Since threads in the same block share the same warp context, do warps have anything to do with shared block memory?
Richard
Threads in the same block don't necessarily share the same warp context... Chances are several warps accommodate one block.
karima
@Richard right. 32 threads in a warp, and these 32 threads get one warp context. If you have 64 threads in your thread block, you need two warp contexts for your entire thread block.
@eknight7 shared memory exists on thread block level not on the warp level. All threads in a thread block share a certain amount of shared memory. So several warps worth of CUDA threads share a certain amount of shared memory.
Another important thing to note is how much shared memory is available to each thread block. Looking back at this slide tells us that the more thread blocks you want to assign to one GPU core, the fewer bytes of shared memory each thread block can use. So if I had 1.5KB of shared memory on a GPU core and I wanted to put 5 thread blocks on that one core, I better make sure each thread block needs at most 0.3KB of shared memory.
bullseye
While reading up on the Kepler multiprocessor, I found that there are a few limits on the numbers of thread blocks and warps per thread block (16 and 32, respectively). Why do these limits exist? This may prevent certain arrangements of thread blocks that may be needed to exploit concurrency and parallelism within a multiprocessor.
ArbitorOfTheFountain
My intuition tells me that the reason behind limiting thread blocks and warps per block is that MOST workloads would not benefit from raising those numbers. It's a trade-off between how silicon is used, and they choose the arrangement which provides the most benefit for the most common workloads.
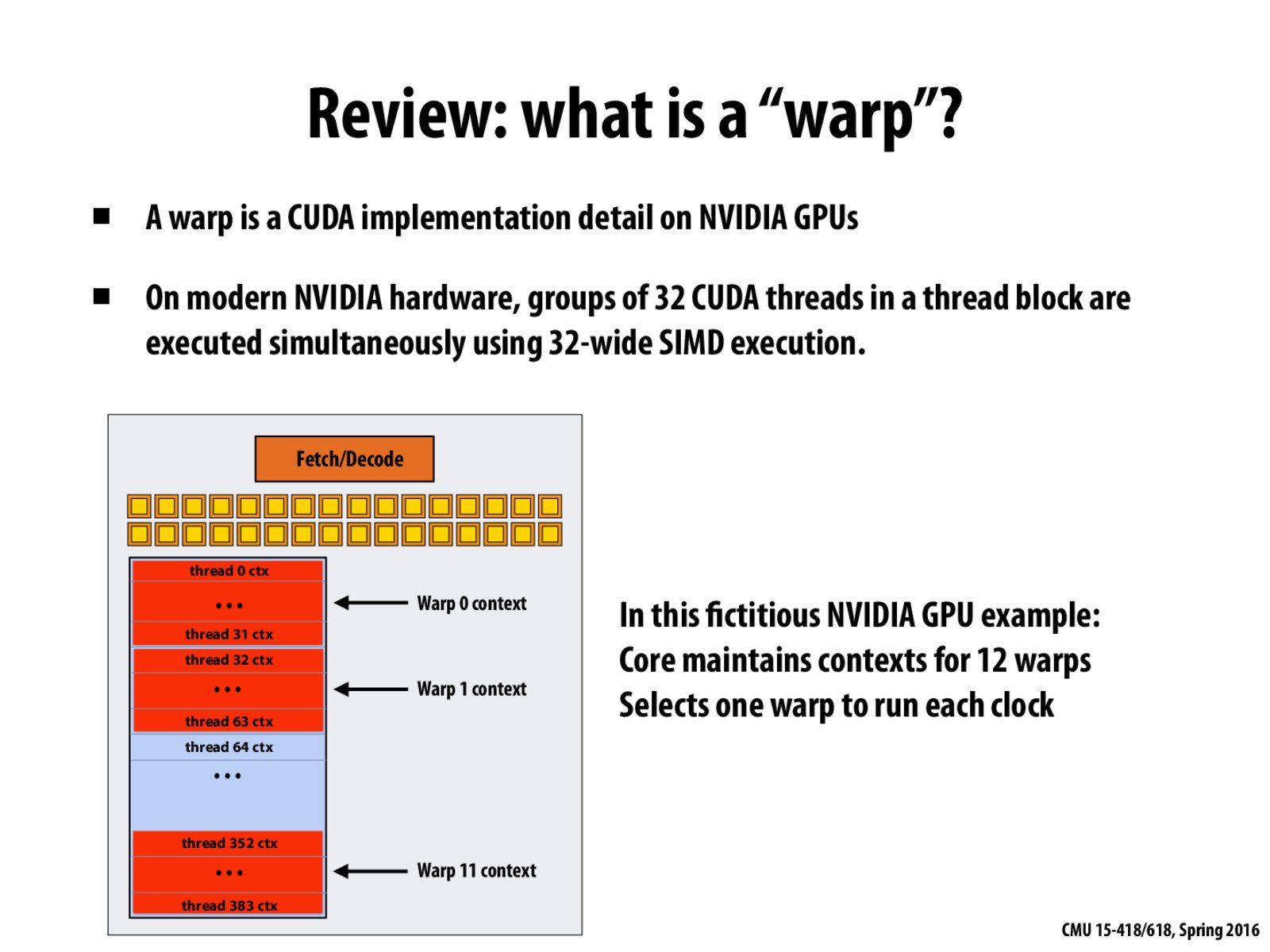
Since threads in the same block share the same warp context, do warps have anything to do with shared block memory?
Threads in the same block don't necessarily share the same warp context... Chances are several warps accommodate one block.
@Richard right. 32 threads in a warp, and these 32 threads get one warp context. If you have 64 threads in your thread block, you need two warp contexts for your entire thread block.
@eknight7 shared memory exists on thread block level not on the warp level. All threads in a thread block share a certain amount of shared memory. So several warps worth of CUDA threads share a certain amount of shared memory.
Another important thing to note is how much shared memory is available to each thread block. Looking back at this slide tells us that the more thread blocks you want to assign to one GPU core, the fewer bytes of shared memory each thread block can use. So if I had 1.5KB of shared memory on a GPU core and I wanted to put 5 thread blocks on that one core, I better make sure each thread block needs at most 0.3KB of shared memory.
While reading up on the Kepler multiprocessor, I found that there are a few limits on the numbers of thread blocks and warps per thread block (16 and 32, respectively). Why do these limits exist? This may prevent certain arrangements of thread blocks that may be needed to exploit concurrency and parallelism within a multiprocessor.
My intuition tells me that the reason behind limiting thread blocks and warps per block is that MOST workloads would not benefit from raising those numbers. It's a trade-off between how silicon is used, and they choose the arrangement which provides the most benefit for the most common workloads.