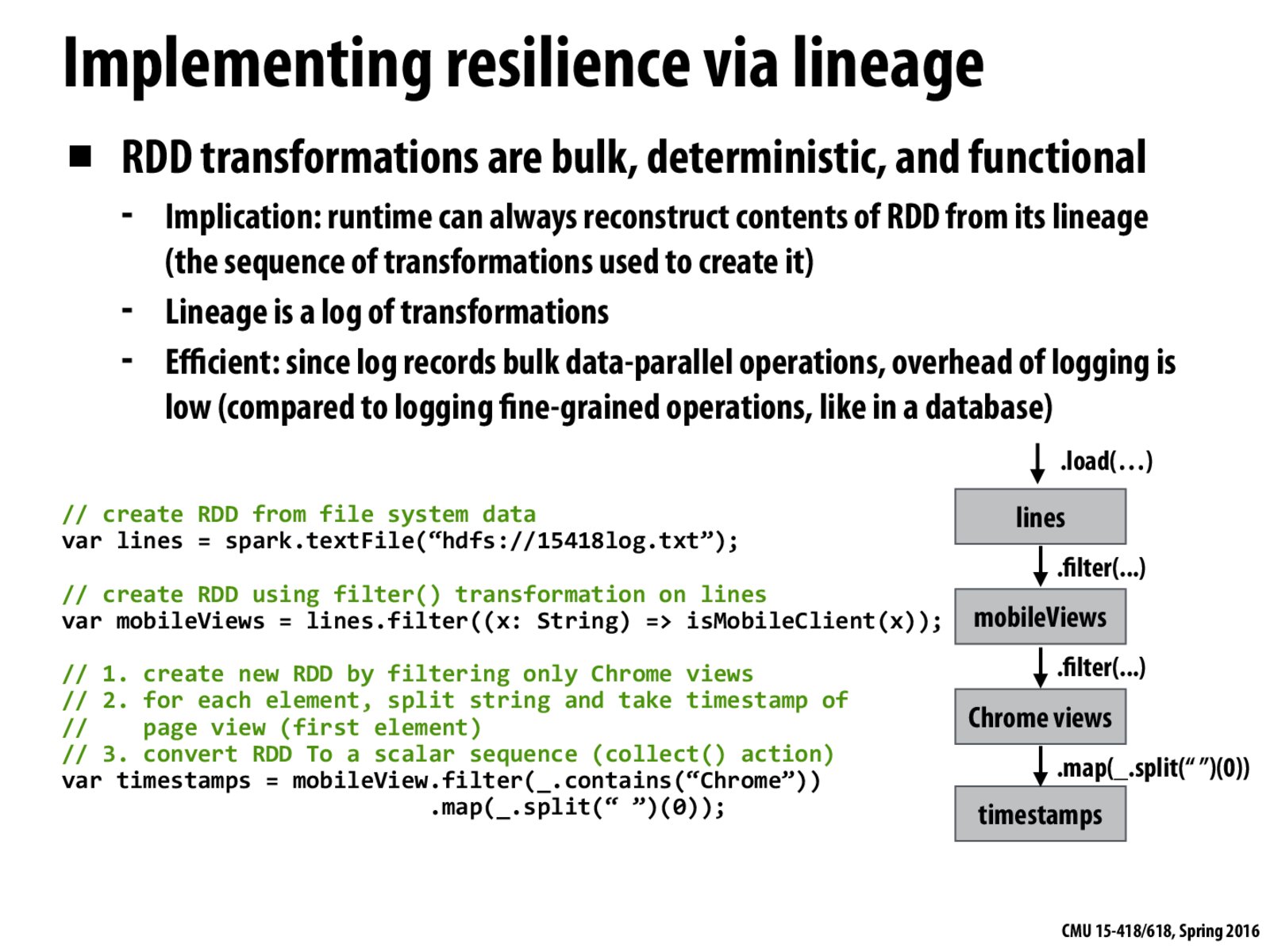
If I understand correctly, the lineage/transformation logs only need to store which chunk of data the operations are working on (i.e. a pointer) and a list of operations/functions that operate on that set of data. This is significantly smaller than in a database because in a database, the logs also have to store what data the operations are storing/changing.
makingthingsfast
Why do we not need to store the operations themselves?
trappedin418
I think we DO need to store the operations in the lineage, however we DON'T need to store the output of the operations in the lineage. This is different from a database because database transformations require knowledge of the data you are putting in, which requires extra logging overhead I presume. Perhaps a database isn't the best comparison.
