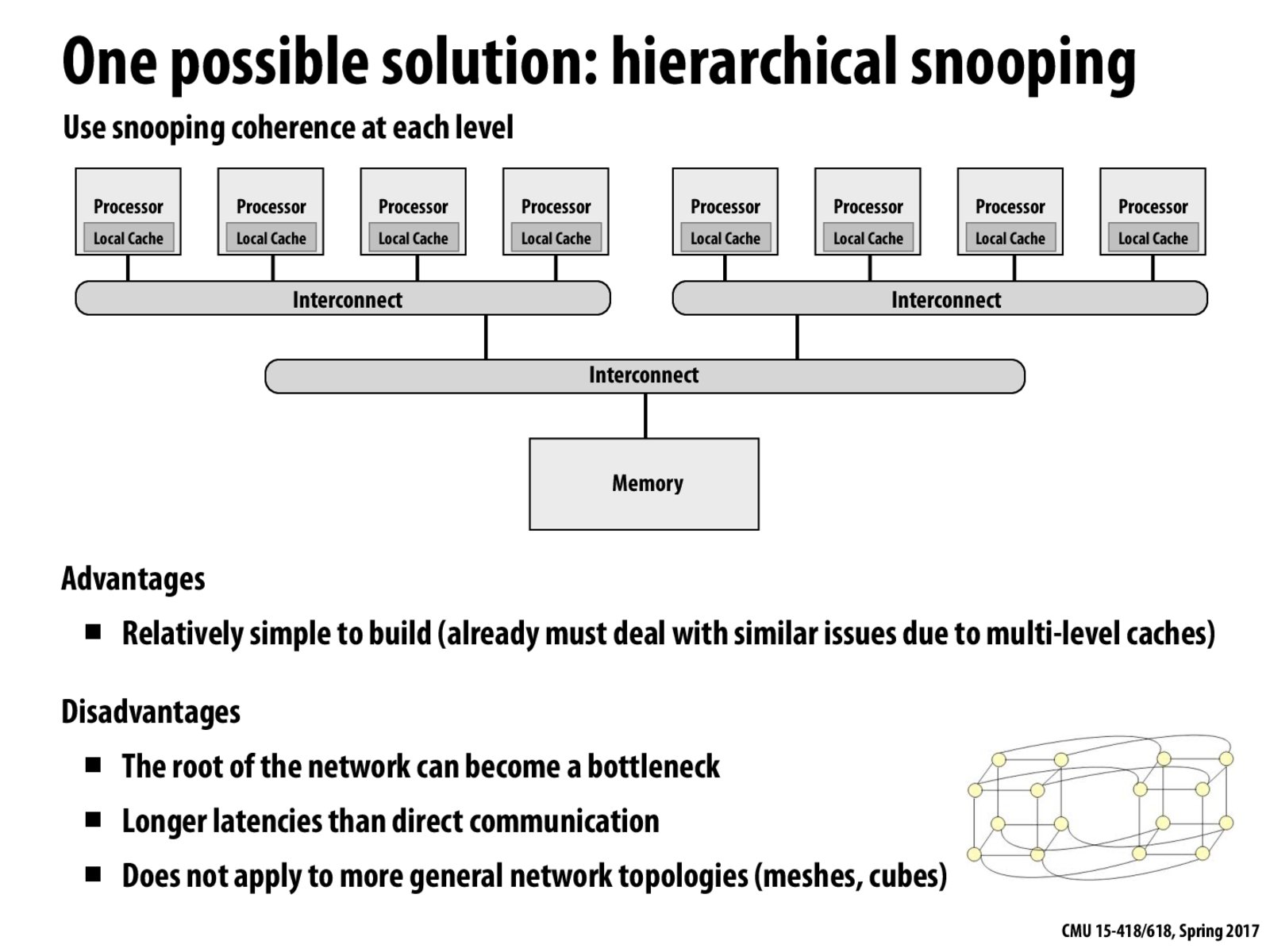
Hierarchical snooping has an advantage over regular snooping because instead of broadcasting to everyone at once, the processor does smaller broadcasts each time. If other processors on its level happen to have the cache line, then the processor doesn’t need to continue to broadcast to the next level of interconnects.
A disadvantage is that due to the way the processors are grouped, the traffic between levels can become congested because all of one level’s processors are using the same network to communicate. This is why the root of the network can become a bottleneck. Another disadvantage mentioned on this slide is that there are larger latencies than direct communication. One reason for this might be because there are extra steps to communicate; each processor has to send messages to the interconnect it is on as well as other interconnects (vs in regular snooping, the broadcast is just to everyone at once).
blah329
@pajamajama I'm a bit confused by this: "...the processor broadcasts to the processors on its interconnect. If other processors on the same interconnect have the cache line, then the processor doesn’t need to continue to broadcast to the next level.". Say a cache on the opposing interconnect had the cache line in the shared state, and so did a cache on the same interconnect as the a processor that wants exclusive access to the same cache line. Wouldn't it have to send an invalidation message to both interconnects? I guess I'm confused about how would it know if a cache on the opposing interconnect doesn't have the cache line that it's trying to modify?
pajamajama
@ blah329 I guess the way I worded it was kinda unclear. The advantage is that the processor doesn't have to broadcast to as many caches at one time as it would have if there wasn't a hierarchy. I think it still has to listen for whether processors outside its interconnect has the cache line (?) but it just doesn't have to keep broadcasting to the next level if it has already found that processors on its interconnect do have the cache line it wants exclusive access to. I updated my explanation above, so hopefully it's a little less confusing now. (But also I'm not super confident about this, so it'd be better if someone else confirmed).
Hierarchical snooping has an advantage over regular snooping because instead of broadcasting to everyone at once, the processor does smaller broadcasts each time. If other processors on its level happen to have the cache line, then the processor doesn’t need to continue to broadcast to the next level of interconnects.
A disadvantage is that due to the way the processors are grouped, the traffic between levels can become congested because all of one level’s processors are using the same network to communicate. This is why the root of the network can become a bottleneck. Another disadvantage mentioned on this slide is that there are larger latencies than direct communication. One reason for this might be because there are extra steps to communicate; each processor has to send messages to the interconnect it is on as well as other interconnects (vs in regular snooping, the broadcast is just to everyone at once).
@pajamajama I'm a bit confused by this: "...the processor broadcasts to the processors on its interconnect. If other processors on the same interconnect have the cache line, then the processor doesn’t need to continue to broadcast to the next level.". Say a cache on the opposing interconnect had the cache line in the shared state, and so did a cache on the same interconnect as the a processor that wants exclusive access to the same cache line. Wouldn't it have to send an invalidation message to both interconnects? I guess I'm confused about how would it know if a cache on the opposing interconnect doesn't have the cache line that it's trying to modify?
@ blah329 I guess the way I worded it was kinda unclear. The advantage is that the processor doesn't have to broadcast to as many caches at one time as it would have if there wasn't a hierarchy. I think it still has to listen for whether processors outside its interconnect has the cache line (?) but it just doesn't have to keep broadcasting to the next level if it has already found that processors on its interconnect do have the cache line it wants exclusive access to. I updated my explanation above, so hopefully it's a little less confusing now. (But also I'm not super confident about this, so it'd be better if someone else confirmed).