I understand that this version of the sin(x) function is preferred over the second version because as Kayvon pointed in lecture it has better spatial locality since at any given time the different program instances are going to be accessing contiguous memory and so this version would be much more cache efficient. Apart from not having a cache, would there by any circumstances under which version 2 might perform faster?
Lawliet
A simple answer off the top of my head is version 2 would be faster if you change up your cache accesses, i.e, you perform some function on the index before looking into the cache. Aside from accessing your cache weirdly, I can't see a circumstance either though.
zvonryan
I guess in situation like lecture 2 slide 34, when not all ALUs are doing useful work, version 2 might have a better time locality and outperform version 1.
totofufu
So this version of sin(x) is better than the version in the next slide due to spatial locality (since all the accessed memory blocks at a time are contiguous). Suppose the size of each index in the array is 4 bytes, and we cache 16 bytes at once. This means that in this version, we should hypothetically get one miss per time block since we should have one instance missing but caching the memory block as a result. Contrast this to the version in the next slide. Wouldn't the version in the next slide have 4 cache misses in the first time block and no misses in any of the other time blocks (due to caching the corresponding memory blocks)? Am I making incorrect assumptions here?
stee
@totofufu Caching also depends on the number of blocks that can be cached at the same time. If the cache can only cache 16 bytes (a 4x4 bytes block), for example, then in the second version, depending on the order of the memory blocks retrieved, you can end up with 4 cache misses in every time block.
totofufu
@stee Right, so the only assumptions we can't make here are the size of blocks that are cached together at the same time, as well as the cache size. With those assumptions though, is it possible that both versions could actually having the same performance?
xiaoguaz
@zvonryan But I think version 1 will outperform version 2 in general situation if we do not know the efficiency of ALU. Am I right?
trappedin418
I can think of another fairly "stupid" way to make interleaved slower than blocked (without thinking about caching). Suppose every 0 mod 4 indexed job takes a very long time and the other jobs finish quickly (note: this obviously requires changing the program). Then interleaved will result in highly unbalanced work whereas blocked will conveniently be well-balanced.
Of course, this is a fairly contrived example. The way I see it, whether you are programming in parallel or not, you should always follow the golden cache rule: memory close together should be accessed together.
Araina
I agree with @trappedin418 about the golden cache rule. And I think it is the responsibility of a programmer to choose interleaved or blocked assignment depend on the exact scenario, which contains the exact program and the CPU architecture.
teamG
when I was reading this slide initially, I couldn't think of a scenario where interleaving would be worse blocking. Working on assignment 1 made me think that in most cases, it might be better to use interleaving than blocking. But as the others have said, it really depends on the situation. I guess one good example is actually provided in the next lecture, in the 2d grid example here.
tdecker
I think a lot of these optimizations become dependent on the situation. This is why we can get such amazing speed ups for specific application code
