To make clear the scope of what's considered ILP and what's not, does this region only not contain ILP because it is assumed there is no hardware support for multiplying three numbers directly?
For example: "mul r4, r3, r2, r1"
A related follow-up: if such an instruction existed, this would be an example of hardware parallelism right? (but in a different way than having multiple physical cores would be an example of hardware parallelism?)
adityam1
Instruction level parallelism is based on the ability of the hardware to execute two instructions at the same instance of time. Such an event is only possible if the two instructions are completely independent of each other i.e. the computations of these instructions should not be involving the same registers.
If the hardware had an instruction that would perform multiplication of three numbers at a time, that would not be considered as an ILP since there is only one instruction being implemented, though this instruction could be performing parallel logical operations, but that is something that the hardware is not aware of and neither does the hardware care.
mario
Instruction level parallelism looks to see if two instructions can be executed at the same time given that the hardware has the ability to do so. In the circled instructions on the slide, there is no ILP since the contents of the r1 register are needed in both of the commands.
PhiLo
The distinction between ILP and SIMD is that ILP parallelizes instructions while SIMD parallelizes data. For example if you want to do 4 addition, you can do it by 4 scalar add instructions (in parallel) or you can do it by 1 vector add instruction. The former is ILP and the latter is SIMD.
unparalleled
We are fetching two independent instructions from a single instruction stream, like superscalaar systems. But in Hyper-threading we fetch multiple instructions from different instruction stream exactly similar to how multi-core systems work.
kayvonf
@PhiLo, to drill into this more. I'd say that a superscalar processor (not ILP) finds the presence of ILP in a sequential instruction stream. When ILP is found, parallel execution may occur.
In contrast, in most situations, including both explicit and implicit SIMD, the parallelism to exploit need not be found automatically by the processor. It is either explicitly declared by the program (in the explicit case, via the presence of SIMD vector instructions in the instruction stream itself), or by the rules of the architecture in the implicit case ("this scalar instruction stream will always be run on a batch of data elements").
Consider the following two back-to-back instructions in an single instruction stream:
mul r0 r0 r1;
mul r4 r4 r5;
There is certainly ILP in this instruction stream as these are two independent multiplies. One could imagine a hypothetical processor that was engineered to be able to find this ILP, and also identify the same op was used, and then hypothetically efficiently execute the two instructions as a single, even more efficient 2-wide SIMD instruction (rather than executing two mul's in simultaneously on two available non-SIMD ALUs). However, I don't know of any processors that do that. Typically the efficiency of SIMD execution is not just about shared control, but also having all the data lined up in the appropriate lanes/data-paths for efficient transfer to the SIMD ALUs, and that typically wouldn't be the case if a processor tried to manufacture SIMD execution on the fly from independent scalar instructions.
anonymous
After reading the comments above, I make the following conclusions (please correct me if I'm wrong):
1, a superscalar processor can execute ILP by simultaneously dispatching multiple instructions to different execution units on the processor. Each execution unit is not a separate processor (or a core if the processor is a multi-core processor), but an execution resource within a single CPU such as an arithmetic logic unit.
2, Currently, there's no processors that have the ability to dynamically identify the ILP and dispatch them among those available ALUs.
3, Hence, it usually relies programmers to explicitly write ILP code (ISPC) or the processors can implicitly support SIMD. That's all decided statically at the compile time.
kayvonf
@anonymous. Here are some fixes.
A superscalar processor can take advantage of of an instruction stream featuring ILP by simultaneously...
I disagree with this statement. The whole point of a superscalar processor is in fact to dynamically identify ILP in an instruction stream and use that information to dispatch independent instructions in parallel to multiple ALUs.
See above comment on two.
anonymous
We alse need to differentiate two concepts: pipelined and superscalar.