The important thing is that the intermediate states are not stored in the logs, which make the logs smaller and much simpler (you can probably just store something that uniquely identifies an operation, maybe a function pointer).
randomized
I didn't get the concept of log here. From slide 22 a lineage is a sequence of RDD operations. So is it not the case that the statements themselves form the lineage? And since lineage is a log of transformations, I am not able to figure out how the additional lineage/transformation log is coming in the picture. I guess I am missing something very fundamental.
ZhuansunXt
Tachyon is a memory-centric file system that make use of this philosophy to achieve fault tolerance. The idea is instead of replicating files in a distributed environment, the transformation of a certain file can be tracked by lineage, which give rise to a checkpointing-like fault resilience mechanism.
bmperez
@randomized I think what the slide is saying here is that the lineage could be thought of as a log of transformations. Essentially, this is what it is. The implication from these slides is that all operations in Spark are lazily evaluated, meaning that when you call some method like filter, it is not evaluated when you call it in the program, but instead creates a new iterator like shown in slide 29.
The exact format of the log depends on the implementation, but as mentioned in this slide it will be bulk-parallel. So the log will not just simply contain the operations performed on the RDD, it will also need to contains which partition of the input RDD that is operating on. Thus a log entry would likely look something like {filter, isMobileClient, lines, partition 0}, or some similar format. So, when one node goes down, the system manager would parse through the logs and figure out the last operation that was successfully committed by the crashed node. Then, it would resume the computation on that partition, starting at that operation. Naturally, any partitions partitions assigned to the node that have not been executed would be reassigned to other nodes.
qqkk
To avoid the overhead of storing intermediates to disk like MapReduce, Spark stores lineage(including the reference to the part of data it works on, and a series of operations it performed). If intermediate data is needed, Spark recomputes it with the lineage.
If I understand correctly, the lineage/transformation logs only need to store which chunk of data the operations are working on (i.e. a pointer) and a list of operations/functions that operate on that set of data. This is significantly smaller than in a database because in a database, the logs also have to store what data the operations are storing/changing.
Why do we not need to store the operations themselves?
I think we DO need to store the operations in the lineage, however we DON'T need to store the output of the operations in the lineage. This is different from a database because database transformations require knowledge of the data you are putting in, which requires extra logging overhead I presume. Perhaps a database isn't the best comparison.
The important thing is that the intermediate states are not stored in the logs, which make the logs smaller and much simpler (you can probably just store something that uniquely identifies an operation, maybe a function pointer).
I didn't get the concept of log here. From slide 22 a lineage is a sequence of RDD operations. So is it not the case that the statements themselves form the lineage? And since lineage is a log of transformations, I am not able to figure out how the additional lineage/transformation log is coming in the picture. I guess I am missing something very fundamental.
Tachyon is a memory-centric file system that make use of this philosophy to achieve fault tolerance. The idea is instead of replicating files in a distributed environment, the transformation of a certain file can be tracked by lineage, which give rise to a checkpointing-like fault resilience mechanism.
@randomized I think what the slide is saying here is that the lineage could be thought of as a log of transformations. Essentially, this is what it is. The implication from these slides is that all operations in Spark are lazily evaluated, meaning that when you call some method like filter, it is not evaluated when you call it in the program, but instead creates a new iterator like shown in slide 29.
The exact format of the log depends on the implementation, but as mentioned in this slide it will be bulk-parallel. So the log will not just simply contain the operations performed on the RDD, it will also need to contains which partition of the input RDD that is operating on. Thus a log entry would likely look something like
{filter, isMobileClient, lines, partition 0}, or some similar format. So, when one node goes down, the system manager would parse through the logs and figure out the last operation that was successfully committed by the crashed node. Then, it would resume the computation on that partition, starting at that operation. Naturally, any partitions partitions assigned to the node that have not been executed would be reassigned to other nodes.To avoid the overhead of storing intermediates to disk like MapReduce, Spark stores lineage(including the reference to the part of data it works on, and a series of operations it performed). If intermediate data is needed, Spark recomputes it with the lineage.