What this diagram shows is that the process of pipelining of sending a bunch of messages over the network. There're 3 kinds of overhead during the message sending. Instead of sending in a synchronous way, we can keep the processor busy (e.g. putting the next message in the network buffer to send next) while the first message is not completely sent out.
Notice that the processor is busy all the time until it finishes processing the 4th message. Suppose the buffer has limited capacity and can only hold 2 messages at most, which is why the processor has to wait until a message in the buffer is picked up and sent out.
The reason for this slow down is that the whole process is limited by the slowest component in the link. No matter how big the buffer is, the processor has to wait when it's full. Another example is the dryer (takes 1 hour, longer than other steps) in the laundry example, which limits the throughput of the entire pipelining process.
mperron
To add to what @haibinl said, as I understand it, the main reason for doing this is that we expect burstiness in our applications. If we expected workloads with consistently high throughput (more than the slowest link can handle) there would be little benefit to buffering because the throughput would be the same as if there was no buffer. If traffic, is bursty, the buffer allows us to keep the processor (or some other resource) busy until the burst is over and the cache is cleared.
eknight7
Key insight: Increasing buffer size may not always increase throughput.
PandaX
The throughput in pipelining system is determined by the slowest component.
ppwwyyxx
There is a lot of pipeline stages in a processor today. Probably because by making each stage smaller, the slowest component won't become such a severe bottleneck.
bpr
Oddly enough @ppwwyyxx, the number of pipeline stages in more recent processors has been decreasing following the shift away from increasing processor frequency. In hardware, each pipeline stage requires additional logic to latch the values before the next stage, thus smaller stages have a higher percentage of "staging" logic (i.e., overhead). Furthermore, when branch prediction mispredicts, the pipeline has to be flushed, and so longer pipelines take more cycles to fill. Now, depending on your definition, there may still be "a lot" of pipeline stages in current architectures.
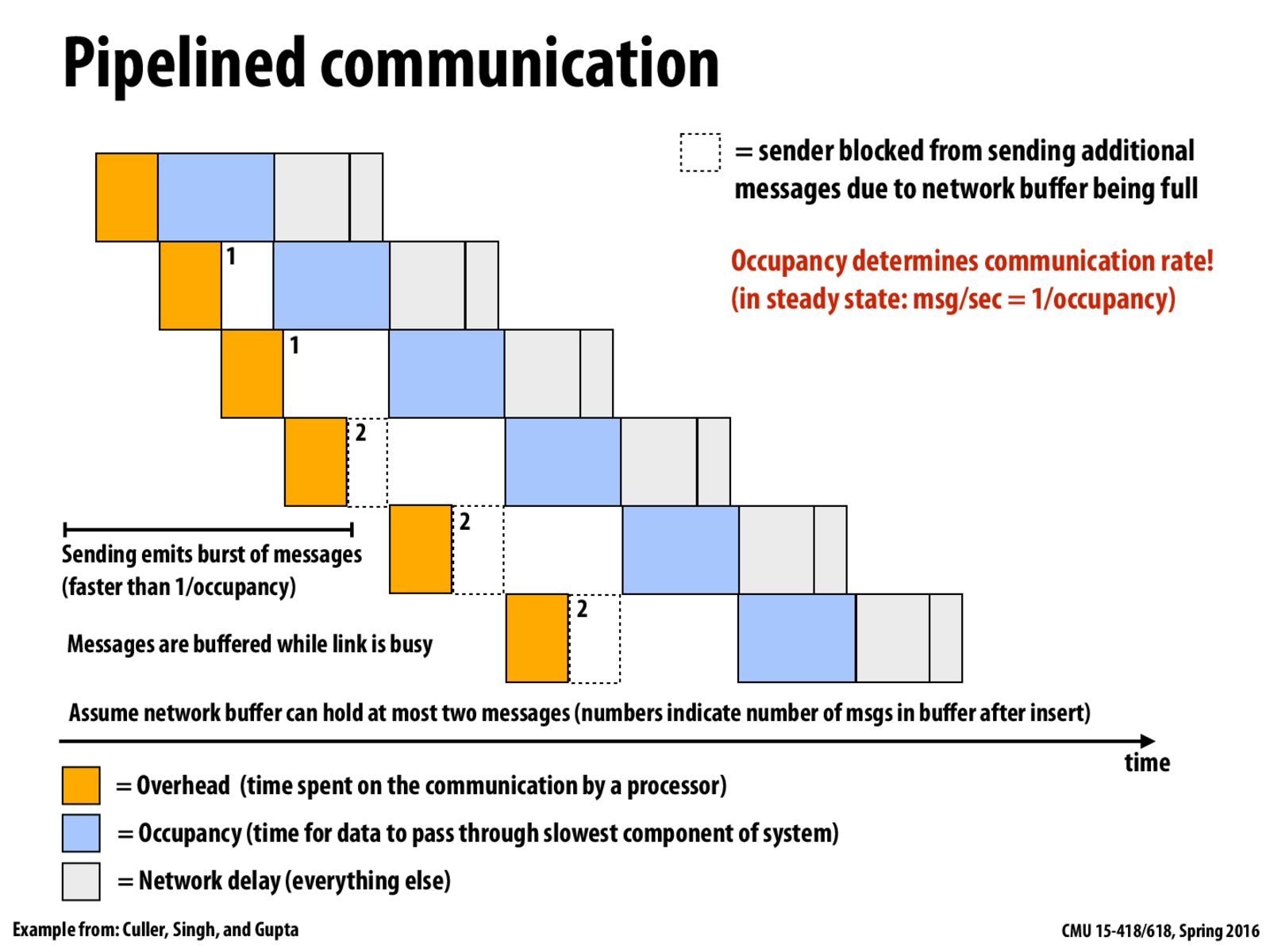
What this diagram shows is that the process of pipelining of sending a bunch of messages over the network. There're 3 kinds of overhead during the message sending. Instead of sending in a synchronous way, we can keep the processor busy (e.g. putting the next message in the network buffer to send next) while the first message is not completely sent out.
Notice that the processor is busy all the time until it finishes processing the 4th message. Suppose the buffer has limited capacity and can only hold 2 messages at most, which is why the processor has to wait until a message in the buffer is picked up and sent out.
The reason for this slow down is that the whole process is limited by the slowest component in the link. No matter how big the buffer is, the processor has to wait when it's full. Another example is the dryer (takes 1 hour, longer than other steps) in the laundry example, which limits the throughput of the entire pipelining process.
To add to what @haibinl said, as I understand it, the main reason for doing this is that we expect burstiness in our applications. If we expected workloads with consistently high throughput (more than the slowest link can handle) there would be little benefit to buffering because the throughput would be the same as if there was no buffer. If traffic, is bursty, the buffer allows us to keep the processor (or some other resource) busy until the burst is over and the cache is cleared.
Key insight: Increasing buffer size may not always increase throughput.
The throughput in pipelining system is determined by the slowest component.
There is a lot of pipeline stages in a processor today. Probably because by making each stage smaller, the slowest component won't become such a severe bottleneck.
Oddly enough @ppwwyyxx, the number of pipeline stages in more recent processors has been decreasing following the shift away from increasing processor frequency. In hardware, each pipeline stage requires additional logic to latch the values before the next stage, thus smaller stages have a higher percentage of "staging" logic (i.e., overhead). Furthermore, when branch prediction mispredicts, the pipeline has to be flushed, and so longer pipelines take more cycles to fill. Now, depending on your definition, there may still be "a lot" of pipeline stages in current architectures.