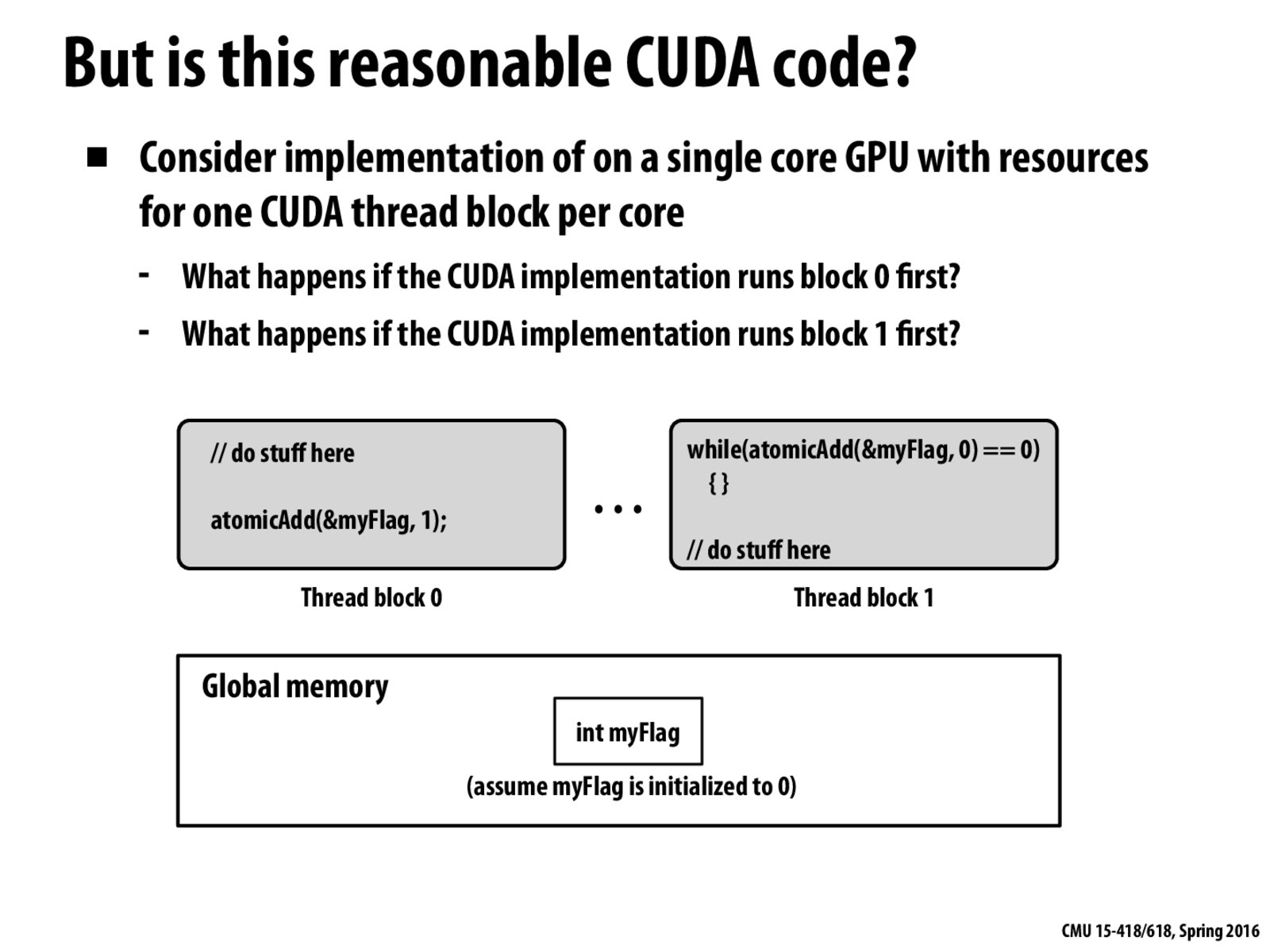
Assuming that atomicAdd(&myFlag;, x) returns the value of myFlag after the add.
Since different blocks will run sequentially when we have a single core GPU, if block 0 runs first, then everything is fine, because myFlag would be set to 1 and block 1 won't "block" (hang).
However, if block 1 ran first, myFlag is 0 and it will only be set to 1 after block 0 is ran. So block 1 won't be able to continue and the GPU will be in an infinite while loop waiting for myFlag to be set to 1.
Is my understanding correct? Why do we need atomicAdd in block 1 code? Is it the same as while(myFlag == 0) ?
Khryl
If the CUDA implementation runs block 0 first, everything works out fine. Because thread block 0 will update myFlag to 1 and terminate. Then thread block 1 will be scheduled onto the core. Because the while statement is false, it will break right away.