"The former executes multiple instructions in the same execution unit in parallel by dividing the execution unit into different phases, whereas the latter executes multiple instructions in parallel by using multiple execution units". From wikipedia.
chandana
Pipeline and superscalar are two techniques used to achieve instruction level parallelism. A cpu that implements ILP within single processor is called as super scalar processor. A single core superscalar processor can be classified as SISD Single core superscalar processor with vector operations can be classified as SIMD A multicore super scalar processor can be classified as MIMD type
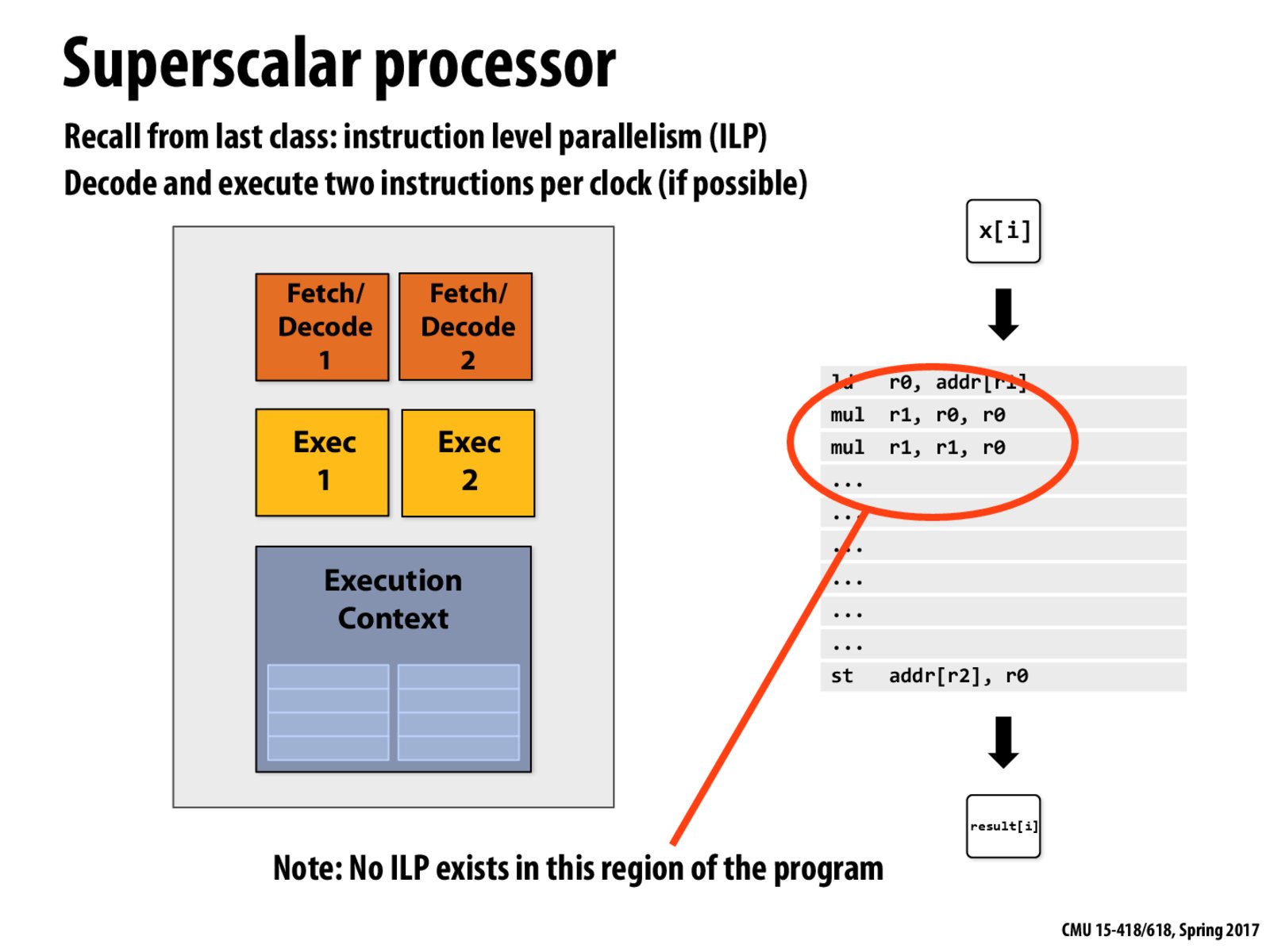
To make clear the scope of what's considered ILP and what's not, does this region only not contain ILP because it is assumed there is no hardware support for multiplying three numbers directly?
