The Y axis is the speedup compared to running code on a processor capable of executing only a single instruction per clock. The results shown are average speedup over a large benchmark suite of popular programs at the time.
kayvonf
Question: Can someone give me a good definition of what I mean by "how much ILP a processor is able to exploit?"
KimJongUn
I'm a little confuesed on the "about to" part. Also how does the ILP know when it can execute instructions in parallel? Does this mean it does as many instructions as it can in one clock cycle?
edit: ignore the "about to" part
anonymous
The processor has to look through the instructions and see which are done independent of others. If instructions are done independently of others than the processor can exploit ILP, meaning it can simultaneously execute these instructions, instead of executing them in the order presented. The example slides show ILP only being exploited in reference to the ALU; are there other times at which the processor can exploit ILP?
stl
From what I understood, ILP is a measure of how many instructions can be executed in parallel given a set of instructions. So, I interpreted "how much ILP a processor is able to exploit" as a measure of the actual number of instructions the processor determined to be independent and was able to physically execute in parallel at a given time step. But, I also had the question of how the processor is able to determine instructions to be independent.
gnunicorn
It would seem that processors have dedicated logic to identify sets of instructions which do not depend on each other. Then, these sets of instructions can be executed together (in parallel), which is referred to as ILP. The amount of ILP that the process is able to exploit would be the size of such a set of instructions.
Does this sound correct?
kayvonf
@gunicorn: Tomasulo's algorithm is one approach to implementing out-of-order (including parallel) execution in a superscalar processor.
Of course, if you're interested in advanced superscalar processor design, you'll have to take a course like 18-447.
kayvonf
Typo fix. My original question had "about to" when I meant to say "able to". (Just like I did in the instructor note.)
bojianh
Is the maximum amount of ILP a process can exploit dependent on the number of registers that the CPU has? In other words, for a CPU with 8 regs and a CPU with 16 regs, is the ILP different.
From what I see, the number of registers seem to limit the amount of instructions that can be independent of each other. However, I am not too sure whether this is indeed correct. And also if this is true, does that mean that it is viable to increase the register count to exploit ILP?
IntergalacticPeanutMaker
Was this graph generated using code which happened to mainly only have 4 independent instructions available to be executed at any given time? Is the real asymptote at say (I have no idea) 100 because it just so happens that humans write code for stuff that only has around 100 independent instructions available to be executed at any given time?
kayvonf
@bojianh: You've hit on a very important observation that there's a relationship between how much parallelism you wish to extract and how much state a system the system can actively maintain. This is true for any level of the memory hierarchy, not just registers.
Imagine you have a program whose working set just fits inside the processor's cache. Now imagine a system with two processors that share this cache. Assuming each processor is running a copy of the program (and thus accesses different data), that means that the working set of all programs on the machine is twice as big, or equivalently, that the effective cache size for each processor is 1/2 the size. More on this later...
arundhati
I think the processor's ability to exploit ILP can also be limited by the penalty of execution and the hardware abilities? For example, if the processor (superscalar) can fetch and decode N instructions simultaneously it can determine and exploit ILP for those. But this N can be limited by the penalty (caused by conditional execution of instructions) of execution too?
Funky9000
Doesn't ILP depend on the number of ALUs on a core and the number of cores? So a processor can exploit ILP as much as it can depending on the program (many independent instructions) and the number of hardware units that can execute those instructions simultaneously.
So if that is the case, then I do not understand why speedup is limited when the number of instructions issued by a processor increases above 4?
ojd
@bojianh The 8-16 register limitation of x86 is mostly a limitation on the ISA and the compiler's ability to expose ILP. In practice, with OoO exec, modern processors have significantly more physical registers than what the ISA exposes (roughly on the order of 150 or more). Once the CPU identifies the data flow, it's allowed to rename and reorder things however it wants (as long as some rather strict x86 backwards-compatibility requirements on memory accesses are still observed). The real issue is how much ILP the compiler can expose without forcing a write or read of memory at which point renaming becomes difficult if you want to avoid having observably different behavior from the simple Intel processors of the 70s. This results in a slightly nastier packing problem than normal register allocation.
