All of these caches are sending message / receiving message to each other, yelling through the interconnect. So when the "write" occurs, the "writer" cache will tell other caches to drop their content of the "written" cache line. As a result, next time P1 read, it will get the data from memory, and thus we can achieve memory coherence.
What is not ideal in this approach is that every single write will be write-through, and so it will fill the bandwidth very quickly.
woohoo
Summary:
P0 loads X - cache miss, so X is loaded from memory.
P1 loads X - cache miss, so X is loaded from memory.
P0 write 100 to X: P1's copy of X is invalidated. Since it is a write-through cache, X is updated in memory.
P1 loads X: cache miss, so X is loaded from memory with the correct value.
ayy_lmao
Why are the messages simply invalidation messages? Would it not be more effective to instead send messages of the form "update X to 100"? I believe that this strategy would reduce a lot of the cache misses in the current strategy.
yes
That might require more communication overhead though since you're sending more data right? So perhaps invalidation messages are more simple, faster, and require less data transfer.
chandana
What happens if two processors have to write to the value of X at the same time? Which processor writes to the value and which processor's cache drops the line?
paracon
@ayy_lmao, I think a cache coherence protocol that sends information of what was done to data to the bus is not a good idea. Firstly, more complex set of signals will be required to different operation - multiply, add, divide etc. which could potentially make decoding and encoding these signals slower. Secondly, the coherence protocol might need additions when the instruction set architecture is modified (in order to construct exact messages of data change)
jedi
@paracon, would a general solution to this be to have processors refresh their caches upon receipt of an invalidation message? However, this may be quite expensive (in fact, wasteful) to do.
cluo1
Write through cache makes cache coherence protocol become so much simpler since read from cache does not need to broadcast any messages to other cores.
rrp123
Assuming the cache is write through is a major simplification, since most caches today are write back caches. Further, this is also very inefficient since every time a processor writes to a cache line, every other processor has to invalidate it's line and read again from memory. We see later that we can improve this by having the processor that wrote to that cache line, send the line to all other processors, thus reducing latency.
Firephinx
@chandana If two processors have to write to the value of X at the same time, whichever is able to grab the bus from the bus arbiter first wins and will broadcast the invalidation message to the other caches to drop the line. Afterwards, it has the right to modify X. Then when the second processor gets control of the bus, it can do the same and then modify X.
