In this version, the program tries to make full use of the cache. The larger the chunk size, the lesser recomputation.
ykt
We need to make sure that tmp_buf fits in cache. If it ends up being larger, then we will have a lot of capacity misses.
hdd
This is a scenario where the algorithm is modified to fit into the cache line. Hence instead of allocating temp completely for the image size ( which may not fit in cache ) it is allocated for the size of the cache. So this provides maximum locality for the program. Along with that we also have excellent producer consumer locality since the temp that is generated from first image conv. is consumed in the second image conv all written within a function moving be a size of chunk size across height of the image.
fxffx
In the chunked version, during each iteration the program will only access a chunk of data, where the data can be fit in cache. Therefore, the memory access time will be significantly reduce.
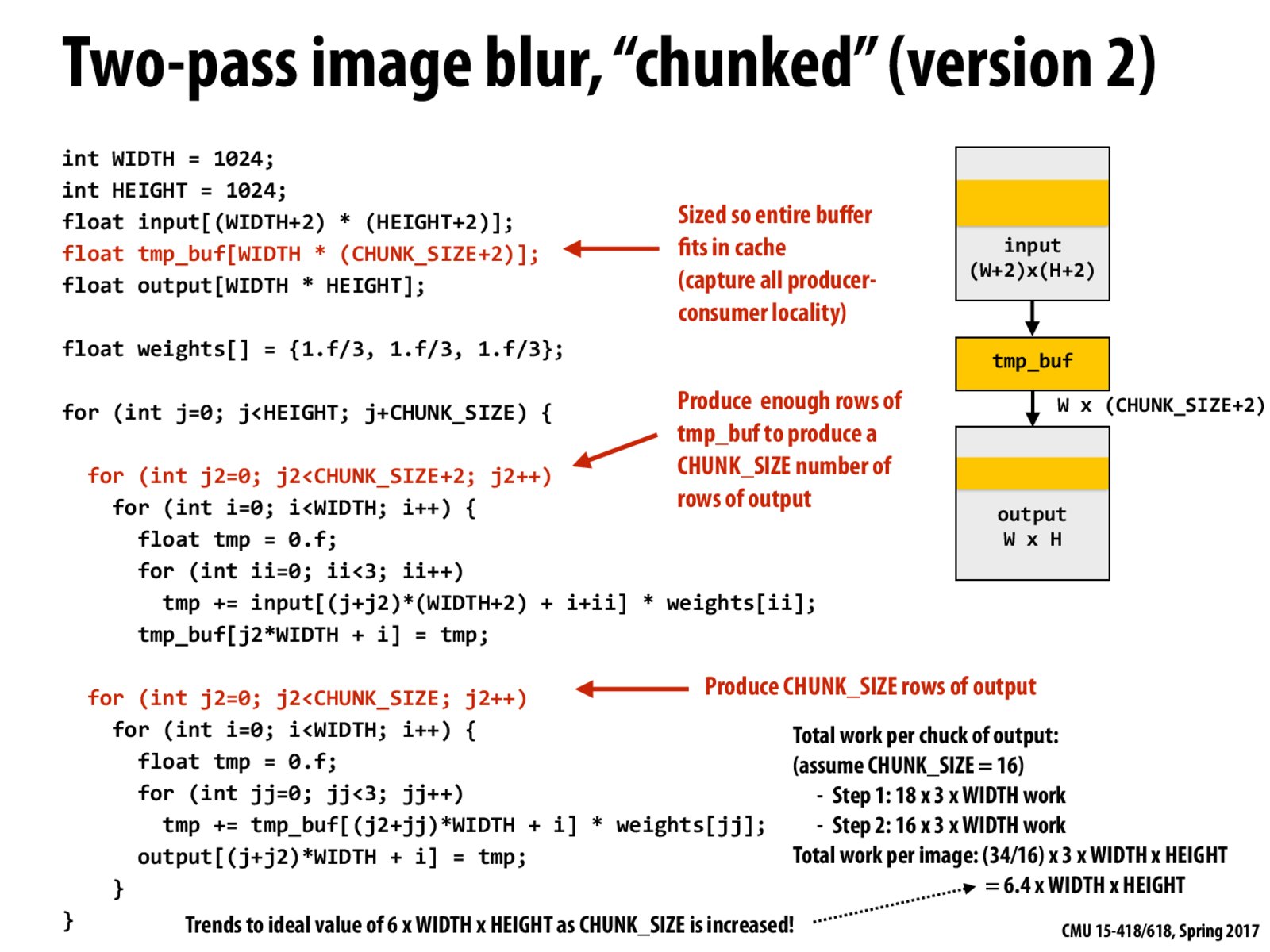
In this version, the program tries to make full use of the cache. The larger the chunk size, the lesser recomputation.
We need to make sure that tmp_buf fits in cache. If it ends up being larger, then we will have a lot of capacity misses.
This is a scenario where the algorithm is modified to fit into the cache line. Hence instead of allocating temp completely for the image size ( which may not fit in cache ) it is allocated for the size of the cache. So this provides maximum locality for the program. Along with that we also have excellent producer consumer locality since the temp that is generated from first image conv. is consumed in the second image conv all written within a function moving be a size of chunk size across height of the image.
In the chunked version, during each iteration the program will only access a chunk of data, where the data can be fit in cache. Therefore, the memory access time will be significantly reduce.