How do we figure out the appropriate number of threads per block and number of blocks? Does it matter to the efficiency of the code?
kayvonf
@christtz: In order to choose good sizes, you'll have to think about how a CUDA thread block is mapped to GPU hardware execution resources. Study this example and then think about this question some more!
ote
@christzz I thought this answer on Stack Overflow was a helpful second look at it, going into both the hardware constraints and working for performance.
PandaX
I just noticed that there are 4MB of data to be processed by CUDA in this example!
So my question is:
Will the data transferring become the bottleneck in this example? (I heard about the data transferring between GPU and CPU is very slow~)
mperron
As an extension to the question asked by @christtz, is it better to pick values for threads and number of blocks independent of hardware to improve reusability, or is it typical to write separate code for separate hardware? Do CUDA compilers give you any ability to adjust these values to the hardware at compile or run time through processor macros or other resources?
kayvonf
@mperron. I think we'd all agree we'd love to be able to write code that was structured so that it performed well across a large class of machines -- and we should strive to do that. So I'd answer your question as: If you can write performance-portable code, by all means do it!
However, there are certainly times where if you really want maximum performance, you'd have to start thinking about machine details.
PIC
@kayvonf How much of the memory management is done by the hardware? If I allocate 1000000 local variables, they won't fit into thread local memory. Does the compiler just reject the code?
kayvonf
@PIC. If your program declares a need for more shared memory space than the chip allows (or specifically, the CUDA compute capability you are compiling against allows), than that is a compile error.
PIC
@kayvonf I guess I am trying to relate this to programming on CPU. On a CPU you're allowed to allocate more local variables then there are registers, you're allowed to allocate more memory then fits in your L1 and L2 caches. When you access more memory than fits in the respective layer of the hierarchy that you are trying to access the hardware "automatically" will propagate the data from the data upward from the "lower levels". Will this happen on a GPU? How explicitly do I have to manage the division between global and thread local memory?
kayvonf
Great question. I ask you specifically about this question on the current quiz. ;-)
