Node 1 crashes, losing all intermediates (yellow boxes). We can just walk up the chain and redo the lineage for the lost output.
stride16
What are some of the reasons a node can crash herE?
Renegade
Clusters are usually heterogeneous, many reasons exist for a node failure. For example, DDoS attack, software bug, network partition, disk wear-out...
Allerrors
Or in extreme cases, earthquake, missile attack. In such cases, multiple nodes in one location won't help any more, where distributed clusters start working.
nmrrs
Could it be useful to send out partial results during computations to prevent having to completely recompute data if a node goes down?
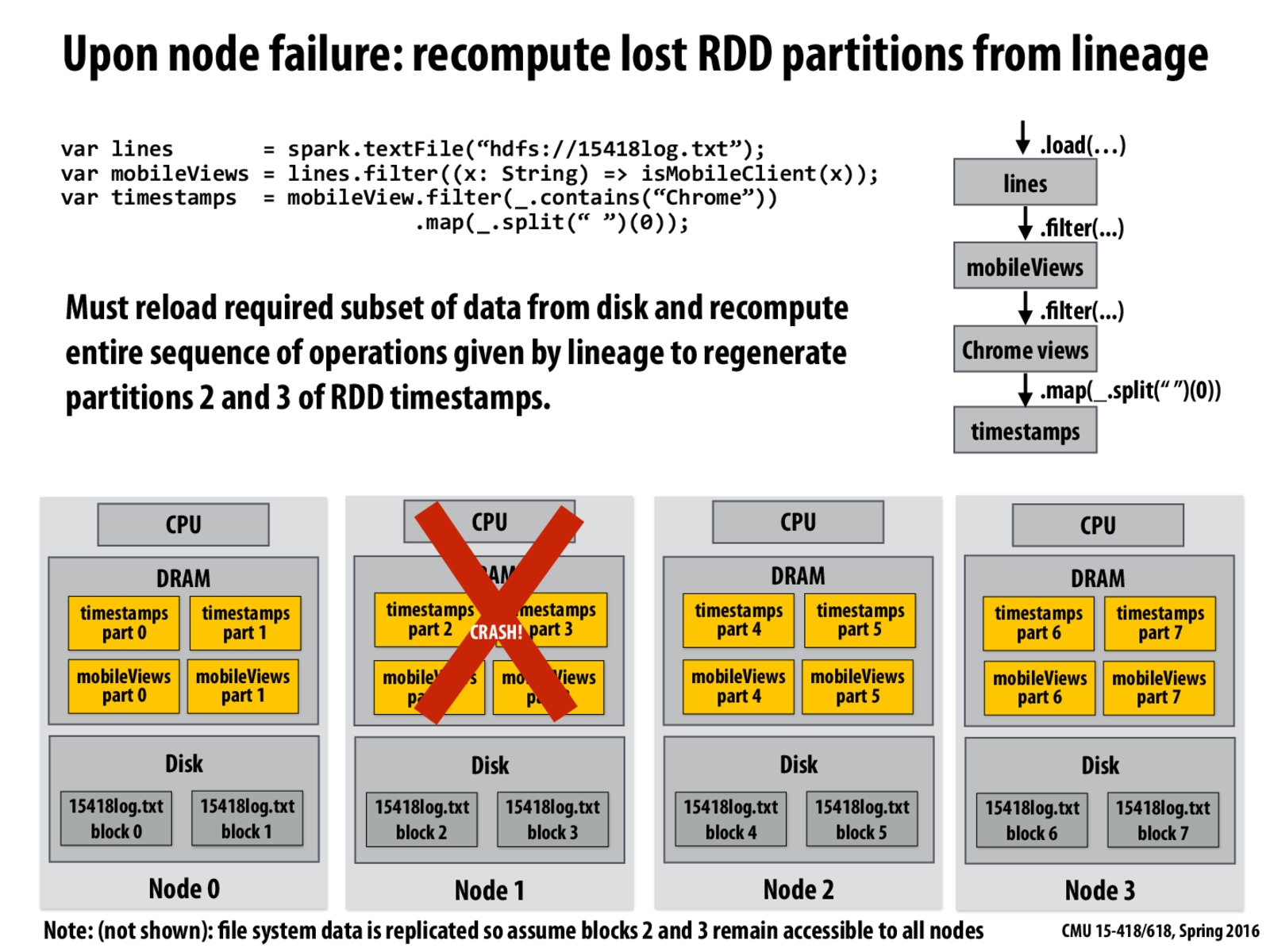
Node 1 crashes, losing all intermediates (yellow boxes). We can just walk up the chain and redo the lineage for the lost output.
What are some of the reasons a node can crash herE?
Clusters are usually heterogeneous, many reasons exist for a node failure. For example, DDoS attack, software bug, network partition, disk wear-out...
Or in extreme cases, earthquake, missile attack. In such cases, multiple nodes in one location won't help any more, where distributed clusters start working.
Could it be useful to send out partial results during computations to prevent having to completely recompute data if a node goes down?