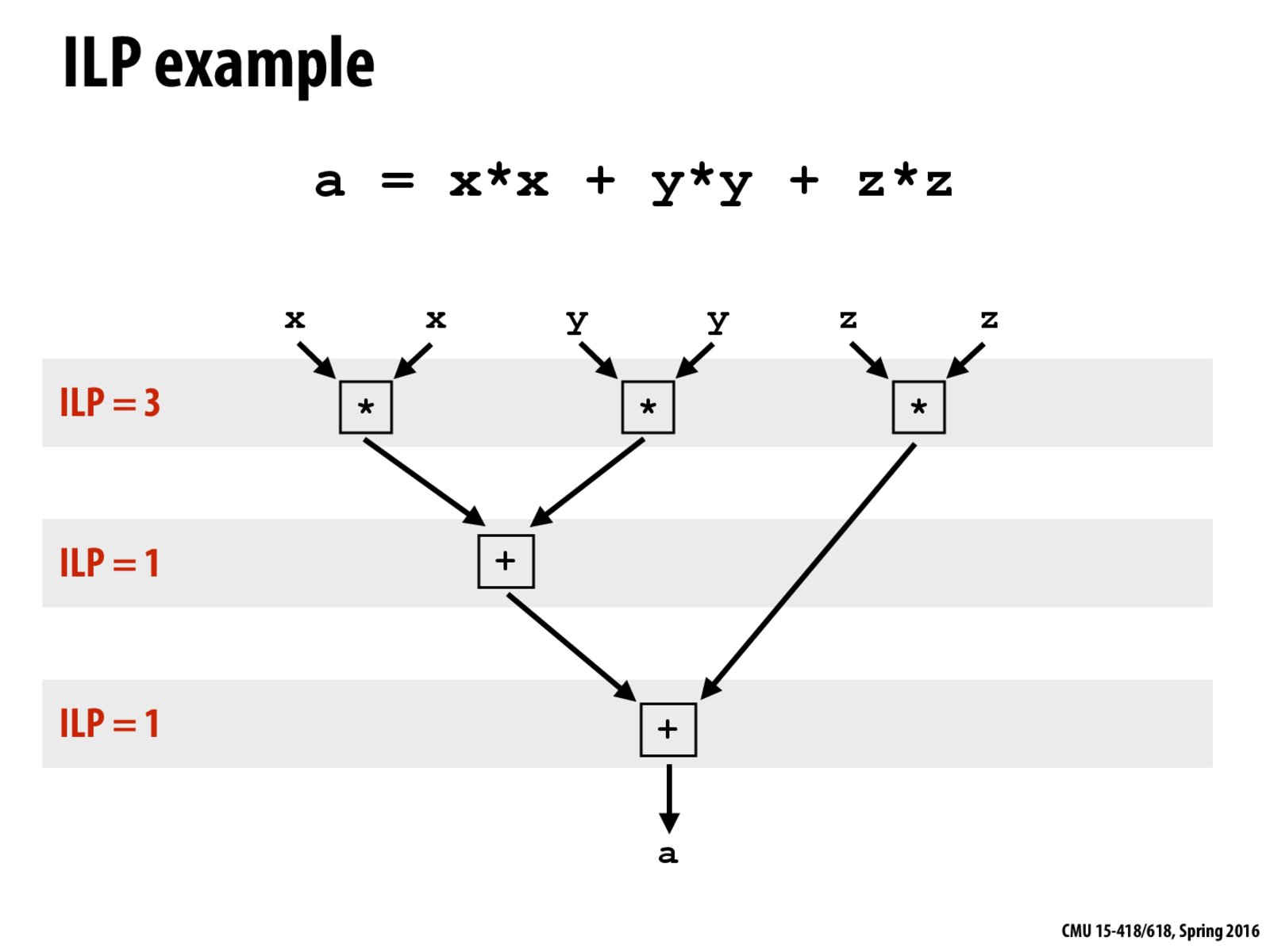
Question: Why is ILP 3 in the top row of the figure and 1 at the bottom?
remi_scarlet
I believe that the ILP is 3 on the top row as the three multiplication operations are independent of each other. Thus, the processor is able to, using superscalar execution, perform all three at the same time. However, the next two levels are dependent on the state of the previous operation and thus cannot be executed in parallel. Thus, they have to be performed sequentially and therefore the ILP is 1.
xx420y0los4wGxx
It's similar to a dynamic programming tree where lower ILP levels depend upon higher ILP levels, as such higher ILP must be executed first and it makes more sense to read top down in terms of execution order than bottom up.
