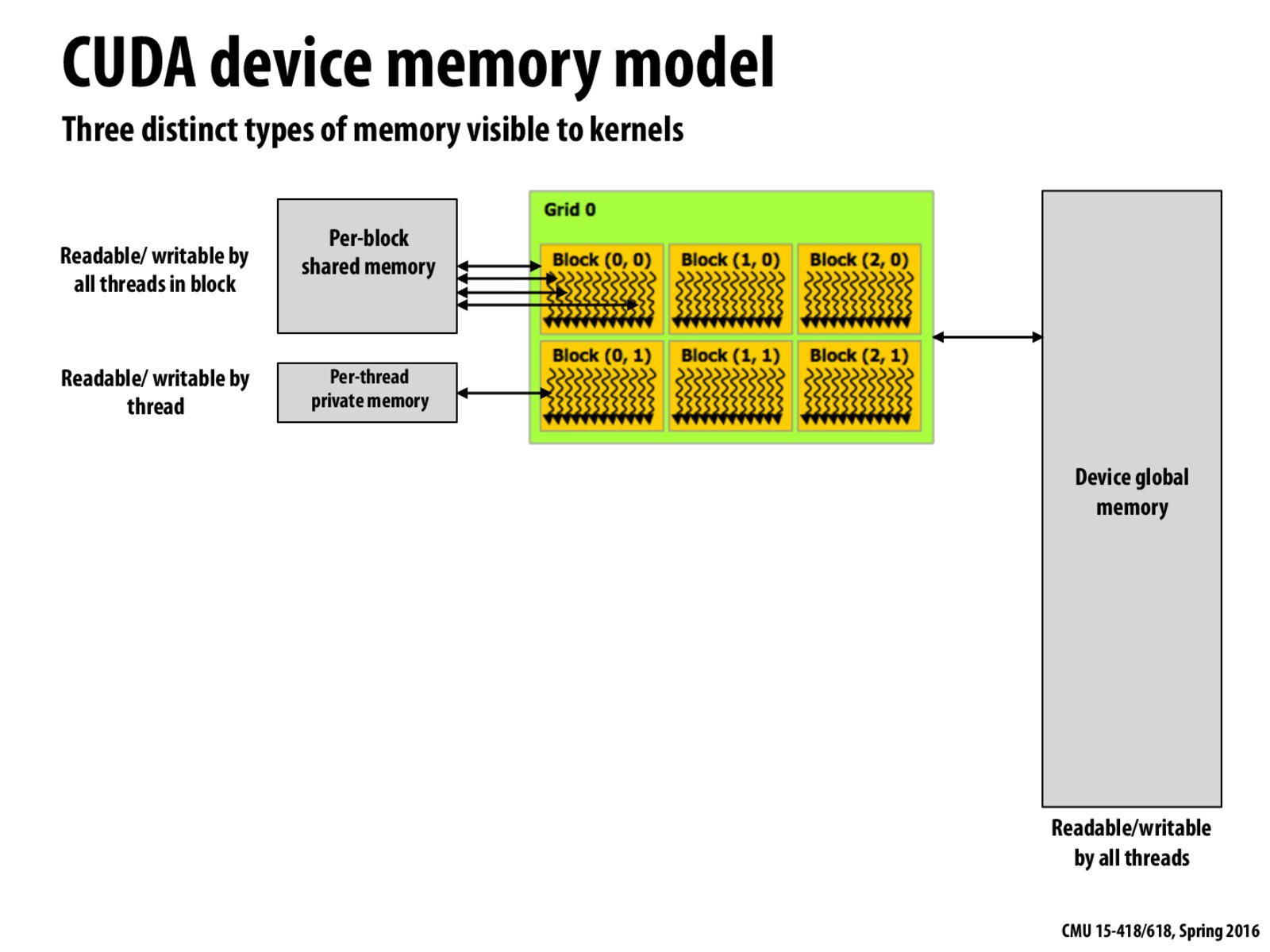
Since kernels are side-effect free, and operate only on their input/output streams (placed in per-block shared memory by the GPU scheduler, according to the review section of this lecture), why do kernels need to have an interface with the device's global memory? Shouldn't the GPU scheduler be the inbetween global memory and the kernels?
zvonryan
Scheduler only perform resource allocation functionalities. I guess we can consider global memory as heap space and shared memory as stack space in here, since shared memory space is on chip and global memory is on device. The usage of different types of memory vary, so the corresponding interfaces would exist.
mrrobot
Where exactly is the per thread private memory allocated? Is this also allocated as a part of the per-block shared memory or only variables declared with shared are allocated there?
sasthana
Because there is no other memory shown so the only viable option for thread local memory appears to be the shared 96k memory.
kayvonf
Question: @a brings up some interesting questions here. Please discuss! (I'll begin by noting that a kernel in a pure data-parallel system is usually side-effect-side, CUDA kernels are certainly not!)
pkoenig10
The input/output streams given to the kernel could reference pointers to other locations in global memory. For this reason they need an interface with the device's global memory, not just the data passed in by the GPU scheduler.
althalus
Does the kernel need to load memory initially? If yes, it would make sense for it to interface with the device's global memory.
1pct
We have talked about the latency of accessing memory in previous lectures. Considering the 3 kinds of memory block in the above slides, I think that, when accessing memory, the latency of pre-thread private memory is shorter than the latency of pre-block shared memory. And the latency of pre-block shared memory is shorter than the device global memory. Is that correct?
CC
@1pct is right, and this looks somewhat like the memory hierarchy we normally see (different levels of memory). The tradeoff between speed and space always exists. Per-thread and per-block memories are fast and can be used for frequently accessed data and communication, while global memory can contain more data with slower access.
Since kernels are side-effect free, and operate only on their input/output streams (placed in per-block shared memory by the GPU scheduler, according to the review section of this lecture), why do kernels need to have an interface with the device's global memory? Shouldn't the GPU scheduler be the inbetween global memory and the kernels?
Scheduler only perform resource allocation functionalities. I guess we can consider global memory as heap space and shared memory as stack space in here, since shared memory space is on chip and global memory is on device. The usage of different types of memory vary, so the corresponding interfaces would exist.
Where exactly is the per thread private memory allocated? Is this also allocated as a part of the per-block shared memory or only variables declared with shared are allocated there?
Because there is no other memory shown so the only viable option for thread local memory appears to be the shared 96k memory.
Question: @a brings up some interesting questions here. Please discuss! (I'll begin by noting that a kernel in a pure data-parallel system is usually side-effect-side, CUDA kernels are certainly not!)
The input/output streams given to the kernel could reference pointers to other locations in global memory. For this reason they need an interface with the device's global memory, not just the data passed in by the GPU scheduler.
Does the kernel need to load memory initially? If yes, it would make sense for it to interface with the device's global memory.
We have talked about the latency of accessing memory in previous lectures. Considering the 3 kinds of memory block in the above slides, I think that, when accessing memory, the latency of pre-thread private memory is shorter than the latency of pre-block shared memory. And the latency of pre-block shared memory is shorter than the device global memory. Is that correct?
@1pct is right, and this looks somewhat like the memory hierarchy we normally see (different levels of memory). The tradeoff between speed and space always exists. Per-thread and per-block memories are fast and can be used for frequently accessed data and communication, while global memory can contain more data with slower access.