As a side note, the data this graph uses is from 1991. Branch prediction and techniques for dealing with memory-related stalls have become much more sophisticated, so there might be slightly more ILP opportunity available today. That said, even Intel's modern processors seem to have a soft/hard bounds of 4-6 instructions per clock (for example, 2.3.3.1 in http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf ), so it's likely that this data is still correct. Is there a more modern paper (with modern programs/processors etc...) collecting similar data?
fuzzyduck
@Funky9000: I believe that the speedup is limited because we can hardly ever find so many independent instructions in a particular program. So even if the instruction issue capability is more, it doesn't make any difference because there aren't as many independent instructions that can execute in parallel in an average scenario. Thus, the rate of increase in speedup diminishes.
hofstee
@Funky9000 the graph is created from data sampled over many different programs. What the graph represents is not a per-program rule, but an average seen over many programs. Certain programs could certainly use ILP to speed up significantly more than 4x or so, assuming the CPU is designed in such a way that allows it to do so.
yikesaiting
To answer the instructor's question, I think by "how much ILP a processor is able to exploit", he means the physical attribute of the processor of how many computing units it have that can work in parallel.
One thing that reminds me is about the bottleneck of parallelism brought by processor is when ILP can find more instructions to be operated at the same time than the number of computing units. Does it means that often in average(because the graph here is the average of speedup), the ILP of a program is bounded by the ratio of 4?
yimmyz
Just curious about the source of the graph on this slide -- in academia or industry, how is one able to benchmark the speedup of a processor with different ILP setups? Is it by empirical experiments, or hypothetical analysis, or a combination of both?
If it is done empirically, then how can we know that the result above still holds when other parts of the processor might change over time?
hofstee
@yimmyz because the graph (from what I understand) isn't saying the speedup we get from a processor, it's saying regardless of how much superscalar execution any processor has, programs (on average) cap at around 4 independent instructions, so you can't expect much more than a 4x speedup regardless of processor from just ILP.
It's probably benchmarked by intercepting instructions and feeding them into a fake simulated processor, similar to what was done with malloc in 213. Or you could run some sort of instruction dependency checker on a text file and see an average instruction count.
yimmyz
@hofstee That makes sense -- thanks!
randomized
@hofstee: In your answer, I guess instead of "how much ILP any processor has", you meant "how much ILP a processor can exploit". (because ILP is a property of the program).
kayvonf
@randomized. Good point. That's clear thinking! (Also credit to @hofstee for a good post nonetheless.)
hofstee
@randomized I suppose the more correct term would have been superscalar execution.
kayvonf
@hoststee. correct! ps. Posts are editable.
ZhuansunXt