EDIT: @remi_scarlet is probably correct. I misread the question as: "Why is ILP 3 on top of the ILP 1" rather than "Why is the top row labeled as ILP3"
remi_scarlet
@xx420y0los4wGxx I believe the ILP refers to the actual number of operations that are able to be done in parallel. I may be incorrect, but I believe the actual ILP refers to the number of operations that are able to be performed with SIMD on the core's ALU's. Someone correct me if I'm wrong.
kayvonf
I'd like to clarify some terminology here. If you take a look at my instructor's note on the previous slide, and what @remi_scarlet correctly states above, notice that ILP is a property of the program. It is a measure of the number of instructions that are independent and could be executed in parallel.
We didn't say much about precisely how those instructions are executed in parallel by a CPU. A superscalar processor is a processor that can execute multiple, different instructions simultaneously using different execution units. @remi_scarlet: This is a different implementation approach than SIMD execution, where the same instruction is executed on different pieces of data at the same time. (e.g., a 4-wide SIMD execution unit is capable of simultaneously performing 4 adds, or 4 multiplies, but it could not do 1 add, 1 multiply, 1 load, and 1 subtract in parallel, which might be the case in a 4-wide superscalar design if that mixture of instructions was present in the instruction stream.) I'll defer a more precise answer until next class. We can add more to this thread then.
remi_scarlet
Ah, seems I've mixed up ILP and SIMD then. I had thought they were "related" approaches to processing the data as opposed to them being two different approaches. I'm looking forward to learning about it in the next class!
steffid
Can we think of ILP as a way of dataflow programming model where instruction is executed when the inputs are available for a certain number of instructions, as opposed to the entire program in case of a dataflow model?
kayvonf
@steffid. Terminology is really important here. (And it's one of the reasons I ask students to write! Remember, ILP is just a measure of the number of independent instructions at a point in a program. Your comment is a good one, but it pertains to the implementation of superscalar execution.
stee
Is ILP always a measure of parallelism at a point in a program? The wiki page for ILP seems to suggest that there is also a measure of parallelism for the entire program. Also, does ILP assume that every instruction takes exactly one unit of time?
leaf2fire
Would there be any cost or benefit if the last multiplication is done on the second line instead of the first?
tding
@stee For the second question, no, and we often mention "one cycle" rather than "one unit of time". Typically * takes more cycles than + and / takes even more, not to mention if you try to load an address, it results in a cache miss. However, * and + can be still issued and executed simultaneously given sufficient ALUs.
tding
@leaf2fire Multiplication takes more cycles than addition. Assuming there are sufficient ALUs, if moving the last * to the second line, then + on the second line has to wait until * finishes before moving to the third line. But otherwise that + can just grab the value z*z and go through.
kayvonf
@tding. Actually, on modern Intel processors "multiples are more expensive that adds" is a bit of a myth. You should assume that most common arithmetic operations have similar performance characteristics (add, sub, multiply, bit ops, etc.) It is true that divide, reciprocal, sqrt, and transcendentals (like sin/cos) are more expensive.
Compare the throughput of vector floating point add: mm256_add_ps (1 instruction every clock on Haswell)
With that of vector floating point multiply: mm256_mul_ps (1 instruction every 1/2 clock on Haswell, actually higher throughput than adds! -- note in the intrinsics guide "throughput" is giving clocks per instruction not instructions per clock.)
Aside: So I lied a bit. In practice on Haswell and later, there's a single instruction fused multiply-add instruction, and two of these instructions can be issued per clock (1 instruction every 1/2 clock), so you can do 2 8-wide multiply-adds per clock, provided your application can be a little loose with its floating point precision. See mm256_fmadd_ps:
@kayvonf Thanks for pointing that out. Admittedly, instructions are made faster and faster, but I think the takeaway from this example is that different execution paths (orders of executing *s and +s) could lead to different performance.
acfeng
If common arithmetic operations are similarly performant, in this case would having a dual-core processor instead of a triple-core processor to process the arithmetic only marginally affect the performance?
notanonymous
Is this type of independence tree actually used as an implementation or just a handy abstraction to understand the different operations that can be computed in parallel?
Question: Why is ILP 3 in the top row of the figure and 1 at the bottom?
I believe that the ILP is 3 on the top row as the three multiplication operations are independent of each other. Thus, the processor is able to, using superscalar execution, perform all three at the same time. However, the next two levels are dependent on the state of the previous operation and thus cannot be executed in parallel. Thus, they have to be performed sequentially and therefore the ILP is 1.
It's similar to a dynamic programming tree where lower ILP levels depend upon higher ILP levels, as such higher ILP must be executed first and it makes more sense to read top down in terms of execution order than bottom up.
