There are two reasonable ideas proposed here for the scheduling policy when applying the mapper function to each line in the file. The first idea involves creating a standard work queue, implementing a dynamic assignment of work to worker nodes. However, this approach doesn't leverage the locality of the file system. Thus, the second idea suggests that lines in the file should be processed by nodes that have that data stored locally. The tradeoff we see between these two scheduling policies is a matter of better locality vs better work distribution.
CaptainBlueBear
Idea 2 guarantees us better locality because each node is working with blocks of the input file that are stored locally. However, we might have bad work distribution if the blocks stored on each node aren't divided evenly.
Idea 1 guarantees better work distribution (since the nodes have a work queue to pull work from as they become free). However, we'll probably have bad locality since nodes will be pulling work that's not necessarily stored locally.
cyl
If we can distribute the logs to blocks evenly when writing, it would be perfect for idea2, though the overhead is to "distribute" the data. In this case, just add a simple counter of number of logs on each node would be enough.
It's like maintaining a balanced tree during insertion so we can find the data faster.
qqkk
Idea 1 is more suitable in single-master, multiple-slaves nodes structure so that server node can handle the single work queue and allocate work to other nodes. However in this context, data blocks are evenly distributed to all the nodes and there's no assigned server node. It would be more wise to make use of the data locality to avoid the overhead of scheduling and data transfer.
Perpendicular
These ideas are really similar to the openMP scheduling policies that we tried out in the assignment. Idea 1 is really similar to dynamic while idea 2 to static.
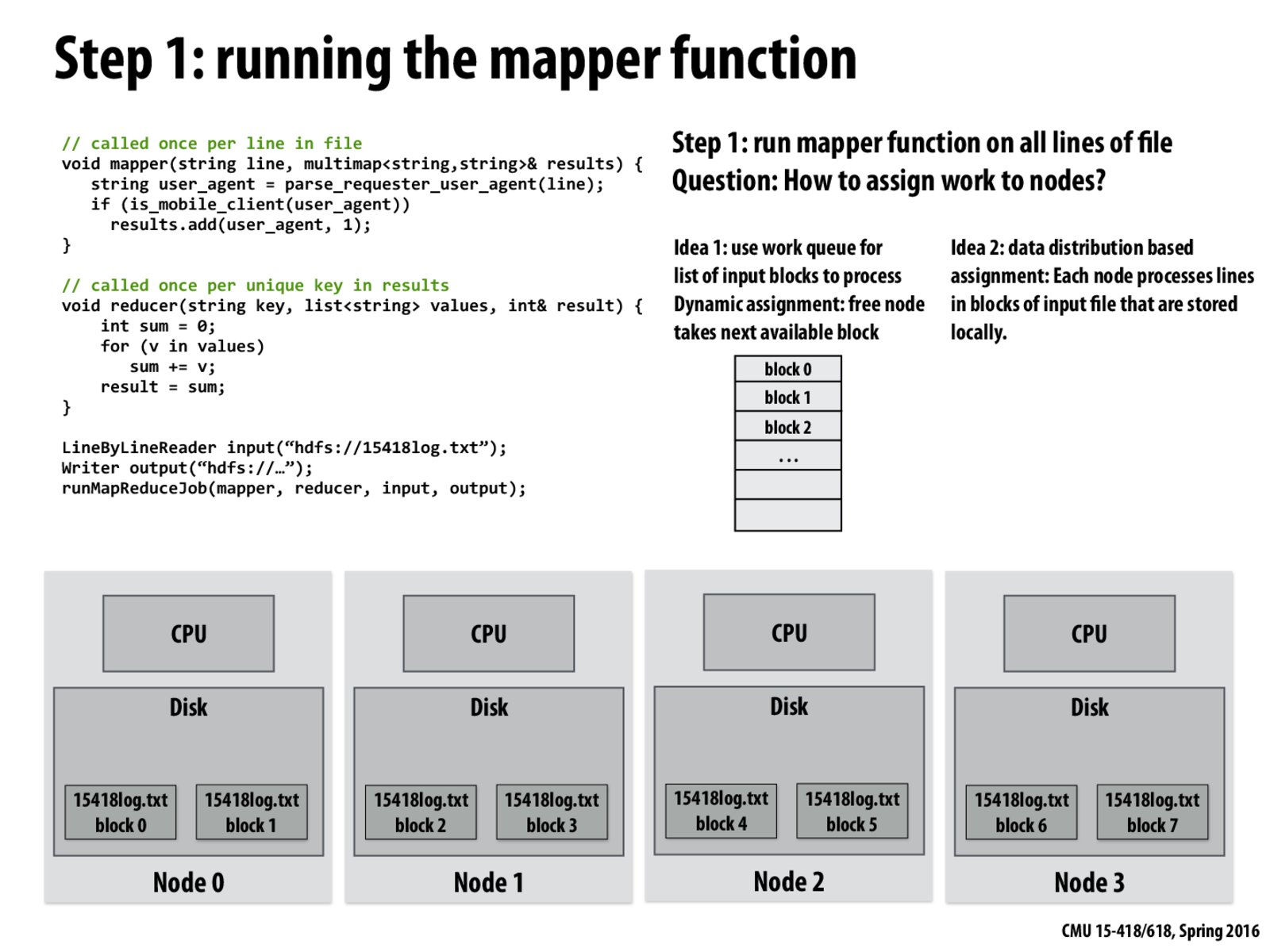
There are two reasonable ideas proposed here for the scheduling policy when applying the
mapperfunction to each line in the file. The first idea involves creating a standard work queue, implementing a dynamic assignment of work to worker nodes. However, this approach doesn't leverage the locality of the file system. Thus, the second idea suggests that lines in the file should be processed by nodes that have that data stored locally. The tradeoff we see between these two scheduling policies is a matter of better locality vs better work distribution.Idea 2 guarantees us better locality because each node is working with blocks of the input file that are stored locally. However, we might have bad work distribution if the blocks stored on each node aren't divided evenly.
Idea 1 guarantees better work distribution (since the nodes have a work queue to pull work from as they become free). However, we'll probably have bad locality since nodes will be pulling work that's not necessarily stored locally.
If we can distribute the logs to blocks evenly when writing, it would be perfect for idea2, though the overhead is to "distribute" the data. In this case, just add a simple counter of number of logs on each node would be enough.
It's like maintaining a balanced tree during insertion so we can find the data faster.
Idea 1 is more suitable in single-master, multiple-slaves nodes structure so that server node can handle the single work queue and allocate work to other nodes. However in this context, data blocks are evenly distributed to all the nodes and there's no assigned server node. It would be more wise to make use of the data locality to avoid the overhead of scheduling and data transfer.
These ideas are really similar to the openMP scheduling policies that we tried out in the assignment. Idea 1 is really similar to dynamic while idea 2 to static.