Question: In your own words, what is the role of a queue in a parallel system?
pavelkang
Assume B works on things processed by A in the previous stage. If B is really slow and A really fast, then A has to idle wait B. Think of A being the person who cuts vegetables and B the chef who cooks them. A, when finished cutting one serving, has to wait for the chef to finish. Instead, A can use a large bow (a queue), to hold the vegetables so that they can both work at full speed.
PIC
It would be interesting to seem a theorem about the expected rate if you make assumptions about the distribution of the work. Intuitively it seems like you would want the size of the queue to be a factor of the variance of those distributions.
Can this not be related to pipelining? By introducing a queue between A and B I am allowing A to work on new task while the next stage B picks up its own new task from the queue. The requirement that both A and B on an average work at the same rate in my opinion is similar to the washer-dryer example. It'd be ideal to have both washer and dryer take same amount of time to complete otherwise there will be stalls because the intermediate queue will fill up.
ojd
@PIC: You can actually determine the average size of the queue as a function of the two average rates. The variance will be useful for other properties, though.
Edit: Ah, no, I just remembered that that determines something else. You're right, the queue size can depend on the distribution. Perhaps the best way to view it is to think about a 1 dimensional Markov chain of infinite length where you have two events: go down n on task dequeue of n tasks and up n on enqueue of n tasks.
ojd
@sasthana: Sure. Queues essentially allow us to desynchronize the action of making work available from the action of receiving work, while preserving the ordering of events. This is exactly the principle pipelining relies on: we have the instruction fetch units making instructions available, but they don't need to wait for the previous instructions to complete before fetching a new one, so pipelining removes the false dependency.
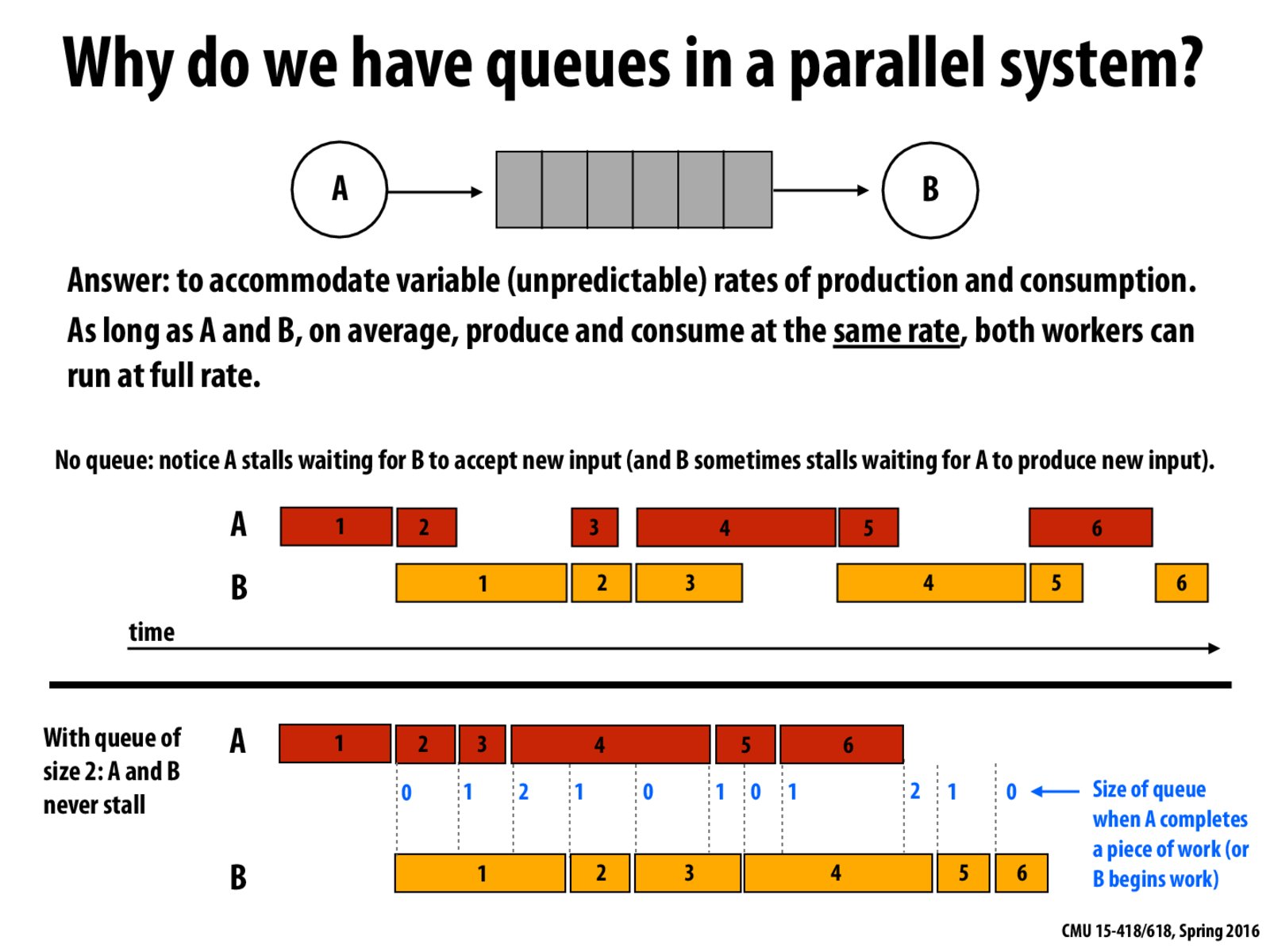
Question: In your own words, what is the role of a queue in a parallel system?
Assume B works on things processed by A in the previous stage. If B is really slow and A really fast, then A has to idle wait B. Think of A being the person who cuts vegetables and B the chef who cooks them. A, when finished cutting one serving, has to wait for the chef to finish. Instead, A can use a large bow (a queue), to hold the vegetables so that they can both work at full speed.
It would be interesting to seem a theorem about the expected rate if you make assumptions about the distribution of the work. Intuitively it seems like you would want the size of the queue to be a factor of the variance of those distributions.
@PIC. You'd be interested in this class and this book.
Can this not be related to pipelining? By introducing a queue between A and B I am allowing A to work on new task while the next stage B picks up its own new task from the queue. The requirement that both A and B on an average work at the same rate in my opinion is similar to the washer-dryer example. It'd be ideal to have both washer and dryer take same amount of time to complete otherwise there will be stalls because the intermediate queue will fill up.
@PIC: You can actually determine the average size of the queue as a function of the two average rates. The variance will be useful for other properties, though.
Edit: Ah, no, I just remembered that that determines something else. You're right, the queue size can depend on the distribution. Perhaps the best way to view it is to think about a 1 dimensional Markov chain of infinite length where you have two events: go down n on task dequeue of n tasks and up n on enqueue of n tasks.
@sasthana: Sure. Queues essentially allow us to desynchronize the action of making work available from the action of receiving work, while preserving the ordering of events. This is exactly the principle pipelining relies on: we have the instruction fetch units making instructions available, but they don't need to wait for the previous instructions to complete before fetching a new one, so pipelining removes the false dependency.