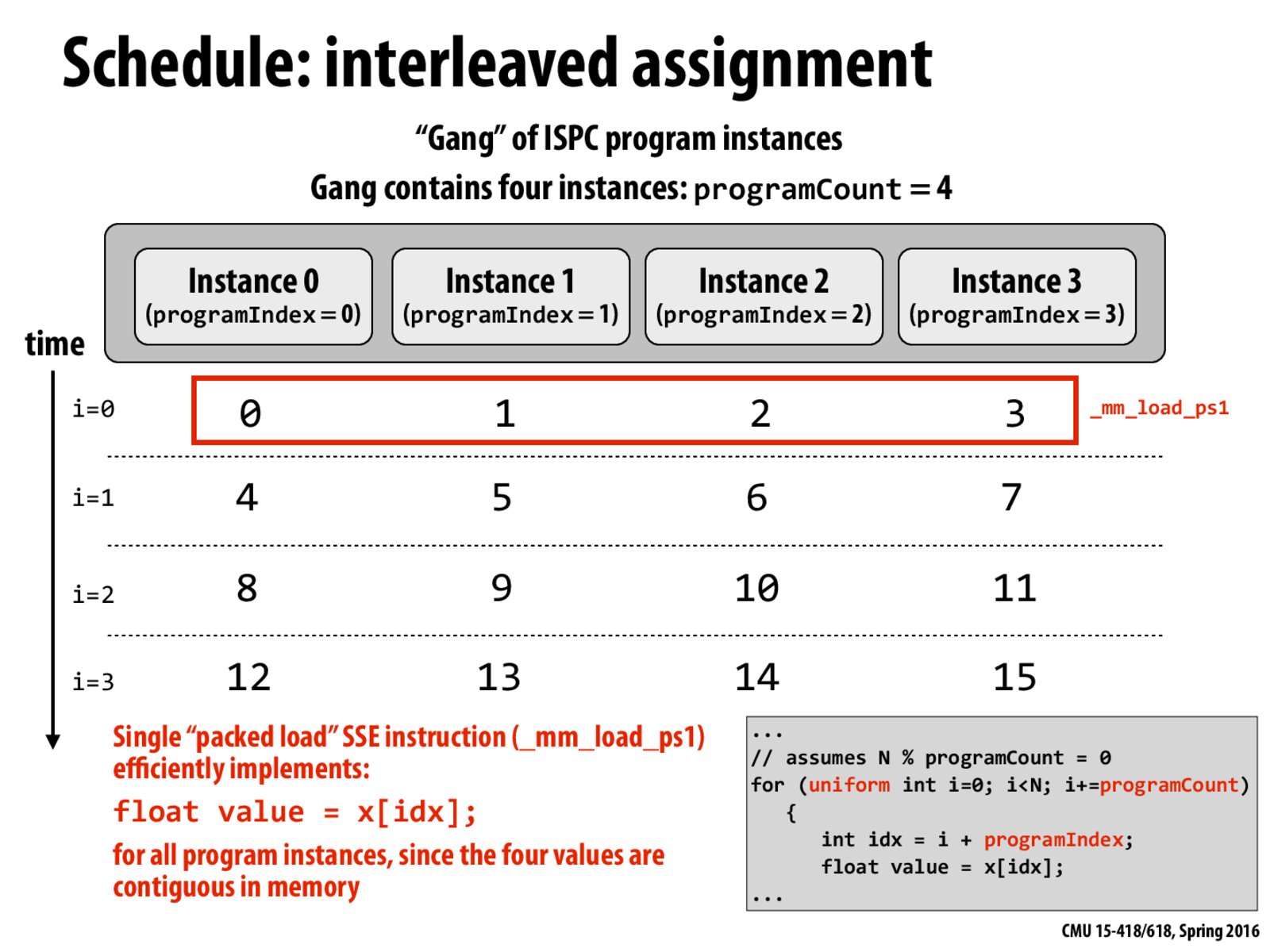
I understand that this version of the sin(x) function is preferred over the second version because as Kayvon pointed in lecture it has better spatial locality since at any given time the different program instances are going to be accessing contiguous memory and so this version would be much more cache efficient. Apart from not having a cache, would there by any circumstances under which version 2 might perform faster?
A simple answer off the top of my head is version 2 would be faster if you change up your cache accesses, i.e, you perform some function on the index before looking into the cache. Aside from accessing your cache weirdly, I can't see a circumstance either though.
I guess in situation like lecture 2 slide 34, when not all ALUs are doing useful work, version 2 might have a better time locality and outperform version 1.
So this version of sin(x) is better than the version in the next slide due to spatial locality (since all the accessed memory blocks at a time are contiguous). Suppose the size of each index in the array is 4 bytes, and we cache 16 bytes at once. This means that in this version, we should hypothetically get one miss per time block since we should have one instance missing but caching the memory block as a result. Contrast this to the version in the next slide. Wouldn't the version in the next slide have 4 cache misses in the first time block and no misses in any of the other time blocks (due to caching the corresponding memory blocks)? Am I making incorrect assumptions here?
@totofufu Caching also depends on the number of blocks that can be cached at the same time. If the cache can only cache 16 bytes (a 4x4 bytes block), for example, then in the second version, depending on the order of the memory blocks retrieved, you can end up with 4 cache misses in every time block.
@stee Right, so the only assumptions we can't make here are the size of blocks that are cached together at the same time, as well as the cache size. With those assumptions though, is it possible that both versions could actually having the same performance?
@zvonryan But I think version 1 will outperform version 2 in general situation if we do not know the efficiency of ALU. Am I right?
I can think of another fairly "stupid" way to make interleaved slower than blocked (without thinking about caching). Suppose every 0 mod 4 indexed job takes a very long time and the other jobs finish quickly (note: this obviously requires changing the program). Then interleaved will result in highly unbalanced work whereas blocked will conveniently be well-balanced.
Of course, this is a fairly contrived example. The way I see it, whether you are programming in parallel or not, you should always follow the golden cache rule: memory close together should be accessed together.
I agree with @trappedin418 about the golden cache rule. And I think it is the responsibility of a programmer to choose interleaved or blocked assignment depend on the exact scenario, which contains the exact program and the CPU architecture.
when I was reading this slide initially, I couldn't think of a scenario where interleaving would be worse blocking. Working on assignment 1 made me think that in most cases, it might be better to use interleaving than blocking. But as the others have said, it really depends on the situation. I guess one good example is actually provided in the next lecture, in the 2d grid example here.
I think a lot of these optimizations become dependent on the situation. This is why we can get such amazing speed ups for specific application code