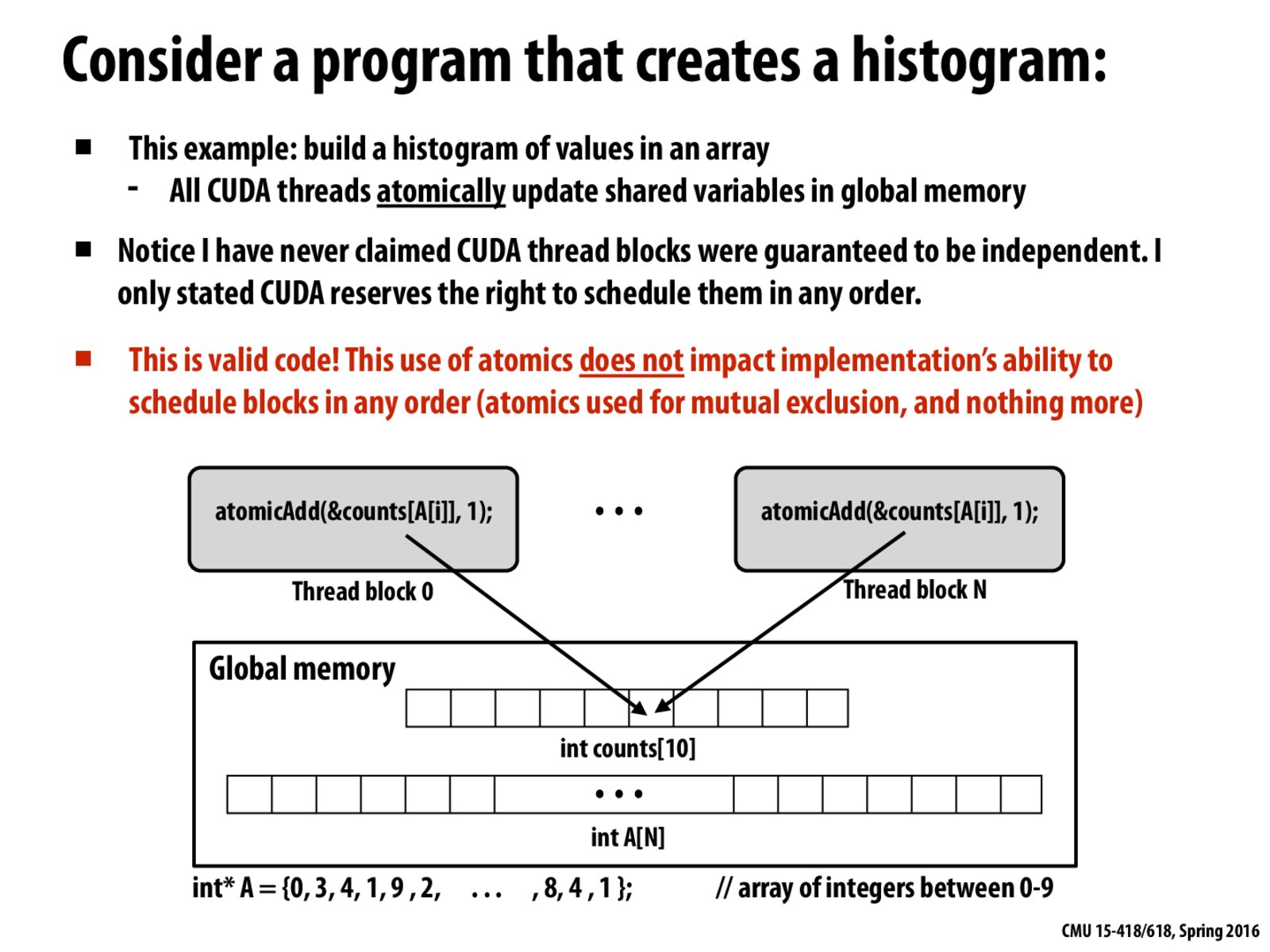
Is this valid code because it's just doing arithmetic addition? In general for this kind of code to be valid does the operation need to associative and commutative?
Lawliet
As long as the operation is order-independent (ie arithmetic addition) and the transactions that are being done are atomic (to avoid race conditions), then I don't see a reason that the operation should only be arithmetic.
0xc0ffee
I'm very confused about the second bullet point. I thought CUDA thread blocks were required to be independent.
