@chenh1 My guess is that sometimes the low weight connections may provide not-so-helpful information about non-dominant features, and the weights assigned to those connections are significant enough that, after propagating through many layers of the DNN, the result might be slightly changed. For instance, perhaps in slide 4 where it identified part of the woman's hair as a cat, maybe small areas of that region suggested it is similar to a cat (eg. hair, shape, color), so in the end these accumulate and it recognizes that area as cat. But in pruning those low-weight connections along the way, although it is lossy, it actually causes a more correct output. I'm sure there are plenty of cases where pruning low-weight connections causes more error, but I guess in their tests those cases didn't appear as often.
pagerank
The finding of @chenh1 is really interesting: pruned version can have a lower error rate than the original one. This reminds me of regularizations in the loss functions, which prevent overfitting by preferring simpler models. Also, it looks similar to "dropout", an interesting regularization technique for reducing overfitting by dropping out units in a neural network. Regularization during training is definitely different from dropping small weights in the evaluation, but I believe they may have some connections.
paracon
Though we are compute bound, it makes sense to have compression/decompression to reduce energy consumption.
googlebleh
To elaborate on @paracon's comment, being compute bound doesn't have much to do with the motivation for using compression. It is simply because the energy required to store the uncompressed graph for the duration it is in memory outweighs the energy needed to quickly decompress it when it needs to be used.
googlebleh
If latency of decompressing the data is holding back performance, some systems can choose to implement it in hardware. Here's an example, which claims that the difference in latency to uncompressed memory is negligible.
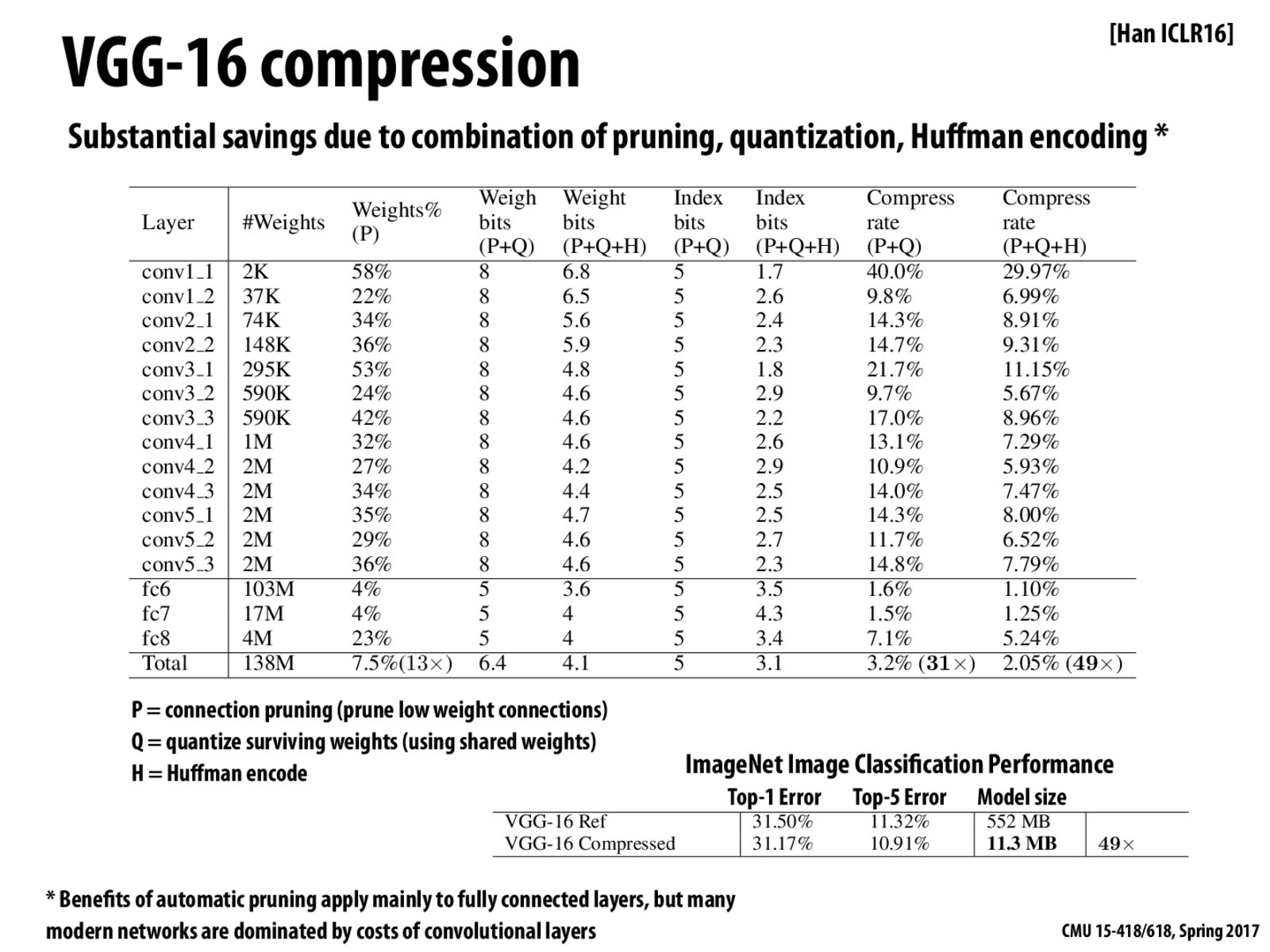
Why the compressed version has lower error?
@chenh1 My guess is that sometimes the low weight connections may provide not-so-helpful information about non-dominant features, and the weights assigned to those connections are significant enough that, after propagating through many layers of the DNN, the result might be slightly changed. For instance, perhaps in slide 4 where it identified part of the woman's hair as a cat, maybe small areas of that region suggested it is similar to a cat (eg. hair, shape, color), so in the end these accumulate and it recognizes that area as cat. But in pruning those low-weight connections along the way, although it is lossy, it actually causes a more correct output. I'm sure there are plenty of cases where pruning low-weight connections causes more error, but I guess in their tests those cases didn't appear as often.
The finding of @chenh1 is really interesting: pruned version can have a lower error rate than the original one. This reminds me of regularizations in the loss functions, which prevent overfitting by preferring simpler models. Also, it looks similar to "dropout", an interesting regularization technique for reducing overfitting by dropping out units in a neural network. Regularization during training is definitely different from dropping small weights in the evaluation, but I believe they may have some connections.
Though we are compute bound, it makes sense to have compression/decompression to reduce energy consumption.
To elaborate on @paracon's comment, being compute bound doesn't have much to do with the motivation for using compression. It is simply because the energy required to store the uncompressed graph for the duration it is in memory outweighs the energy needed to quickly decompress it when it needs to be used.
If latency of decompressing the data is holding back performance, some systems can choose to implement it in hardware. Here's an example, which claims that the difference in latency to uncompressed memory is negligible.