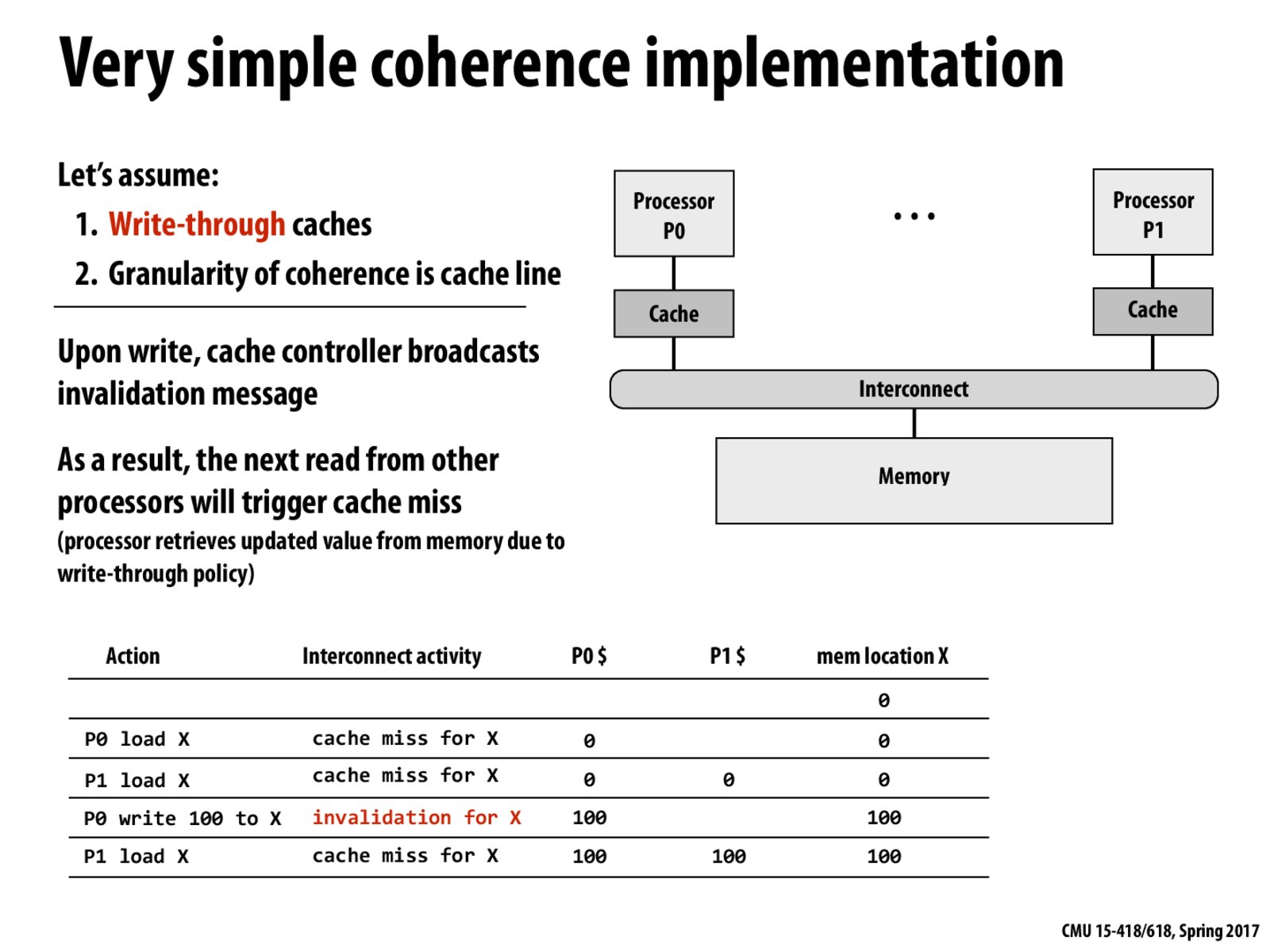
All of these caches are sending message / receiving message to each other, yelling through the interconnect. So when the "write" occurs, the "writer" cache will tell other caches to drop their content of the "written" cache line. As a result, next time P1 read, it will get the data from memory, and thus we can achieve memory coherence.
What is not ideal in this approach is that every single write will be write-through, and so it will fill the bandwidth very quickly.
Summary:
P0 loads X - cache miss, so X is loaded from memory.
P1 loads X - cache miss, so X is loaded from memory.
P0 write 100 to X: P1's copy of X is invalidated. Since it is a write-through cache, X is updated in memory.
P1 loads X: cache miss, so X is loaded from memory with the correct value.
Why are the messages simply invalidation messages? Would it not be more effective to instead send messages of the form "update X to 100"? I believe that this strategy would reduce a lot of the cache misses in the current strategy.
That might require more communication overhead though since you're sending more data right? So perhaps invalidation messages are more simple, faster, and require less data transfer.
What happens if two processors have to write to the value of X at the same time? Which processor writes to the value and which processor's cache drops the line?
@ayy_lmao, I think a cache coherence protocol that sends information of what was done to data to the bus is not a good idea. Firstly, more complex set of signals will be required to different operation - multiply, add, divide etc. which could potentially make decoding and encoding these signals slower. Secondly, the coherence protocol might need additions when the instruction set architecture is modified (in order to construct exact messages of data change)
@paracon, would a general solution to this be to have processors refresh their caches upon receipt of an invalidation message? However, this may be quite expensive (in fact, wasteful) to do.
Write through cache makes cache coherence protocol become so much simpler since read from cache does not need to broadcast any messages to other cores.
Assuming the cache is write through is a major simplification, since most caches today are write back caches. Further, this is also very inefficient since every time a processor writes to a cache line, every other processor has to invalidate it's line and read again from memory. We see later that we can improve this by having the processor that wrote to that cache line, send the line to all other processors, thus reducing latency.
@chandana If two processors have to write to the value of X at the same time, whichever is able to grab the bus from the bus arbiter first wins and will broadcast the invalidation message to the other caches to drop the line. Afterwards, it has the right to modify X. Then when the second processor gets control of the bus, it can do the same and then modify X.