Or is it this:
Thread block independence is assumed by CUDA, but not guaranteed. (eg, we have global memory). It's the programmer's responsibility to ensure that thread blocks are indeed independent.
xingdaz
@0xc0ffee, I think it is the second case.
kayvonf
@0xc0ffee, @xingdaz. You're hitting on exactly why I want everyone to think about this slide. CUDA reserves the right to schedule thread blocks in any order. If the thread blocks are independent then any execution order chosen by the system will certainly yield a correct program. But there's nothing stopping a CUDA programmer from writing code like the code on this slide, or code on the next slide. In case on this slide, the program will behave as desired regardless of ordering (why?). On the next slide, the correctness of the program (specifically, termination) depends on the order in which CUDA tries to run the thread blocks, and that's not a good thing!
illuminated
For any index j in counts the overall operation performed is (((counts[j] + 1) + 1) ... + 1) where we add 1 for each time j appears in A. This overall sum is independent for each j, and also independent of the ordering when A[i] == A[i']. So we can schedule the threads in any order.
patrickbot
In addition, addition is commutative so order of the arithmetic operation itself doesn't matter. If the operation were not commutative, even if each thread block is independent, because CUDA can decide the order, this code would not be correct.
jhibshma
@patrickbot, I believe that's true. We also need that addition is associative. Commutativity alone tells us that (A+B)+C = (B+A)+C, but we also need associativity to get that (A+B)+C = A+(B+C) = A+(C+B) = (A+C)+B.
CaptainBlueBear
The atomic add is also crucial for the correctness of the program on this slide. Without the atomic add we might encounter a race condition that would cause us to get the wrong result. For example, Thread 1 (in block 1) might read count = 10 and, at the same time, Thread 2 (in block 2) also reads count = 10. Thread 1 then adds 5 to count and writes count = 15. Thread 2 then adds 3 to count after Thread 1's write then writes count = 13. Now count = 13 though the correct value should be count = 18.
doodooloo
I know thread blocks do not need to be independent. I want to make sure threads in the same block must be independent, right? (since thread block provides a SIMD abstraction)?
Hil
@doodooloo,
According to This slide it is possible to create dependencies between threads in a block.
Is this valid code because it's just doing arithmetic addition? In general for this kind of code to be valid does the operation need to associative and commutative?
As long as the operation is order-independent (ie arithmetic addition) and the transactions that are being done are atomic (to avoid race conditions), then I don't see a reason that the operation should only be arithmetic.
I'm very confused about the second bullet point. I thought CUDA thread blocks were required to be independent.
Or is it this:
Thread block independence is assumed by CUDA, but not guaranteed. (eg, we have global memory). It's the programmer's responsibility to ensure that thread blocks are indeed independent.
@0xc0ffee, I think it is the second case.
@0xc0ffee, @xingdaz. You're hitting on exactly why I want everyone to think about this slide. CUDA reserves the right to schedule thread blocks in any order. If the thread blocks are independent then any execution order chosen by the system will certainly yield a correct program. But there's nothing stopping a CUDA programmer from writing code like the code on this slide, or code on the next slide. In case on this slide, the program will behave as desired regardless of ordering (why?). On the next slide, the correctness of the program (specifically, termination) depends on the order in which CUDA tries to run the thread blocks, and that's not a good thing!
For any index j in counts the overall operation performed is (((counts[j] + 1) + 1) ... + 1) where we add 1 for each time j appears in A. This overall sum is independent for each j, and also independent of the ordering when A[i] == A[i']. So we can schedule the threads in any order.
In addition, addition is commutative so order of the arithmetic operation itself doesn't matter. If the operation were not commutative, even if each thread block is independent, because CUDA can decide the order, this code would not be correct.
@patrickbot, I believe that's true. We also need that addition is associative. Commutativity alone tells us that (A+B)+C = (B+A)+C, but we also need associativity to get that (A+B)+C = A+(B+C) = A+(C+B) = (A+C)+B.
The atomic add is also crucial for the correctness of the program on this slide. Without the atomic add we might encounter a race condition that would cause us to get the wrong result. For example, Thread 1 (in block 1) might read count = 10 and, at the same time, Thread 2 (in block 2) also reads count = 10. Thread 1 then adds 5 to count and writes count = 15. Thread 2 then adds 3 to count after Thread 1's write then writes count = 13. Now count = 13 though the correct value should be count = 18.
I know thread blocks do not need to be independent. I want to make sure threads in the same block must be independent, right? (since thread block provides a SIMD abstraction)?
@doodooloo, According to This slide it is possible to create dependencies between threads in a block.