However, if the CUDA implementation runs block 1 first, thread block 1 will get stuck because the while statement is always true. Thus, the core is always occupied and thread block 0 won't get the chance to update myFlag to 1, which causes a deadlock.
krillfish
^ I think for the second part, you meant if block 1 runs first? If block 0 runs first, then myFlag will be updated, and the while loop will never be entered. If block 1 runs first, the while loop will never terminate.
365sleeping
Since CUDA reserves the right to run blocks in any order, I believe this code is invalid.
trappedin418
Let's say we could run both blocks at the same time (we still have no guarantee on order), technically this would be valid code right? There would be little/no advantage to running the code this way because the code is essentially sequential (block 0 -> block 1).
Does this example generalize? Is it generally a bad idea to have dependencies between thread blocks? Would it be better to use syncthreads to deal with dependencies rather than locks?
monkeyking
@jerryzh I think the reason for using atomicAdd instead of myFlag == 0 is to illustrate that this code is valid but not reasonable. Since previous slide shows why two atomicAdd is valid, this slide shows why this is not a good way.
kayvonf
Yes, I wrote the code this way for two reasons:
Symmetry with the example in the last slide.
But also because (for reasons we haven't discussed in class) I need to use an atomic primitive to make sure the latest value of myFlag is picked up. GPUs don't support cache coherence... a topic I'll leave for a few lectures down the line.
yikesaiting
One thing I want to write here is that CUDA will not change a block before the current running block is done. However, within a block with several warps, GPU can do ILP to switch between warps.
kayvonf
@yikesaiting. Interleaved multi-threading of warps on a GPU (or of hyper-threads on a CPU) is not an optimization that exploits ILP in an instruction stream. And can someone help me by pointing out what this is true?
365sleeping
@kayvonf ILP is finding the potential parallelism in an instruction stream, and execute those instructions simultaneously. While warps on a GPU will have separate instruction streams, and the GPU may issue several instructions, one from each stream and to the corresponding warp, at one time.
qqkk
CUDA core chooses one block and keeps working until the block is finished, which is not interleaved fashion. Therefore, if second block is chosen, the core will running forever in the for loop.
Assuming that
atomicAdd(&myFlag;, x)returns the value of myFlag after the add.Since different blocks will run sequentially when we have a single core GPU, if block 0 runs first, then everything is fine, because myFlag would be set to 1 and block 1 won't "block" (hang). However, if block 1 ran first, myFlag is 0 and it will only be set to 1 after block 0 is ran. So block 1 won't be able to continue and the GPU will be in an infinite while loop waiting for myFlag to be set to 1.
Is my understanding correct? Why do we need
atomicAddin block 1 code? Is it the same aswhile(myFlag == 0)?If the CUDA implementation runs block 0 first, everything works out fine. Because thread block 0 will update myFlag to 1 and terminate. Then thread block 1 will be scheduled onto the core. Because the while statement is false, it will break right away.
However, if the CUDA implementation runs block 1 first, thread block 1 will get stuck because the while statement is always true. Thus, the core is always occupied and thread block 0 won't get the chance to update myFlag to 1, which causes a deadlock.
^ I think for the second part, you meant if block 1 runs first? If block 0 runs first, then
myFlagwill be updated, and the while loop will never be entered. If block 1 runs first, the while loop will never terminate.Since CUDA reserves the right to run blocks in any order, I believe this code is invalid.
Let's say we could run both blocks at the same time (we still have no guarantee on order), technically this would be valid code right? There would be little/no advantage to running the code this way because the code is essentially sequential (block 0 -> block 1).
Does this example generalize? Is it generally a bad idea to have dependencies between thread blocks? Would it be better to use syncthreads to deal with dependencies rather than locks?
@jerryzh I think the reason for using
atomicAddinstead ofmyFlag == 0is to illustrate that this code is valid but not reasonable. Since previous slide shows why twoatomicAddis valid, this slide shows why this is not a good way.Yes, I wrote the code this way for two reasons:
myFlagis picked up. GPUs don't support cache coherence... a topic I'll leave for a few lectures down the line.One thing I want to write here is that CUDA will not change a block before the current running block is done. However, within a block with several warps, GPU can do ILP to switch between warps.
@yikesaiting. Interleaved multi-threading of warps on a GPU (or of hyper-threads on a CPU) is not an optimization that exploits ILP in an instruction stream. And can someone help me by pointing out what this is true?
@kayvonf ILP is finding the potential parallelism in an instruction stream, and execute those instructions simultaneously. While warps on a GPU will have separate instruction streams, and the GPU may issue several instructions, one from each stream and to the corresponding warp, at one time.
CUDA core chooses one block and keeps working until the block is finished, which is not interleaved fashion. Therefore, if second block is chosen, the core will running forever in the for loop.