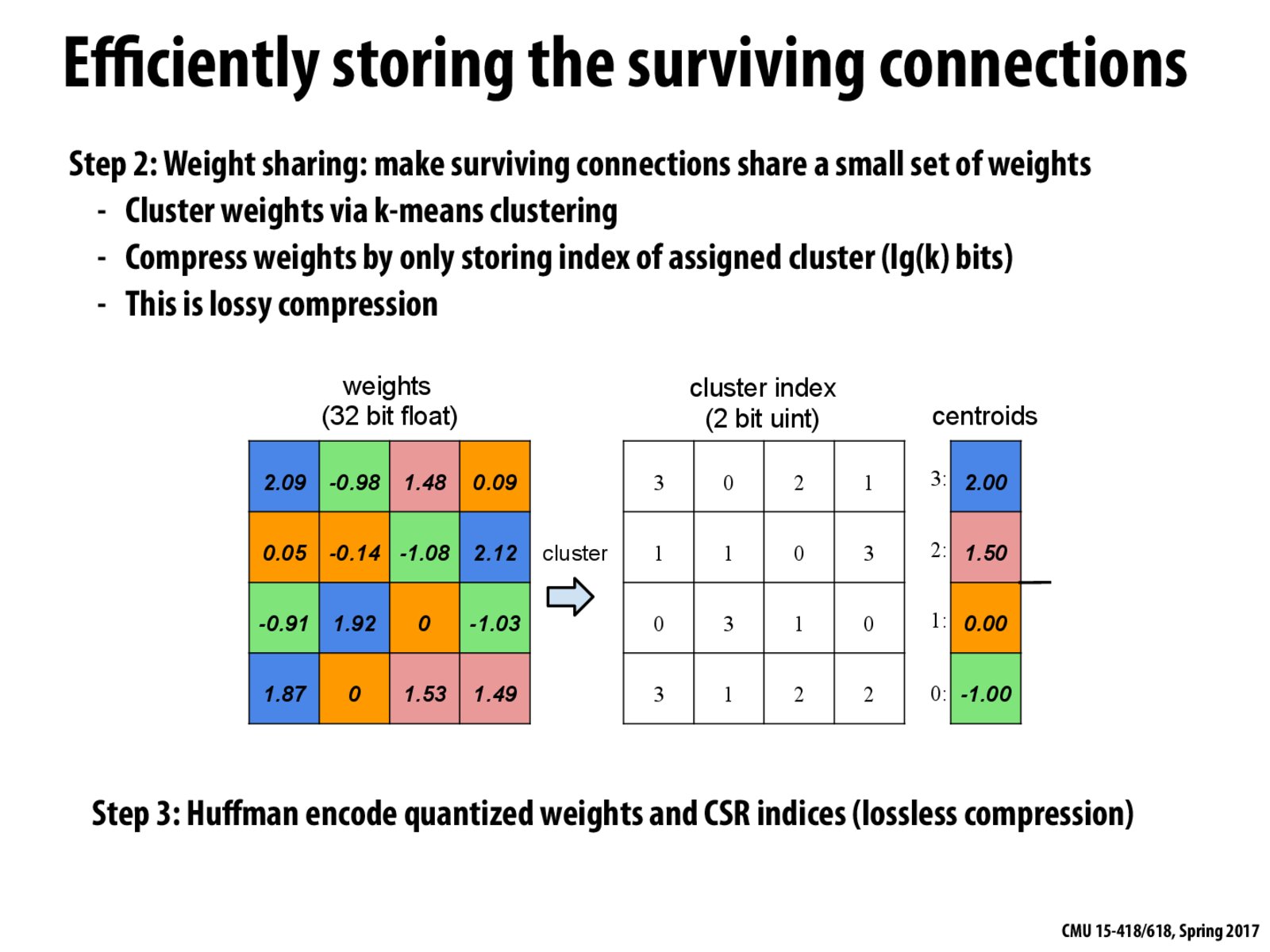
What exactly does it mean by 'lossy compression' ?
sampathchanda
Wiki says: "In information technology, lossy compression or irreversible compression is the class of data encoding methods that uses inexact approximations and partial data discarding to represent the content. These techniques are used to reduce data size for storage, handling, and transmitting content."
200
For lossy compression, the decompressed data is only an approximation of original data.
vasua
The optimizations being performed make a lot of sense for performing inference on the NN, since we're effectively removing connections which don't contribute much to the final output due to their low weight. However, if this process isn't applied during the inference at training time, doesn't that result in a potentially lower accuracy since the network will be trained using a complete, dense inference rather than this sparse, compressed inference?
kayvonf
@vasua. You're intuition is correct. If you take a look at the Han et al. paper (see "Deep Compression" in the readings for this lecture.) You'll see an iterative process of pruning, then re-training using the pruned structure.
One similar idea is to use low precision floats, such as float16, or even float8.
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. Han et al. ICLR 2016
Subsequent work developed an ASIC to efficiently handle the resulting sparsity.
EIE: Efficient Inference Engine on Compressed Deep Neural Network. Han et al. ISCA 2016
What exactly does it mean by 'lossy compression' ?
Wiki says: "In information technology, lossy compression or irreversible compression is the class of data encoding methods that uses inexact approximations and partial data discarding to represent the content. These techniques are used to reduce data size for storage, handling, and transmitting content."
For lossy compression, the decompressed data is only an approximation of original data.
The optimizations being performed make a lot of sense for performing inference on the NN, since we're effectively removing connections which don't contribute much to the final output due to their low weight. However, if this process isn't applied during the inference at training time, doesn't that result in a potentially lower accuracy since the network will be trained using a complete, dense inference rather than this sparse, compressed inference?
@vasua. You're intuition is correct. If you take a look at the Han et al. paper (see "Deep Compression" in the readings for this lecture.) You'll see an iterative process of pruning, then re-training using the pruned structure.