It's quite beneficial to read through the discussion on this slide, and it help me understand the concept of ILP more clearly. A very important note about ILP is to consider is as a property of the program (not a processor). It measures the number of independent instructions that could potentially be executed at the same time by the processor.
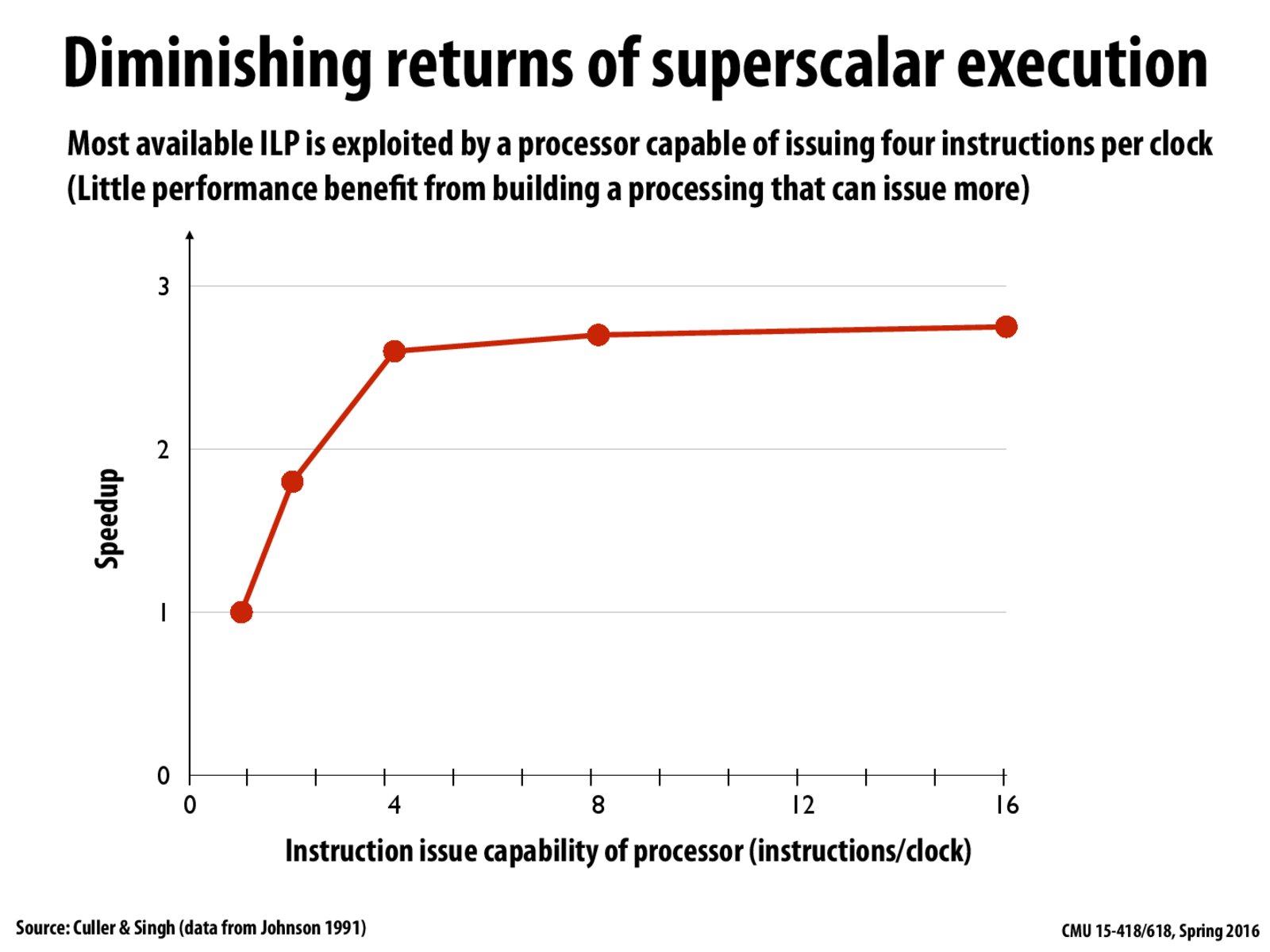
This graph's horizontal access is the number of superscalar execution units present in a single processor. In other words, it is:
The Y axis is the speedup compared to running code on a processor capable of executing only a single instruction per clock. The results shown are average speedup over a large benchmark suite of popular programs at the time.
Question: Can someone give me a good definition of what I mean by "how much ILP a processor is able to exploit?"
I'm a little confuesed on the "about to" part. Also how does the ILP know when it can execute instructions in parallel? Does this mean it does as many instructions as it can in one clock cycle?
edit: ignore the "about to" part
The processor has to look through the instructions and see which are done independent of others. If instructions are done independently of others than the processor can exploit ILP, meaning it can simultaneously execute these instructions, instead of executing them in the order presented. The example slides show ILP only being exploited in reference to the ALU; are there other times at which the processor can exploit ILP?
From what I understood, ILP is a measure of how many instructions can be executed in parallel given a set of instructions. So, I interpreted "how much ILP a processor is able to exploit" as a measure of the actual number of instructions the processor determined to be independent and was able to physically execute in parallel at a given time step. But, I also had the question of how the processor is able to determine instructions to be independent.
It would seem that processors have dedicated logic to identify sets of instructions which do not depend on each other. Then, these sets of instructions can be executed together (in parallel), which is referred to as ILP. The amount of ILP that the process is able to exploit would be the size of such a set of instructions.
Does this sound correct?
@gunicorn: Tomasulo's algorithm is one approach to implementing out-of-order (including parallel) execution in a superscalar processor.
https://en.wikipedia.org/wiki/Tomasulo_algorithm
Of course, if you're interested in advanced superscalar processor design, you'll have to take a course like 18-447.
Typo fix. My original question had "about to" when I meant to say "able to". (Just like I did in the instructor note.)
Is the maximum amount of ILP a process can exploit dependent on the number of registers that the CPU has? In other words, for a CPU with 8 regs and a CPU with 16 regs, is the ILP different.
From what I see, the number of registers seem to limit the amount of instructions that can be independent of each other. However, I am not too sure whether this is indeed correct. And also if this is true, does that mean that it is viable to increase the register count to exploit ILP?
Was this graph generated using code which happened to mainly only have 4 independent instructions available to be executed at any given time? Is the real asymptote at say (I have no idea) 100 because it just so happens that humans write code for stuff that only has around 100 independent instructions available to be executed at any given time?
