Is it possible for a value to be in the E state and not be clean? If so, what situation would lead to that?
huehue
Is the only benefit of having the E state the fact that we can easily move to the modified state if no other processor has that cache line in it's own cache? Because if another processor is reading from that cache line too, then the situation would be the same as in MSI.
Khryl
@huehue, I think so. The only benefit seems to be if there is no sharing between processors, which happens in a lot of cases, the cache controller can move from E state to M state without sending BusRdX signal.
Fantasy
Although we do not have to broadcast when moving from E to M in MESI, we need to receive acknowledgement of "having / not having this data in cache" from all other processors when we send BusRd in state I. So how can this be more efficient than MSI protocol? Is it because knowing if all other processors has the data costs less than broadcasting to all other processors? Thanks!
Dracula08MS
I wonder how does cache controller implemented? Is it done in a hardware level? Or there is some kind of software controls it?
jhibshma
@Dracula, I believe it is implemented in hardware. Software is generally oblivious to the existence of a cache. In this case, speed is of the essence, and the task is highly specialized, so hardware is a good option.
@Fantasy, I was wondering the same thing. However, I noticed that both the transition to the shared state and the transition to the exclusive state are shown sending a BusRd signal, so this would imply that a signal across the memory system is indeed used. -- If it's not used, why is the signal sent?
yimmyz
This diagram seems rather daunting to me, with all of the transitions on it. Do we need to actually memorize this diagram itself, or is the point to understand how cache controllers cooperate in this snooping-based protocol?
CaptainBlueBear
I have the same question as @Fantasy. If we need to receive messages from other processors about whether they have the data in the cache or not to be able to move into the Exclusive state, how is MESI more efficient that MSI in terms of broadcasts on the interconnect?
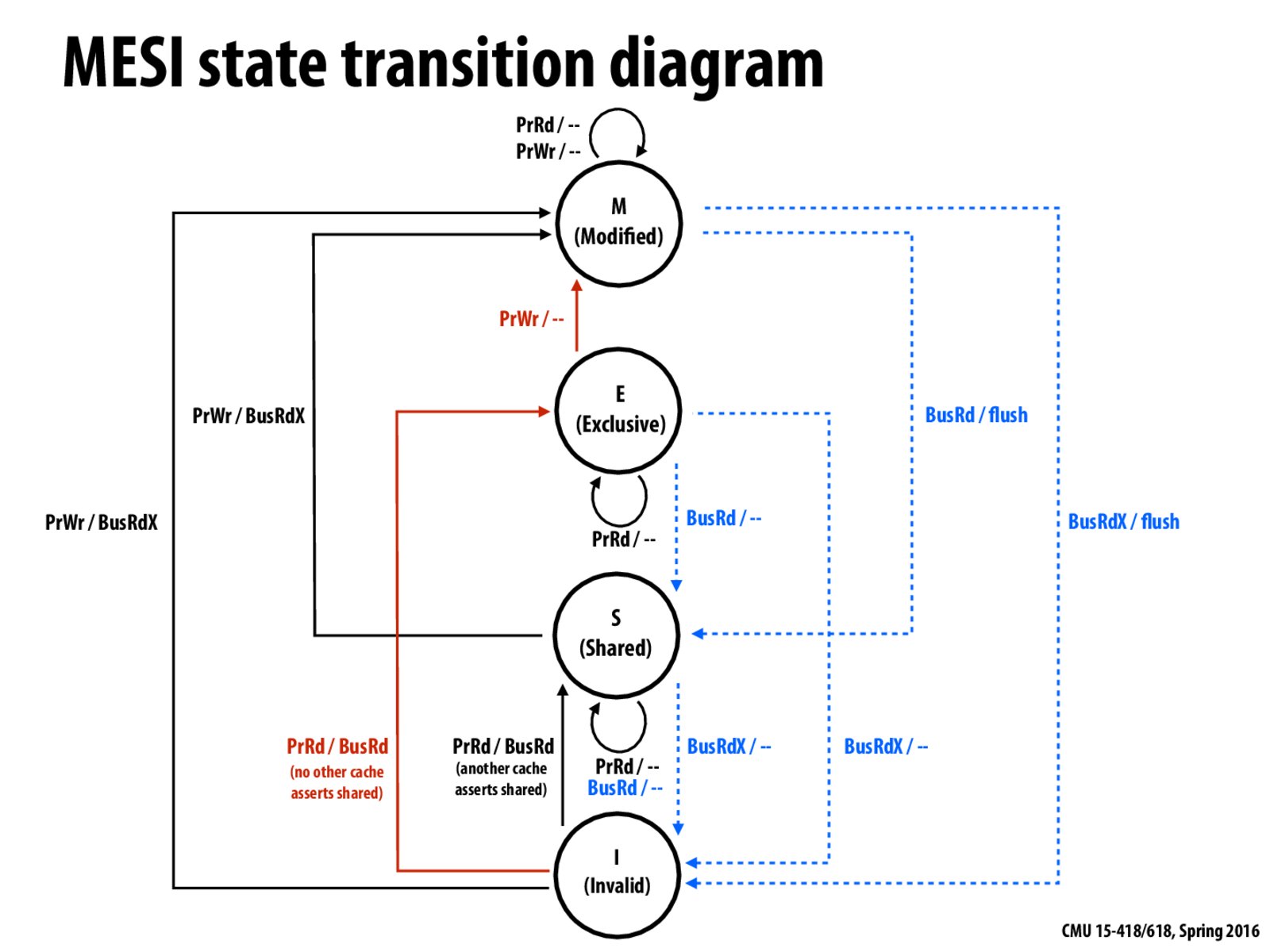
Is it possible for a value to be in the E state and not be clean? If so, what situation would lead to that?
Is the only benefit of having the E state the fact that we can easily move to the modified state if no other processor has that cache line in it's own cache? Because if another processor is reading from that cache line too, then the situation would be the same as in MSI.
@huehue, I think so. The only benefit seems to be if there is no sharing between processors, which happens in a lot of cases, the cache controller can move from E state to M state without sending BusRdX signal.
Although we do not have to broadcast when moving from E to M in MESI, we need to receive acknowledgement of "having / not having this data in cache" from all other processors when we send BusRd in state I. So how can this be more efficient than MSI protocol? Is it because knowing if all other processors has the data costs less than broadcasting to all other processors? Thanks!
I wonder how does cache controller implemented? Is it done in a hardware level? Or there is some kind of software controls it?
@Dracula, I believe it is implemented in hardware. Software is generally oblivious to the existence of a cache. In this case, speed is of the essence, and the task is highly specialized, so hardware is a good option.
@Fantasy, I was wondering the same thing. However, I noticed that both the transition to the shared state and the transition to the exclusive state are shown sending a BusRd signal, so this would imply that a signal across the memory system is indeed used. -- If it's not used, why is the signal sent?
This diagram seems rather daunting to me, with all of the transitions on it. Do we need to actually memorize this diagram itself, or is the point to understand how cache controllers cooperate in this snooping-based protocol?
I have the same question as @Fantasy. If we need to receive messages from other processors about whether they have the data in the cache or not to be able to move into the Exclusive state, how is MESI more efficient that MSI in terms of broadcasts on the interconnect?