Sharding is one solution to reduce contention on a parameter server.
nemo
Another solution is that each parameter server communicates with a fixed set of worker nodes and the parameter servers communicate with each other to maintain consistent values! But I think sharding is a better solution here.
bjay
Is the communication overhead between nodes negligible in the case of training deep networks?
googlebleh
@bjay Of course it depends on how you write your code. What it comes down to is the ratio of how much time you spend communicating data to how much time you spend working on the data. This is why you'd want to make sure you're not communicating too much too often unless you're about to spend a comparably long time doing some computation on that data.
googlebleh
Now if you really have to pass some data around and the communication overhead starts to become noticeable, then you might investigate to see if you're able to hide the communication latency by working on some other data in parallel (i.e. pipeline).
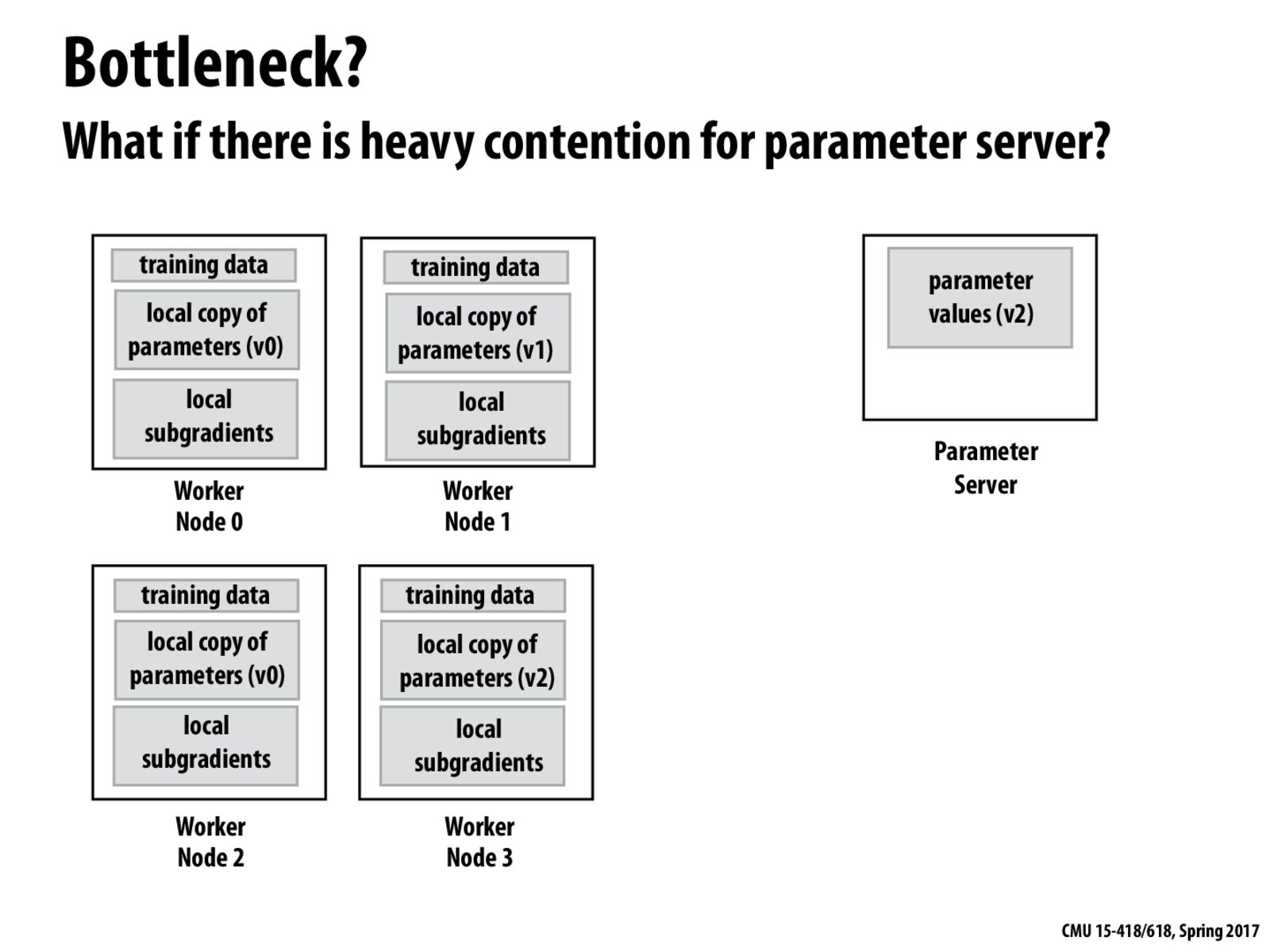
Sharding is one solution to reduce contention on a parameter server.
Another solution is that each parameter server communicates with a fixed set of worker nodes and the parameter servers communicate with each other to maintain consistent values! But I think sharding is a better solution here.
Is the communication overhead between nodes negligible in the case of training deep networks?
@bjay Of course it depends on how you write your code. What it comes down to is the ratio of how much time you spend communicating data to how much time you spend working on the data. This is why you'd want to make sure you're not communicating too much too often unless you're about to spend a comparably long time doing some computation on that data.
Now if you really have to pass some data around and the communication overhead starts to become noticeable, then you might investigate to see if you're able to hide the communication latency by working on some other data in parallel (i.e. pipeline).