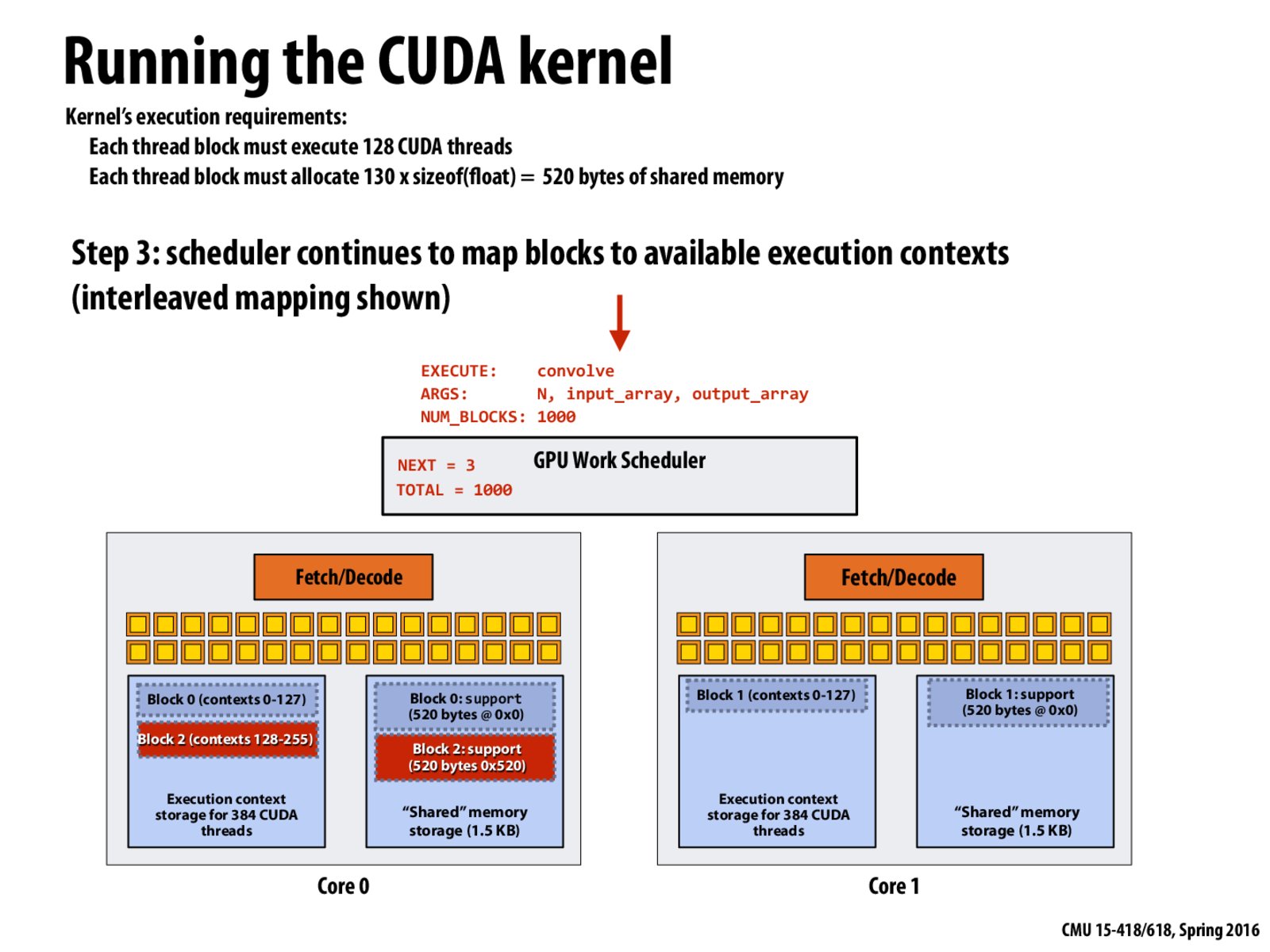
Just curious, what happens if we allocate a block size more than the context size, or what if we allocate larger shared memory than supported in a block? Would it fail us in compile time or until run time?
