What kayvon said from lecture about the takeaway from this slide is that in cases when there is a many to many relationship, where some partitions are being used multiple times. For example, in this case, different parts of RDD_F are used multiple times. So it is a good idea to probably to store these on disk so that when we compute for RDD_G, we don't have to recompute those parts that we need multiple times.
cyl
@teamG
In which case we need to recompute RDD_F?
If we need RDD_F, isn't that faster to load RDD_F from memory?
xingdaz
I a lot of ways, Spark is similar to Halide. In Halide, you set up the pipeline and define the algorithm and schedule. Nothing really happens until you call realize(). The Halide system takes the compilation work from you. In spark, you set up pipeline and don't really need to setup scheduling (since Spark scheduler does it for you and analyse the dependency), and nothing happens until you call save().
patrickbot
@cyl teamG is saying RDD_F is one of the things we (the scheduler or the program writer) choose to materialize because it is used a lot. In constrast, we don't choose to materialize RDD_D because it is only used once in computing RDD_F.
I'm not sure where the original RDD is for this dependency graph... where is the original, on-disk data? (and how do RDD_A, RDD_C, RDD_E interact with it? Do we care, since the original on-disk data is stored anyway?)
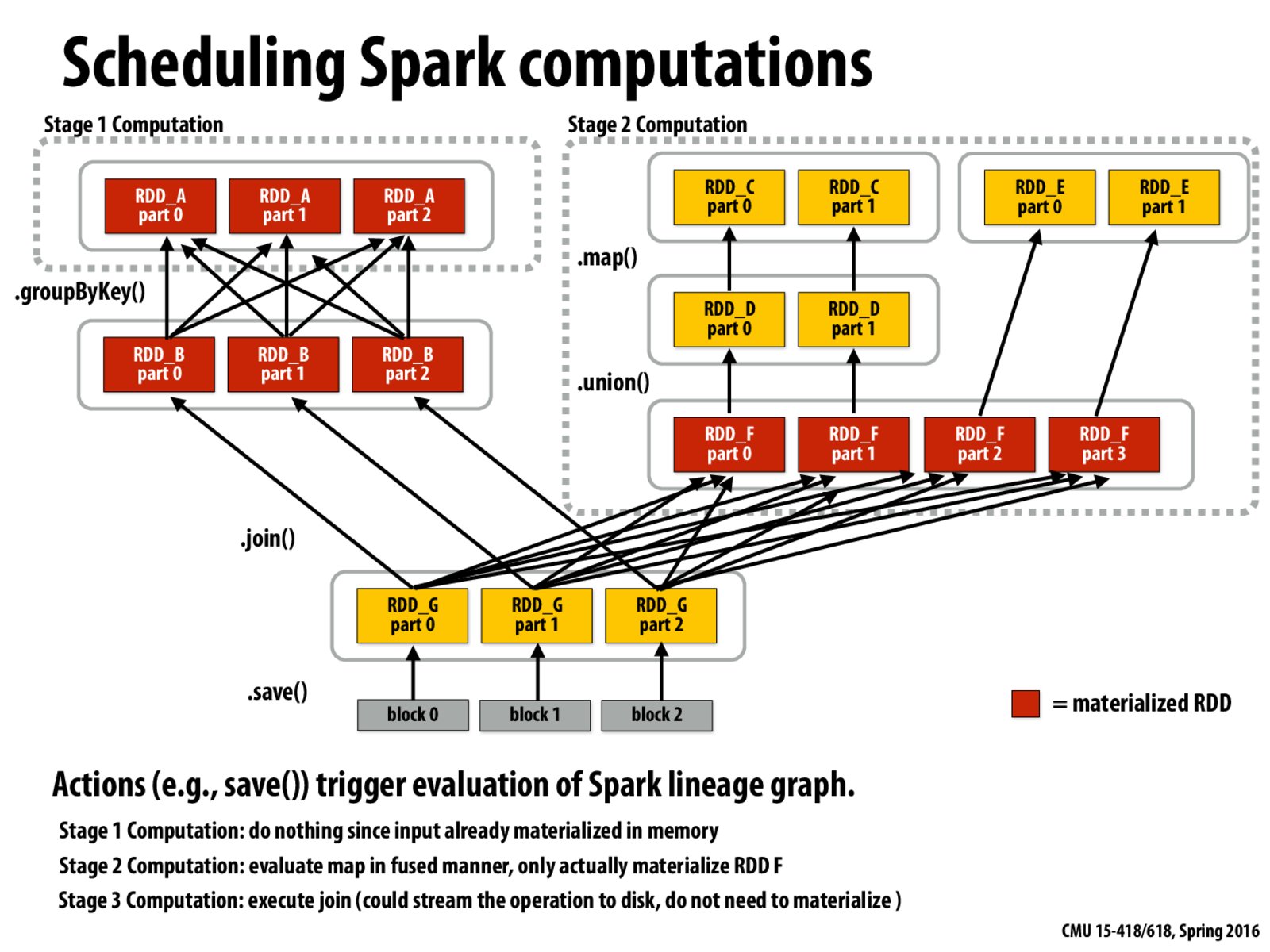
What kayvon said from lecture about the takeaway from this slide is that in cases when there is a many to many relationship, where some partitions are being used multiple times. For example, in this case, different parts of RDD_F are used multiple times. So it is a good idea to probably to store these on disk so that when we compute for RDD_G, we don't have to recompute those parts that we need multiple times.
@teamG In which case we need to recompute RDD_F? If we need RDD_F, isn't that faster to load RDD_F from memory?
I a lot of ways, Spark is similar to Halide. In Halide, you set up the pipeline and define the algorithm and schedule. Nothing really happens until you call realize(). The Halide system takes the compilation work from you. In spark, you set up pipeline and don't really need to setup scheduling (since Spark scheduler does it for you and analyse the dependency), and nothing happens until you call save().
@cyl teamG is saying RDD_F is one of the things we (the scheduler or the program writer) choose to materialize because it is used a lot. In constrast, we don't choose to materialize RDD_D because it is only used once in computing RDD_F.
I'm not sure where the original RDD is for this dependency graph... where is the original, on-disk data? (and how do RDD_A, RDD_C, RDD_E interact with it? Do we care, since the original on-disk data is stored anyway?)