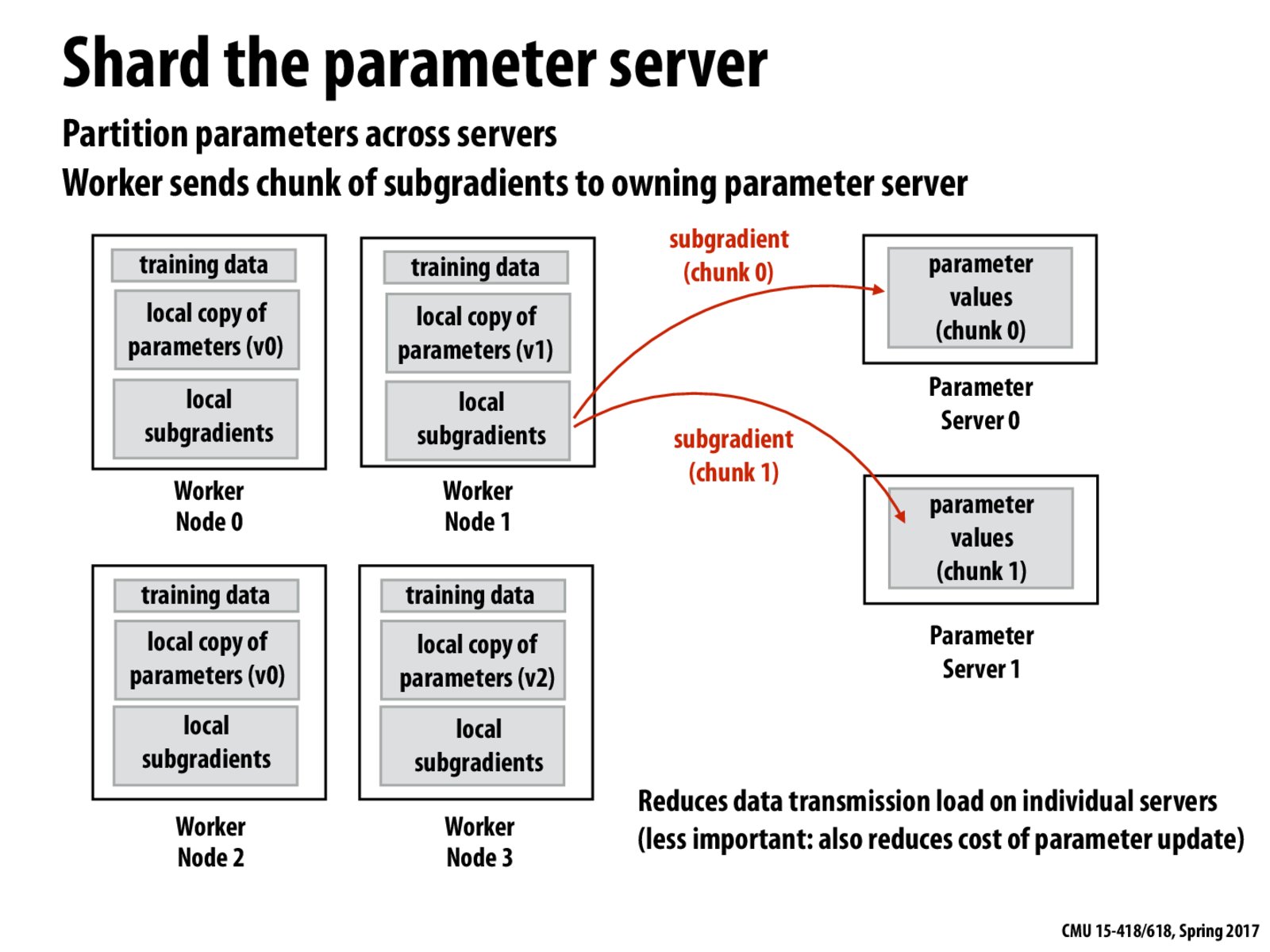
How does sharding the parameters solve the contention problem? All the workers still need to talk to all the parameter servers?
BestBunny
I believe the idea is that although all the workers still need to talk to all the parameter servers, each parameter server receives less data from each of the worker nodes. The contention mentioned on the previous slide is on the parameter server side (due to receiving too much data) rather than on the worker node side (only sending one bulk message per gradient update).
kayvonf
@maddy. @BestBunny is correct. Half as much data is sent to each shard of the parameter server in this setup!
ask
Twice the number of messages is sent in this sharded model. However, the message overheads are negligible when the size of data being passed around is huge.
sherwood
Another solution to solve network contention is to simply delay the time when each worker sends subgradient to parameter server
sadkins
Network contention is to be expected when training a neural network especially because of the fully connected layer. Each node from layer n is connected to each node in layer n+1, so there are a lot of things trying to access the same data
How does sharding the parameters solve the contention problem? All the workers still need to talk to all the parameter servers?
I believe the idea is that although all the workers still need to talk to all the parameter servers, each parameter server receives less data from each of the worker nodes. The contention mentioned on the previous slide is on the parameter server side (due to receiving too much data) rather than on the worker node side (only sending one bulk message per gradient update).
@maddy. @BestBunny is correct. Half as much data is sent to each shard of the parameter server in this setup!
Twice the number of messages is sent in this sharded model. However, the message overheads are negligible when the size of data being passed around is huge.
Another solution to solve network contention is to simply delay the time when each worker sends subgradient to parameter server
Network contention is to be expected when training a neural network especially because of the fully connected layer. Each node from layer n is connected to each node in layer n+1, so there are a lot of things trying to access the same data