@bojianh: You've hit on a very important observation that there's a relationship between how much parallelism you wish to extract and how much state a system the system can actively maintain. This is true for any level of the memory hierarchy, not just registers.
Imagine you have a program whose working set just fits inside the processor's cache. Now imagine a system with two processors that share this cache. Assuming each processor is running a copy of the program (and thus accesses different data), that means that the working set of all programs on the machine is twice as big, or equivalently, that the effective cache size for each processor is 1/2 the size. More on this later...
I think the processor's ability to exploit ILP can also be limited by the penalty of execution and the hardware abilities? For example, if the processor (superscalar) can fetch and decode N instructions simultaneously it can determine and exploit ILP for those. But this N can be limited by the penalty (caused by conditional execution of instructions) of execution too?
Doesn't ILP depend on the number of ALUs on a core and the number of cores? So a processor can exploit ILP as much as it can depending on the program (many independent instructions) and the number of hardware units that can execute those instructions simultaneously.
So if that is the case, then I do not understand why speedup is limited when the number of instructions issued by a processor increases above 4?
@bojianh The 8-16 register limitation of x86 is mostly a limitation on the ISA and the compiler's ability to expose ILP. In practice, with OoO exec, modern processors have significantly more physical registers than what the ISA exposes (roughly on the order of 150 or more). Once the CPU identifies the data flow, it's allowed to rename and reorder things however it wants (as long as some rather strict x86 backwards-compatibility requirements on memory accesses are still observed). The real issue is how much ILP the compiler can expose without forcing a write or read of memory at which point renaming becomes difficult if you want to avoid having observably different behavior from the simple Intel processors of the 70s. This results in a slightly nastier packing problem than normal register allocation.
As a side note, the data this graph uses is from 1991. Branch prediction and techniques for dealing with memory-related stalls have become much more sophisticated, so there might be slightly more ILP opportunity available today. That said, even Intel's modern processors seem to have a soft/hard bounds of 4-6 instructions per clock (for example, 2.3.3.1 in http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf ), so it's likely that this data is still correct. Is there a more modern paper (with modern programs/processors etc...) collecting similar data?
@Funky9000: I believe that the speedup is limited because we can hardly ever find so many independent instructions in a particular program. So even if the instruction issue capability is more, it doesn't make any difference because there aren't as many independent instructions that can execute in parallel in an average scenario. Thus, the rate of increase in speedup diminishes.
@Funky9000 the graph is created from data sampled over many different programs. What the graph represents is not a per-program rule, but an average seen over many programs. Certain programs could certainly use ILP to speed up significantly more than 4x or so, assuming the CPU is designed in such a way that allows it to do so.
To answer the instructor's question, I think by "how much ILP a processor is able to exploit", he means the physical attribute of the processor of how many computing units it have that can work in parallel.
One thing that reminds me is about the bottleneck of parallelism brought by processor is when ILP can find more instructions to be operated at the same time than the number of computing units. Does it means that often in average(because the graph here is the average of speedup), the ILP of a program is bounded by the ratio of 4?
Just curious about the source of the graph on this slide -- in academia or industry, how is one able to benchmark the speedup of a processor with different ILP setups? Is it by empirical experiments, or hypothetical analysis, or a combination of both?
If it is done empirically, then how can we know that the result above still holds when other parts of the processor might change over time?
@yimmyz because the graph (from what I understand) isn't saying the speedup we get from a processor, it's saying regardless of how much superscalar execution any processor has, programs (on average) cap at around 4 independent instructions, so you can't expect much more than a 4x speedup regardless of processor from just ILP.
It's probably benchmarked by intercepting instructions and feeding them into a fake simulated processor, similar to what was done with malloc in 213. Or you could run some sort of instruction dependency checker on a text file and see an average instruction count.
@hofstee That makes sense -- thanks!
@hofstee: In your answer, I guess instead of "how much ILP any processor has", you meant "how much ILP a processor can exploit". (because ILP is a property of the program).
@randomized. Good point. That's clear thinking! (Also credit to @hofstee for a good post nonetheless.)
@randomized I suppose the more correct term would have been superscalar execution.
@hoststee. correct! ps. Posts are editable.
It's quite beneficial to read through the discussion on this slide, and it help me understand the concept of ILP more clearly. A very important note about ILP is to consider is as a property of the program (not a processor). It measures the number of independent instructions that could potentially be executed at the same time by the processor.