In this example, we can no longer use the streaming model. We need to compute all of RDD_A and also keep it in memory until we finish computing RDD_B.
kayvonf
Question: Can someone explain why this slide says, "must compute all of RDD_A before computing any elements of RDD_B?" A clear explanation might use an explain to explain what this scheduling constraint is necessary for correct execution.
haibinl
The interface of .groupByKey() is RDD[(K,V)] => RDD[(K, Seq[V])], which returns a sequence of values for each key. Each part of RDD_B has dependency on all of the RDD_A parts. Suppose part 0 of RDD_B is responsible for key_0, then it has to combine all values from all RDD_A parts whose key is key_0 before returning the result. Computing RDD_B has to be scheduled after RDD_A is completed due to the semantic of groupByKey(), because any of RDD_A's result could contain a value of key_0, and RDD_B has to collect all values of that key before returning, otherwise the sequence returned is not correct.
It's worth noticing that such scheduling constraint indicates that RDD_B has to maintain the temporary sequence results before returning to the client, and the temporary sequence could be large. It also means that if there's an straggler among RDD_A computations, RDD_B has to wait for that extremely slow straggler to complete before returning to next level of execution. Therefore, it makes sense to use partitionBy() to reduce the scheduling synchronization overhead(see next slide)
kayvonf
@haibinl. Outstanding comment.
cyl
In this case, maybe we can preprocess RDD_A first (i.e. do some sorting on the key) or using different partition scheme to narrow the dependency as shown in the following slides.
RX
To answer Kayvon's question in short: because ANY element of B relies on ALL elements of A
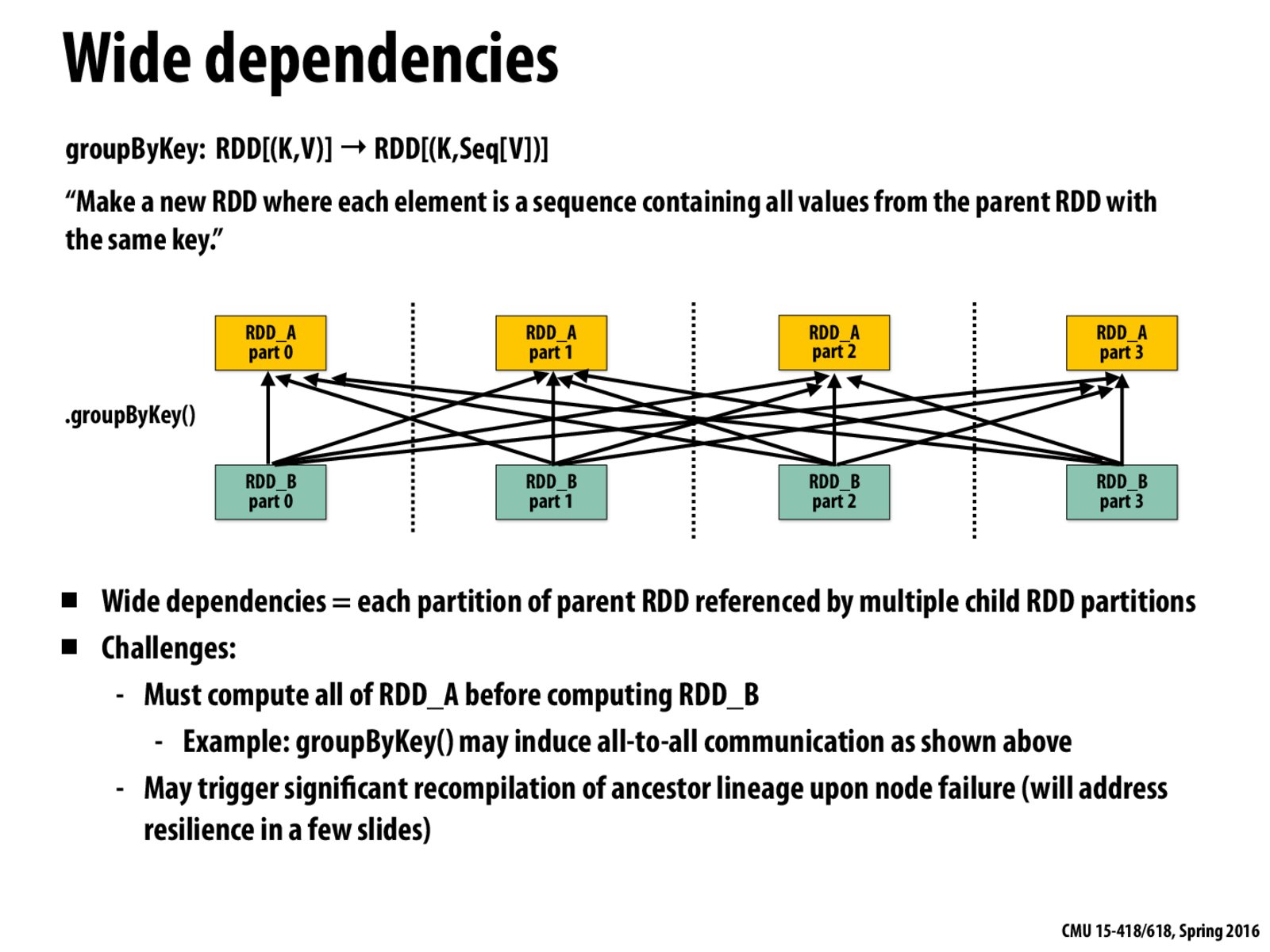
In this example, we can no longer use the streaming model. We need to compute all of RDD_A and also keep it in memory until we finish computing RDD_B.
Question: Can someone explain why this slide says, "must compute all of RDD_A before computing any elements of RDD_B?" A clear explanation might use an explain to explain what this scheduling constraint is necessary for correct execution.
The interface of .groupByKey() is RDD[(K,V)] => RDD[(K, Seq[V])], which returns a sequence of values for each key. Each part of RDD_B has dependency on all of the RDD_A parts. Suppose part 0 of RDD_B is responsible for key_0, then it has to combine all values from all RDD_A parts whose key is key_0 before returning the result. Computing RDD_B has to be scheduled after RDD_A is completed due to the semantic of groupByKey(), because any of RDD_A's result could contain a value of key_0, and RDD_B has to collect all values of that key before returning, otherwise the sequence returned is not correct.
It's worth noticing that such scheduling constraint indicates that RDD_B has to maintain the temporary sequence results before returning to the client, and the temporary sequence could be large. It also means that if there's an straggler among RDD_A computations, RDD_B has to wait for that extremely slow straggler to complete before returning to next level of execution. Therefore, it makes sense to use partitionBy() to reduce the scheduling synchronization overhead(see next slide)
@haibinl. Outstanding comment.
In this case, maybe we can preprocess RDD_A first (i.e. do some sorting on the key) or using different partition scheme to narrow the dependency as shown in the following slides.
To answer Kayvon's question in short: because ANY element of B relies on ALL elements of A