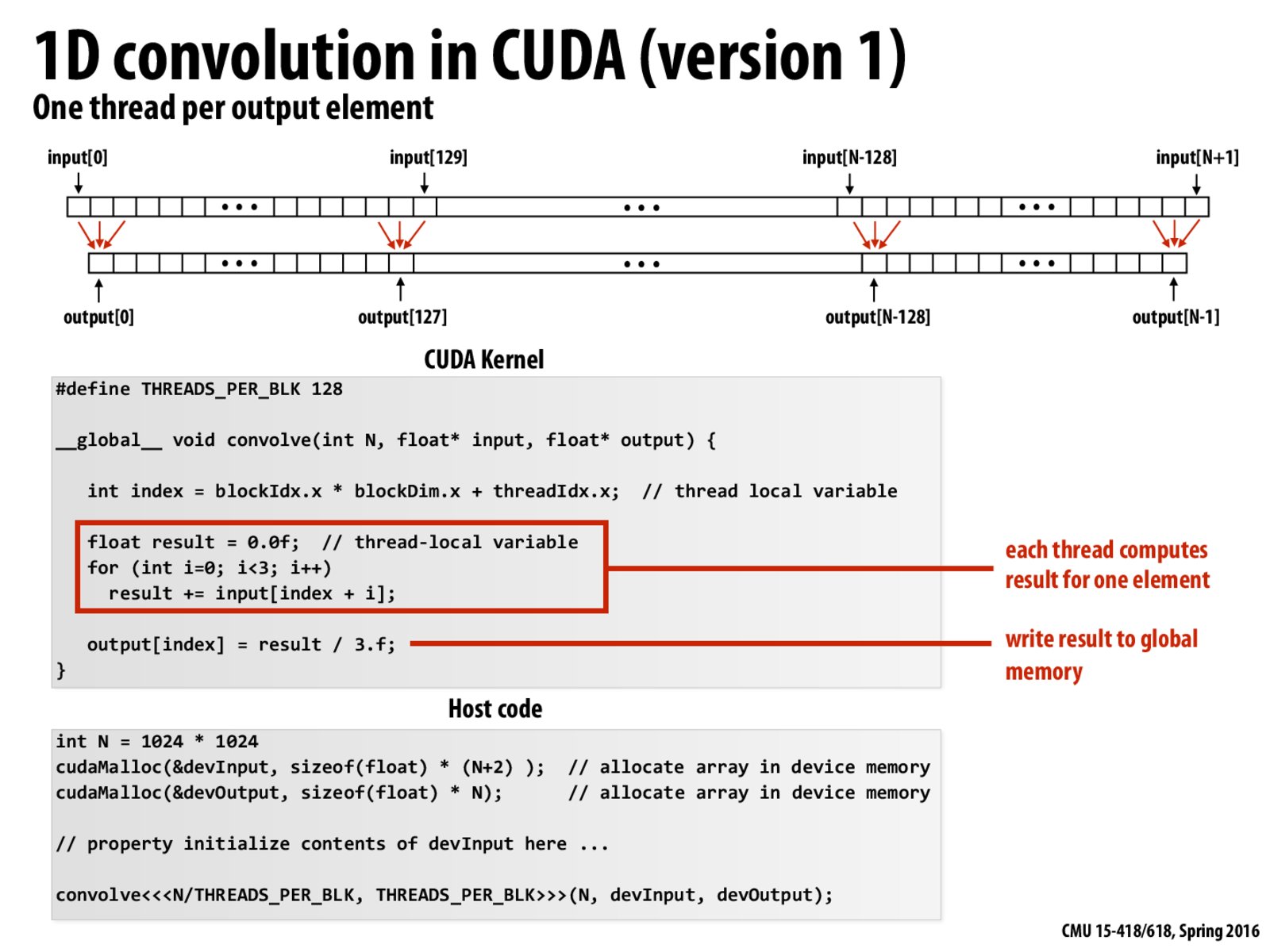
How do we figure out the appropriate number of threads per block and number of blocks? Does it matter to the efficiency of the code?
@christtz: In order to choose good sizes, you'll have to think about how a CUDA thread block is mapped to GPU hardware execution resources. Study this example and then think about this question some more!
@christzz I thought this answer on Stack Overflow was a helpful second look at it, going into both the hardware constraints and working for performance.
I just noticed that there are 4MB of data to be processed by CUDA in this example!
So my question is: Will the data transferring become the bottleneck in this example? (I heard about the data transferring between GPU and CPU is very slow~)
As an extension to the question asked by @christtz, is it better to pick values for threads and number of blocks independent of hardware to improve reusability, or is it typical to write separate code for separate hardware? Do CUDA compilers give you any ability to adjust these values to the hardware at compile or run time through processor macros or other resources?
@mperron. I think we'd all agree we'd love to be able to write code that was structured so that it performed well across a large class of machines -- and we should strive to do that. So I'd answer your question as: If you can write performance-portable code, by all means do it!
However, there are certainly times where if you really want maximum performance, you'd have to start thinking about machine details.
@kayvonf How much of the memory management is done by the hardware? If I allocate 1000000 local variables, they won't fit into thread local memory. Does the compiler just reject the code?
@PIC. If your program declares a need for more shared memory space than the chip allows (or specifically, the CUDA compute capability you are compiling against allows), than that is a compile error.
@kayvonf I guess I am trying to relate this to programming on CPU. On a CPU you're allowed to allocate more local variables then there are registers, you're allowed to allocate more memory then fits in your L1 and L2 caches. When you access more memory than fits in the respective layer of the hierarchy that you are trying to access the hardware "automatically" will propagate the data from the data upward from the "lower levels". Will this happen on a GPU? How explicitly do I have to manage the division between global and thread local memory?
Great question. I ask you specifically about this question on the current quiz. ;-)