This is the similar strategy as in the renderer assignment when we processed data in chunks to stay within the GPU cache.
Master
Compared to previous methods, this approach limits the memory footprint, which makes tmp_buf (three rows of data) will fit in cache, making full use of locality. The main problem here is that rows in the middle will have to be recomputed three times.
metainf
The problem with the previous algorithm is that the intermediate buffer used to store the partially computed values increases the bandwidth requirement by a factor of 2. In this method, we make the tmp_buf only of height 3 so that it can fit into the cache, but in doing so, we triple the number of computations in the first step, as each row will be computed three times, each in a different tmp_buf row.
rrp123
This is revisited once again in the DRAM lecture, where we try to ensure that all our memory accesses stay in cache rather than go out to main memory. In this case, we're trying to ensure that our buffer is stored in cache so that there is much lower latency in retrieving the elements of the horizontal blur.
unparalleled
We are also throwing away computation of the 2 rows we did, which would be useful to calculate the subsequent rows of the image.
sushi
This method increases the arithmetic density from to 3 ops/load to 4 ops/load. But it actually increases the work needed for computing one row from 6 * WIDTH to 12 * WIDTH. This method will not increase performance if the original problem is compute-bounding.
albusshin
We can save the 2 rows of the previous horizontal blurring computation for later computation of the vertical blurring.
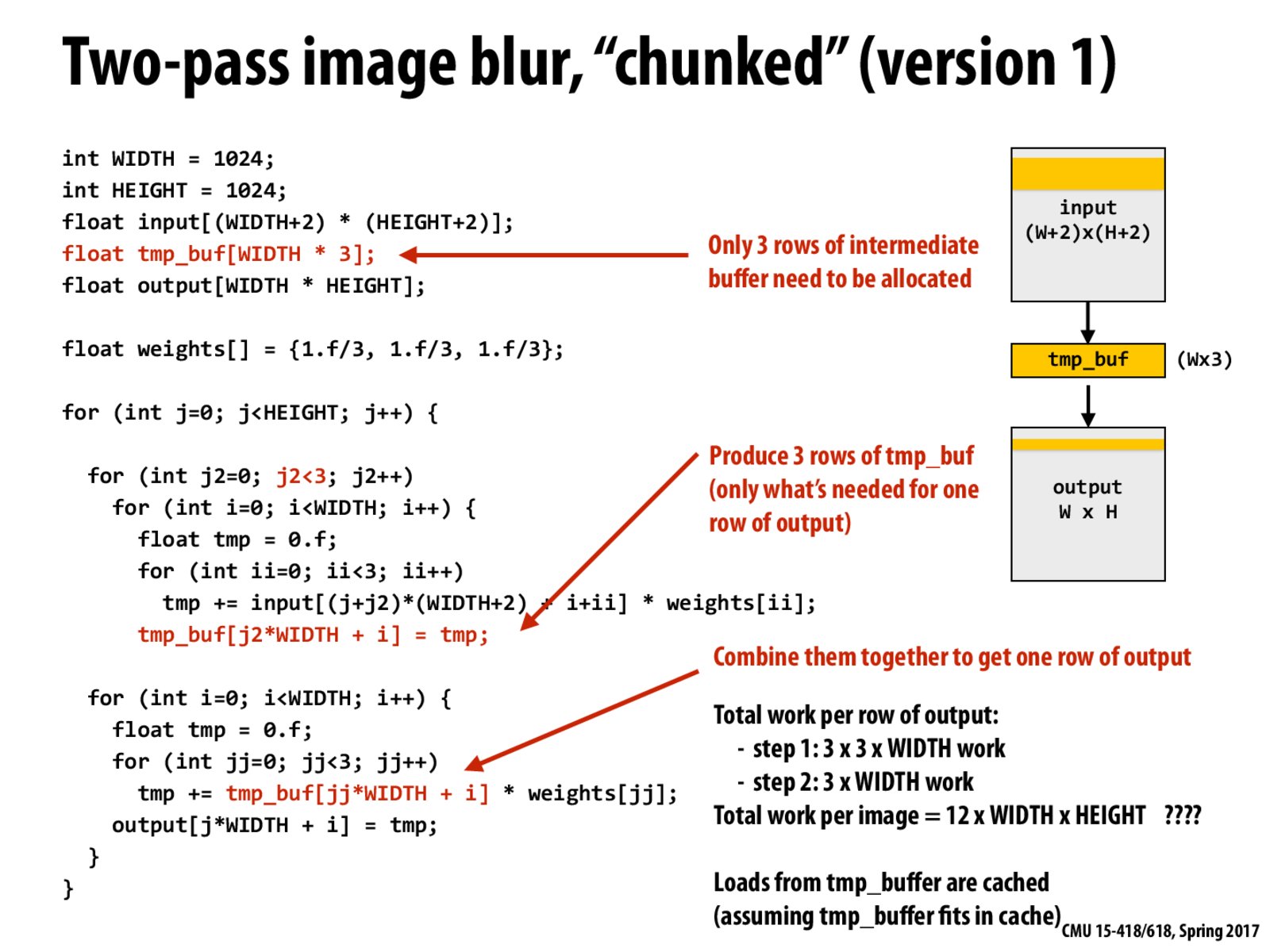
This is the similar strategy as in the renderer assignment when we processed data in chunks to stay within the GPU cache.
Compared to previous methods, this approach limits the memory footprint, which makes tmp_buf (three rows of data) will fit in cache, making full use of locality. The main problem here is that rows in the middle will have to be recomputed three times.
The problem with the previous algorithm is that the intermediate buffer used to store the partially computed values increases the bandwidth requirement by a factor of 2. In this method, we make the tmp_buf only of height 3 so that it can fit into the cache, but in doing so, we triple the number of computations in the first step, as each row will be computed three times, each in a different tmp_buf row.
This is revisited once again in the DRAM lecture, where we try to ensure that all our memory accesses stay in cache rather than go out to main memory. In this case, we're trying to ensure that our buffer is stored in cache so that there is much lower latency in retrieving the elements of the horizontal blur.
We are also throwing away computation of the 2 rows we did, which would be useful to calculate the subsequent rows of the image.
This method increases the arithmetic density from to 3 ops/load to 4 ops/load. But it actually increases the work needed for computing one row from 6 * WIDTH to 12 * WIDTH. This method will not increase performance if the original problem is compute-bounding.
We can save the 2 rows of the previous horizontal blurring computation for later computation of the vertical blurring.