We now can take advantage of memory locality in A, B, and C instead of simply A and B in the previous slide.
mario
If written well, matrix multiplication can have the arithmetic intensity of O(block size).
kapalani
There are several optimized linear algebra libraries for pretty much every platform. Examples: cuBLAS, Eigen, LAPACK, Intel MKL, Armadillo, etc.
themj
For both A and B, you are loading in an entire vector of size SIMD_WIDTH allowing you to take advantage of SIMD-level parallelism. Why do you get SIMD_WIDTH*SIMD_WIDTH parallelism for C?
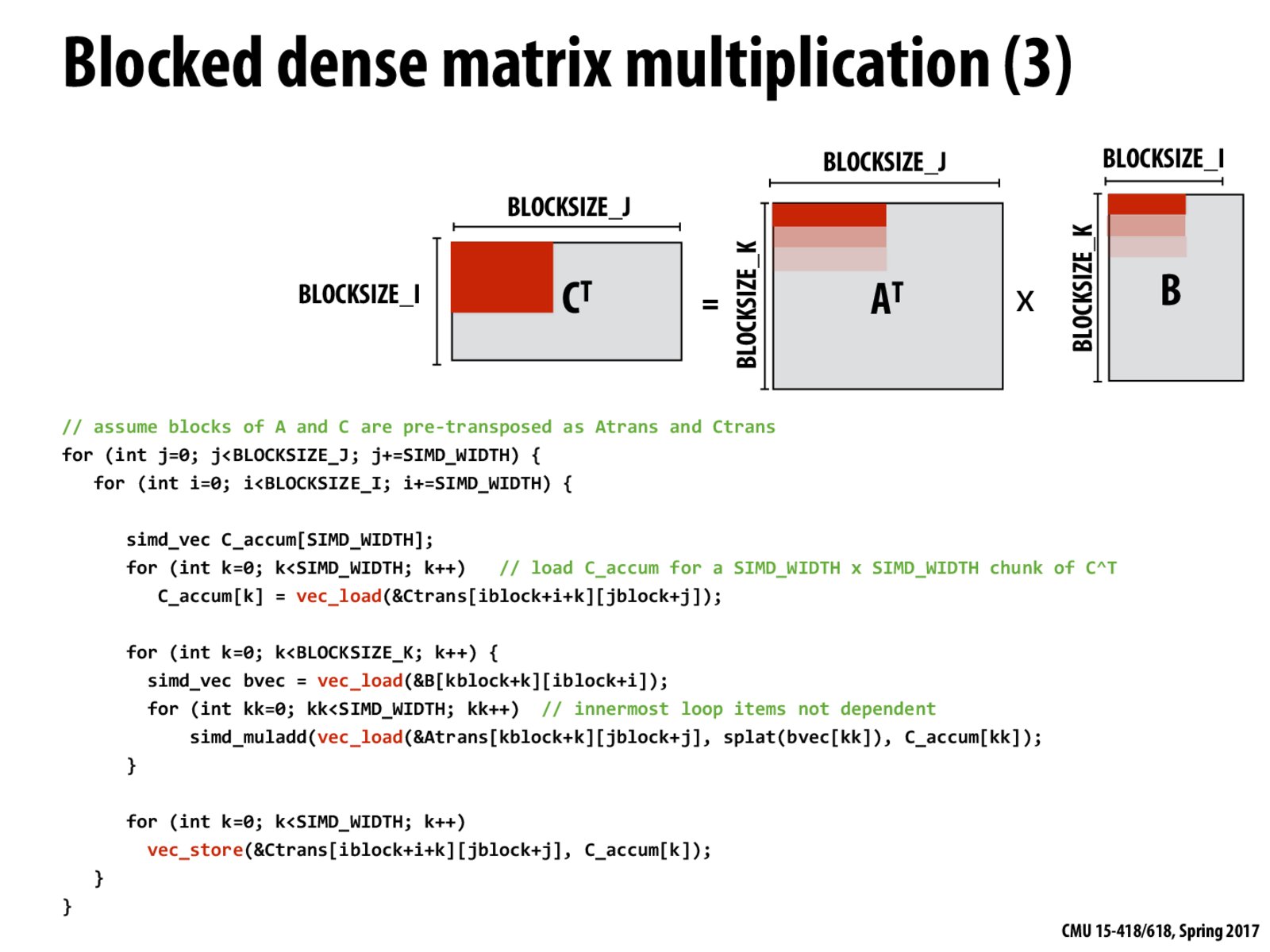
We now can take advantage of memory locality in A, B, and C instead of simply A and B in the previous slide.
If written well, matrix multiplication can have the arithmetic intensity of O(block size).
There are several optimized linear algebra libraries for pretty much every platform. Examples: cuBLAS, Eigen, LAPACK, Intel MKL, Armadillo, etc.
For both A and B, you are loading in an entire vector of size SIMD_WIDTH allowing you to take advantage of SIMD-level parallelism. Why do you get SIMD_WIDTH*SIMD_WIDTH parallelism for C?