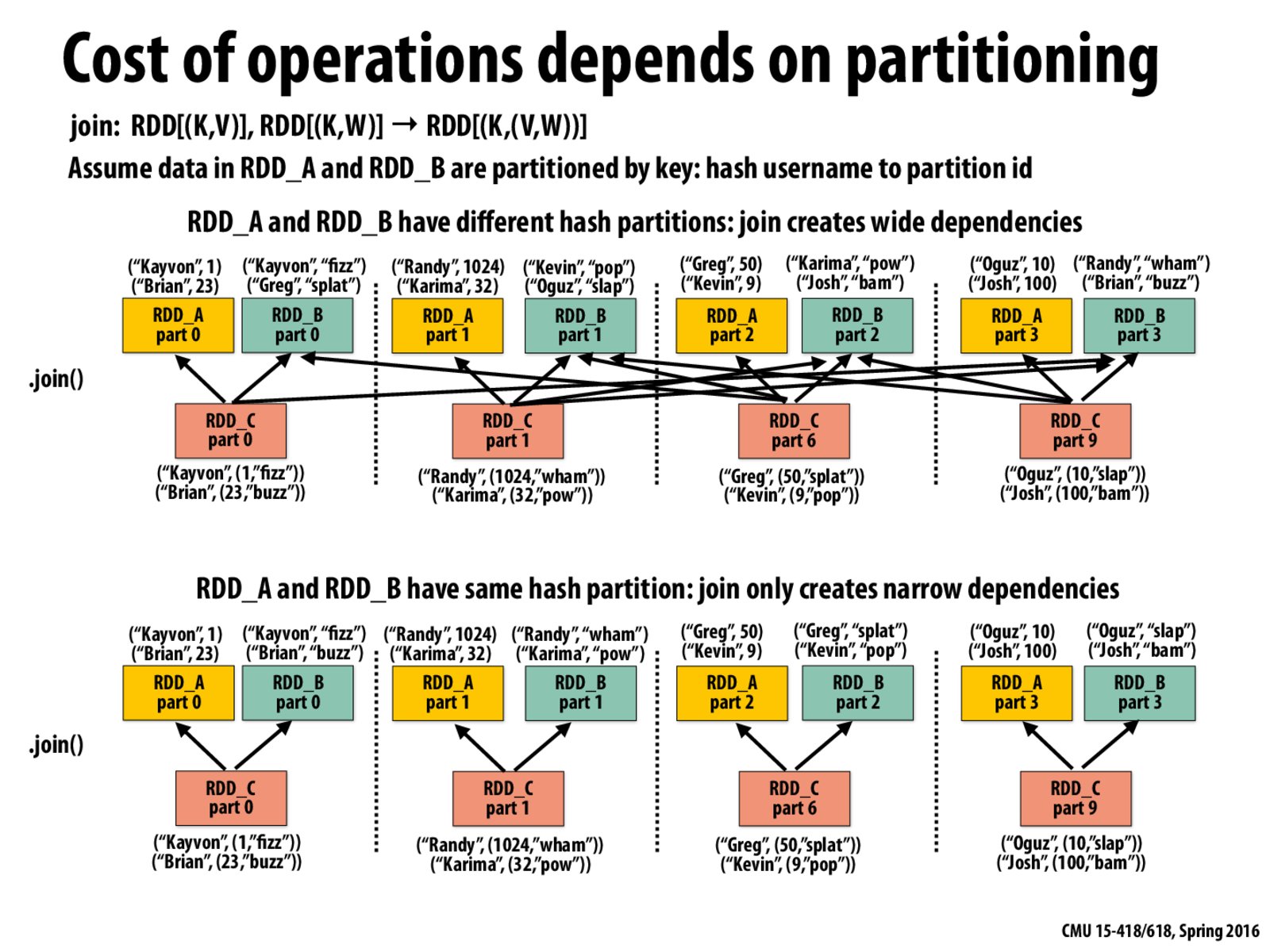
I'm not completely sure what this slide is trying to show. Could someone please explain? It seems like the first part of this image has a wide dependence, but the one in second part has a narrow dependency. How did we achieve this?
mperron
@fleventyfive, I think the point of this slide is that the way we partition data onto nodes has an impact on the cost of certain operations. That is if we partition the RDD_A and RDD_B on the same key, then we reduce the cost of transferring data all over the place when we do a Join. This has implication for the both the speed and resource (network) usage of our application.
RX
Pre-partition data when doing join operations is actually a typical strategy used in database systems. When doing a join on two tables, the tables could be optionally partitioned based on the join keys. Ideally each partition of the two tables can be fit into cache, and it is enough to do partition based join, which is more cache friendly, instead of record(tuple) based join. The partition idea in Spark is similar to that used in DBMS - exploit locality by partition
I'm not completely sure what this slide is trying to show. Could someone please explain? It seems like the first part of this image has a wide dependence, but the one in second part has a narrow dependency. How did we achieve this?
@fleventyfive, I think the point of this slide is that the way we partition data onto nodes has an impact on the cost of certain operations. That is if we partition the RDD_A and RDD_B on the same key, then we reduce the cost of transferring data all over the place when we do a Join. This has implication for the both the speed and resource (network) usage of our application.
Pre-partition data when doing join operations is actually a typical strategy used in database systems. When doing a join on two tables, the tables could be optionally partitioned based on the join keys. Ideally each partition of the two tables can be fit into cache, and it is enough to do partition based join, which is more cache friendly, instead of record(tuple) based join. The partition idea in Spark is similar to that used in DBMS - exploit locality by partition