In this version, we first transposes B before doing other any computation. This way, we can take advantage of cache locality: An element in C is now equal to the dot product of a row in A with a row in B. (If we use the same method without transposing B, then, we would need a column of B. That would be bad for cache locality because we need to load one cache line per element.)
BestBunny
Pre-transposing the block of B also allows us to make use of SIMD capabilities in addition to cache locality while making sure that utilizing SIMD capabilities doesn't increase the size of our working set.
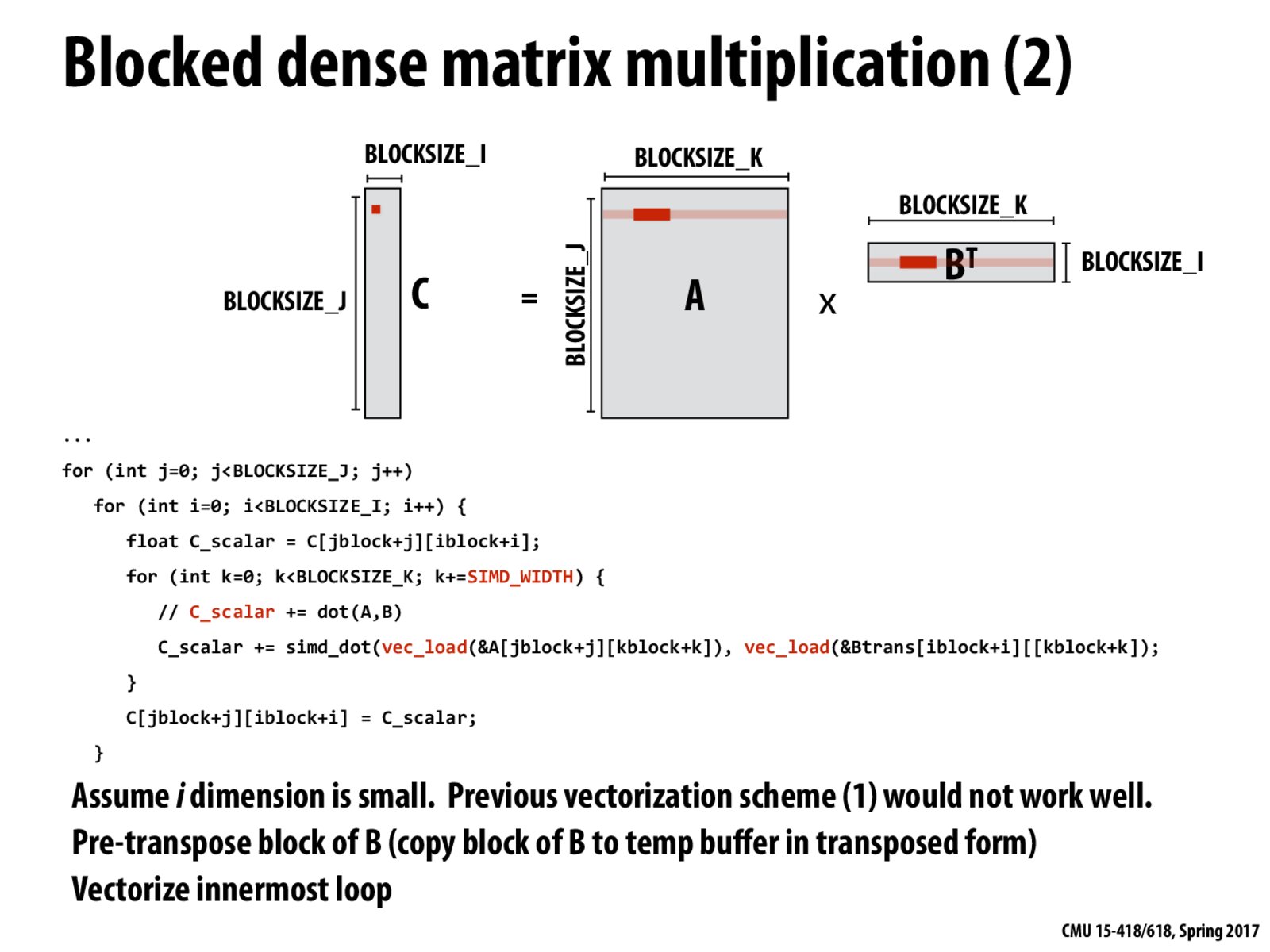
In this version, we first transposes B before doing other any computation. This way, we can take advantage of cache locality: An element in C is now equal to the dot product of a row in A with a row in B. (If we use the same method without transposing B, then, we would need a column of B. That would be bad for cache locality because we need to load one cache line per element.)
Pre-transposing the block of B also allows us to make use of SIMD capabilities in addition to cache locality while making sure that utilizing SIMD capabilities doesn't increase the size of our working set.