EDIT: @remi_scarlet is probably correct. I misread the question as: "Why is ILP 3 on top of the ILP 1" rather than "Why is the top row labeled as ILP3"
@xx420y0los4wGxx I believe the ILP refers to the actual number of operations that are able to be done in parallel. I may be incorrect, but I believe the actual ILP refers to the number of operations that are able to be performed with SIMD on the core's ALU's. Someone correct me if I'm wrong.
I'd like to clarify some terminology here. If you take a look at my instructor's note on the previous slide, and what @remi_scarlet correctly states above, notice that ILP is a property of the program. It is a measure of the number of instructions that are independent and could be executed in parallel.
We didn't say much about precisely how those instructions are executed in parallel by a CPU. A superscalar processor is a processor that can execute multiple, different instructions simultaneously using different execution units. @remi_scarlet: This is a different implementation approach than SIMD execution, where the same instruction is executed on different pieces of data at the same time. (e.g., a 4-wide SIMD execution unit is capable of simultaneously performing 4 adds, or 4 multiplies, but it could not do 1 add, 1 multiply, 1 load, and 1 subtract in parallel, which might be the case in a 4-wide superscalar design if that mixture of instructions was present in the instruction stream.) I'll defer a more precise answer until next class. We can add more to this thread then.
Ah, seems I've mixed up ILP and SIMD then. I had thought they were "related" approaches to processing the data as opposed to them being two different approaches. I'm looking forward to learning about it in the next class!
Can we think of ILP as a way of dataflow programming model where instruction is executed when the inputs are available for a certain number of instructions, as opposed to the entire program in case of a dataflow model?
@steffid. Terminology is really important here. (And it's one of the reasons I ask students to write! Remember, ILP is just a measure of the number of independent instructions at a point in a program. Your comment is a good one, but it pertains to the implementation of superscalar execution.
Is ILP always a measure of parallelism at a point in a program? The wiki page for ILP seems to suggest that there is also a measure of parallelism for the entire program. Also, does ILP assume that every instruction takes exactly one unit of time?
Would there be any cost or benefit if the last multiplication is done on the second line instead of the first?
@stee For the second question, no, and we often mention "one cycle" rather than "one unit of time". Typically * takes more cycles than + and / takes even more, not to mention if you try to load an address, it results in a cache miss. However, * and + can be still issued and executed simultaneously given sufficient ALUs.
@leaf2fire Multiplication takes more cycles than addition. Assuming there are sufficient ALUs, if moving the last * to the second line, then + on the second line has to wait until * finishes before moving to the third line. But otherwise that + can just grab the value z*z and go through.
@tding. Actually, on modern Intel processors "multiples are more expensive that adds" is a bit of a myth. You should assume that most common arithmetic operations have similar performance characteristics (add, sub, multiply, bit ops, etc.) It is true that divide, reciprocal, sqrt, and transcendentals (like sin/cos) are more expensive.
Compare the throughput of vector floating point add:
mm256_add_ps(1 instruction every clock on Haswell)https://software.intel.com/sites/landingpage/IntrinsicsGuide/#techs=AVX,AVX2&cats=Arithmetic&expand=112
With that of vector floating point multiply:
mm256_mul_ps(1 instruction every 1/2 clock on Haswell, actually higher throughput than adds! -- note in the intrinsics guide "throughput" is giving clocks per instruction not instructions per clock.)https://software.intel.com/sites/landingpage/IntrinsicsGuide/#techs=AVX,AVX2&cats=Arithmetic&expand=3641
With that of vector floating point divide:
mm256_div_ps(1 divide every 13 cycles on Haswell, 13x slower!)https://software.intel.com/sites/landingpage/IntrinsicsGuide/#techs=AVX,AVX2&cats=Arithmetic&expand=2059
Aside: So I lied a bit. In practice on Haswell and later, there's a single instruction fused multiply-add instruction, and two of these instructions can be issued per clock (1 instruction every 1/2 clock), so you can do 2 8-wide multiply-adds per clock, provided your application can be a little loose with its floating point precision. See
mm256_fmadd_ps:https://software.intel.com/sites/landingpage/IntrinsicsGuide/#techs=FMA&cats=Arithmetic&expand=2381,112,100,2381
@kayvonf Thanks for pointing that out. Admittedly, instructions are made faster and faster, but I think the takeaway from this example is that different execution paths (orders of executing *s and +s) could lead to different performance.
If common arithmetic operations are similarly performant, in this case would having a dual-core processor instead of a triple-core processor to process the arithmetic only marginally affect the performance?
Is this type of independence tree actually used as an implementation or just a handy abstraction to understand the different operations that can be computed in parallel?