What if we just allocate a very small block size, say one thread per block, making it compatible on every GPU? I don't know, does it increase the burden of work scheduler?
RX
@misaka-10032
1.
I think it's ok to have more blocks than the # of contexts, because a block need to be put into execution contexts only when the scheduler choose to make it active, i.e. schedule it to run. Actually the NVDIA manual says you can have up to 65536 blocks, and I don't think it is related to available execution contexts.
For the shared memory question, according to this article, shared memory can be allocated dynamically at runtime or statically at compile time. So I guess it can report failure at both runtime and compile time depending on that.
2.
What do you mean by compatible?
I think threads in the block will run in a SIMD fashion, so that if you only have one thread per block, only one of the 32 "lanes" will be used and all others will be idle.
misaka-10032
@RX
1
To clarify, by block size, I mean #threads/block, not #blocks. The block (of threads) has to be put on the same core, right?
2
It's based my assumption in first question. By compatible, I mean even if the GPU has limited context size, a small block size can always fit into the context.
By 32 lanes, do you mean "warp" mentioned later?
These slides discuss the case where block size is greater than warp size, the block would be split into many warps. Here I'm just curious, if the block size is smaller than the warp size, will multiple blocks be fit into the same warp?
RX
@misaka-10032
There is a limit on # threads in a block. If you look at this specification, you can find that max. # threads per block is less than max. # resident threads per multiprocessor.
By lane I mean a computation unit (the yellow box), and I think multiple blocks can't fit into one warp. My reason is that there is only one shared memory per processor, if multiple blocks run execute together (because they are in the same warp so they run together), then the shared memory is actually shared across blocks. But we do know this is shared memory for a single block.
misaka-10032
@RX
Makes more sense, thanks.
You mean the computation units in GPU are also vectorized? I don't know, I thought the parallelism in GPU was because of warps (32 threads in a warp run in parallel). Also in the specification, it only mentions number of 32-bit registers, rather than vector registers like XMM. Are you sure the execution units will have lanes as those in CPU?
RX
@misaka-10032
Sorry I think I have caused confusions, I shouldn't have used lanes. What I mean is the computation units (the yellow boxes) will run together, and they will all get access to the shared memory. If these units are running different blocks, then we don't have a block shared memory instead we have a shared memory across blocks. So to preserve the semantics of block shared memory I will conclude different blocks can't run together within a warp.
Just curious, what happens if we allocate a block size more than the context size, or what if we allocate larger shared memory than supported in a block? Would it fail us in compile time or until run time?
What if we just allocate a very small block size, say one thread per block, making it compatible on every GPU? I don't know, does it increase the burden of work scheduler?
@misaka-10032
1.
I think it's ok to have more blocks than the # of contexts, because a block need to be put into execution contexts only when the scheduler choose to make it active, i.e. schedule it to run. Actually the NVDIA manual says you can have up to 65536 blocks, and I don't think it is related to available execution contexts.
For the shared memory question, according to this article, shared memory can be allocated dynamically at runtime or statically at compile time. So I guess it can report failure at both runtime and compile time depending on that.
2.
What do you mean by compatible? I think threads in the block will run in a SIMD fashion, so that if you only have one thread per block, only one of the 32 "lanes" will be used and all others will be idle.
@RX
1
To clarify, by block size, I mean #threads/block, not #blocks. The block (of threads) has to be put on the same core, right?
2
It's based my assumption in first question. By compatible, I mean even if the GPU has limited context size, a small block size can always fit into the context.
By 32 lanes, do you mean "warp" mentioned later?
These slides discuss the case where block size is greater than warp size, the block would be split into many warps. Here I'm just curious, if the block size is smaller than the warp size, will multiple blocks be fit into the same warp?
@misaka-10032
There is a limit on # threads in a block. If you look at this specification, you can find that max. # threads per block is less than max. # resident threads per multiprocessor.
By lane I mean a computation unit (the yellow box), and I think multiple blocks can't fit into one warp. My reason is that there is only one shared memory per processor, if multiple blocks run execute together (because they are in the same warp so they run together), then the shared memory is actually shared across blocks. But we do know this is shared memory for a single block.
@RX
@misaka-10032
@RX
Makes more sense, thanks!