For example: "mul r4, r3, r2, r1"
A related follow-up: if such an instruction existed, this would be an example of hardware parallelism right? (but in a different way than having multiple physical cores would be an example of hardware parallelism?)
Instruction level parallelism is based on the ability of the hardware to execute two instructions at the same instance of time. Such an event is only possible if the two instructions are completely independent of each other i.e. the computations of these instructions should not be involving the same registers.
If the hardware had an instruction that would perform multiplication of three numbers at a time, that would not be considered as an ILP since there is only one
instructionbeing implemented, though this instruction could be performing parallel logical operations, but that is something that the hardware is not aware of and neither does the hardware care.Instruction level parallelism looks to see if two instructions can be executed at the same time given that the hardware has the ability to do so. In the circled instructions on the slide, there is no ILP since the contents of the r1 register are needed in both of the commands.
The distinction between ILP and SIMD is that ILP parallelizes instructions while SIMD parallelizes data. For example if you want to do 4 addition, you can do it by 4 scalar add instructions (in parallel) or you can do it by 1 vector add instruction. The former is ILP and the latter is SIMD.
We are fetching two independent instructions from a single instruction stream, like superscalaar systems. But in Hyper-threading we fetch multiple instructions from different instruction stream exactly similar to how multi-core systems work.
@PhiLo, to drill into this more. I'd say that a superscalar processor (not ILP) finds the presence of ILP in a sequential instruction stream. When ILP is found, parallel execution may occur.
In contrast, in most situations, including both explicit and implicit SIMD, the parallelism to exploit need not be found automatically by the processor. It is either explicitly declared by the program (in the explicit case, via the presence of SIMD vector instructions in the instruction stream itself), or by the rules of the architecture in the implicit case ("this scalar instruction stream will always be run on a batch of data elements").
Consider the following two back-to-back instructions in an single instruction stream:
There is certainly ILP in this instruction stream as these are two independent multiplies. One could imagine a hypothetical processor that was engineered to be able to find this ILP, and also identify the same op was used, and then hypothetically efficiently execute the two instructions as a single, even more efficient 2-wide SIMD instruction (rather than executing two mul's in simultaneously on two available non-SIMD ALUs). However, I don't know of any processors that do that. Typically the efficiency of SIMD execution is not just about shared control, but also having all the data lined up in the appropriate lanes/data-paths for efficient transfer to the SIMD ALUs, and that typically wouldn't be the case if a processor tried to manufacture SIMD execution on the fly from independent scalar instructions.
After reading the comments above, I make the following conclusions (please correct me if I'm wrong): 1, a superscalar processor can execute ILP by simultaneously dispatching multiple instructions to different execution units on the processor. Each execution unit is not a separate processor (or a core if the processor is a multi-core processor), but an execution resource within a single CPU such as an arithmetic logic unit. 2, Currently, there's no processors that have the ability to dynamically identify the ILP and dispatch them among those available ALUs. 3, Hence, it usually relies programmers to explicitly write ILP code (ISPC) or the processors can implicitly support SIMD. That's all decided statically at the compile time.
@anonymous. Here are some fixes.
A superscalar processor can take advantage of of an instruction stream featuring ILP by simultaneously...
I disagree with this statement. The whole point of a superscalar processor is in fact to dynamically identify ILP in an instruction stream and use that information to dispatch independent instructions in parallel to multiple ALUs.
See above comment on two.
We alse need to differentiate two concepts: pipelined and superscalar. "The former executes multiple instructions in the same execution unit in parallel by dividing the execution unit into different phases, whereas the latter executes multiple instructions in parallel by using multiple execution units". From wikipedia.
Pipeline and superscalar are two techniques used to achieve instruction level parallelism. A cpu that implements ILP within single processor is called as super scalar processor.
A single core superscalar processor can be classified as SISD
Single core superscalar processor with vector operations can be classified as SIMD
A multicore super scalar processor can be classified as MIMD type