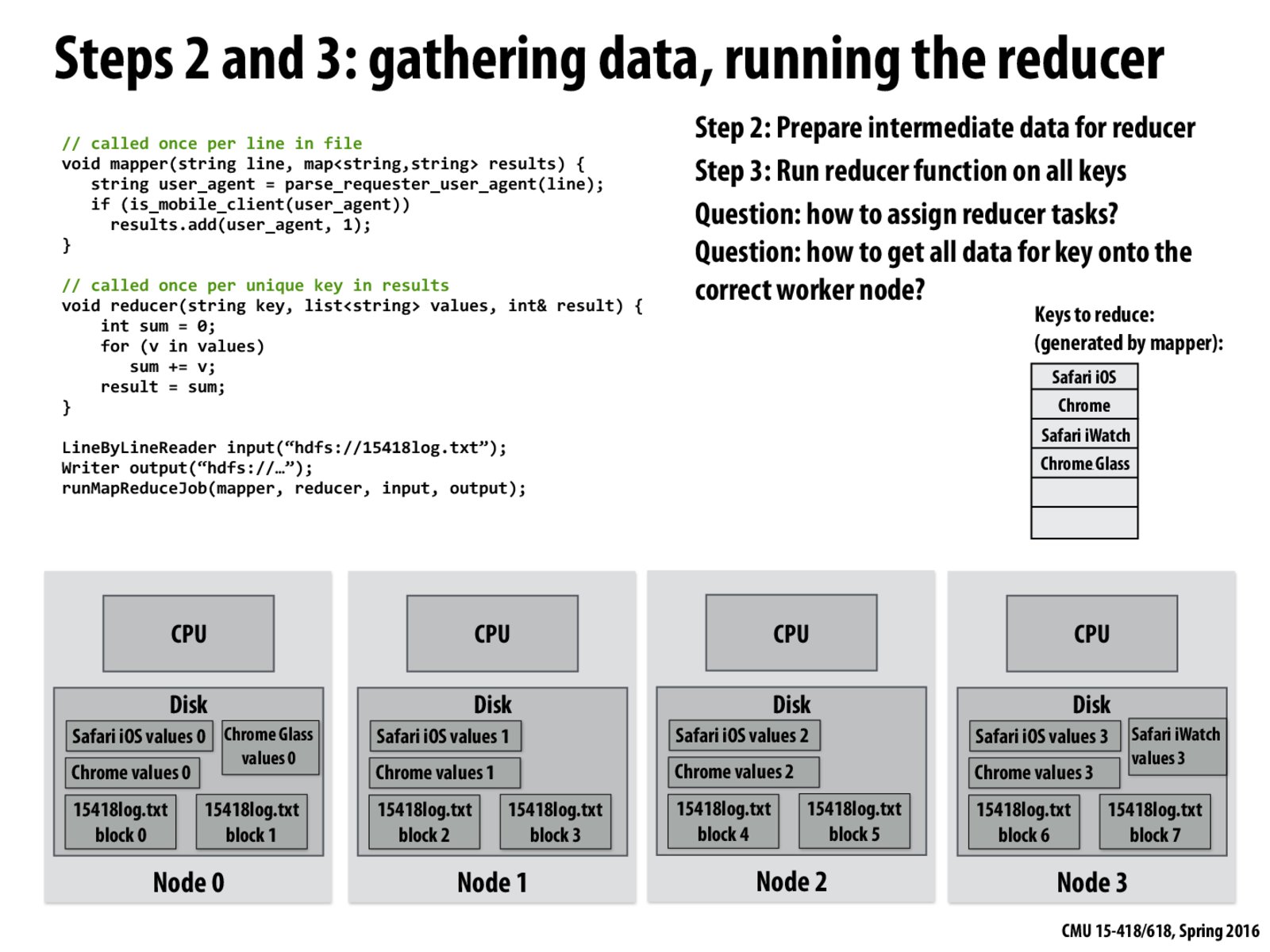
The output of mapper is stored in the locally disk. They are distributed based on the hashing key of each output. The distribution can be very unbalanced. As a result, it is a programmer's responsibility to make the distribution better. Then the output of reducer are stored on hdfs directly.
totofufu
It normally might make sense to just go with a scheduling system where each node, once empty, works on the next reduction on keys from the queue. However, this doesn't account for locality that we could take advantage of in order to speed things up. So it's actually a better idea to try and group keys together based on how well the performance would be with caching, as specified in the above post.
maxdecmeridius
This is all under the assumption that the set of keys is known by every node, so the job scheduler can partition the set and give each node a set of keys to reduce.
How might we implement a solution for figuring out the set of keys when the set is very large, let's say too large to fit onto a single node's disk?
hofstee
@maxdecmeridius Since this is all going through the file system at this point in the lecture, as long as you can fit the set of keys in the file system you should be okay. It would just be very, very, very slow.
c0d3r
I'm confused why we can't have each node run reduce on its set of keys, then schedule some nodes to gather the keys and reduce over the reduced values (i.e. all nodes compute a partial result for Safari iOS, then node 0 reduces over the partial results). I know that reduce should only be called once per key, but in this case calling it multiple times might be more efficient since we can take advantage of locality.
hofstee
@c0d3r one of the guarantees that we were given is we would have all the data before beginning an operation on it. That would violate this guarantee. Nothing preventing you from restructuring your computation to achieve something similar though. We talked a bit about this in lecture, you might want to check out the recorded video.
As far as I know:
The output of mapper is stored in the locally disk. They are distributed based on the hashing key of each output. The distribution can be very unbalanced. As a result, it is a programmer's responsibility to make the distribution better. Then the output of reducer are stored on hdfs directly.
It normally might make sense to just go with a scheduling system where each node, once empty, works on the next reduction on keys from the queue. However, this doesn't account for locality that we could take advantage of in order to speed things up. So it's actually a better idea to try and group keys together based on how well the performance would be with caching, as specified in the above post.
This is all under the assumption that the set of keys is known by every node, so the job scheduler can partition the set and give each node a set of keys to reduce.
How might we implement a solution for figuring out the set of keys when the set is very large, let's say too large to fit onto a single node's disk?
@maxdecmeridius Since this is all going through the file system at this point in the lecture, as long as you can fit the set of keys in the file system you should be okay. It would just be very, very, very slow.
I'm confused why we can't have each node run reduce on its set of keys, then schedule some nodes to gather the keys and reduce over the reduced values (i.e. all nodes compute a partial result for Safari iOS, then node 0 reduces over the partial results). I know that reduce should only be called once per key, but in this case calling it multiple times might be more efficient since we can take advantage of locality.
@c0d3r one of the guarantees that we were given is we would have all the data before beginning an operation on it. That would violate this guarantee. Nothing preventing you from restructuring your computation to achieve something similar though. We talked a bit about this in lecture, you might want to check out the recorded video.