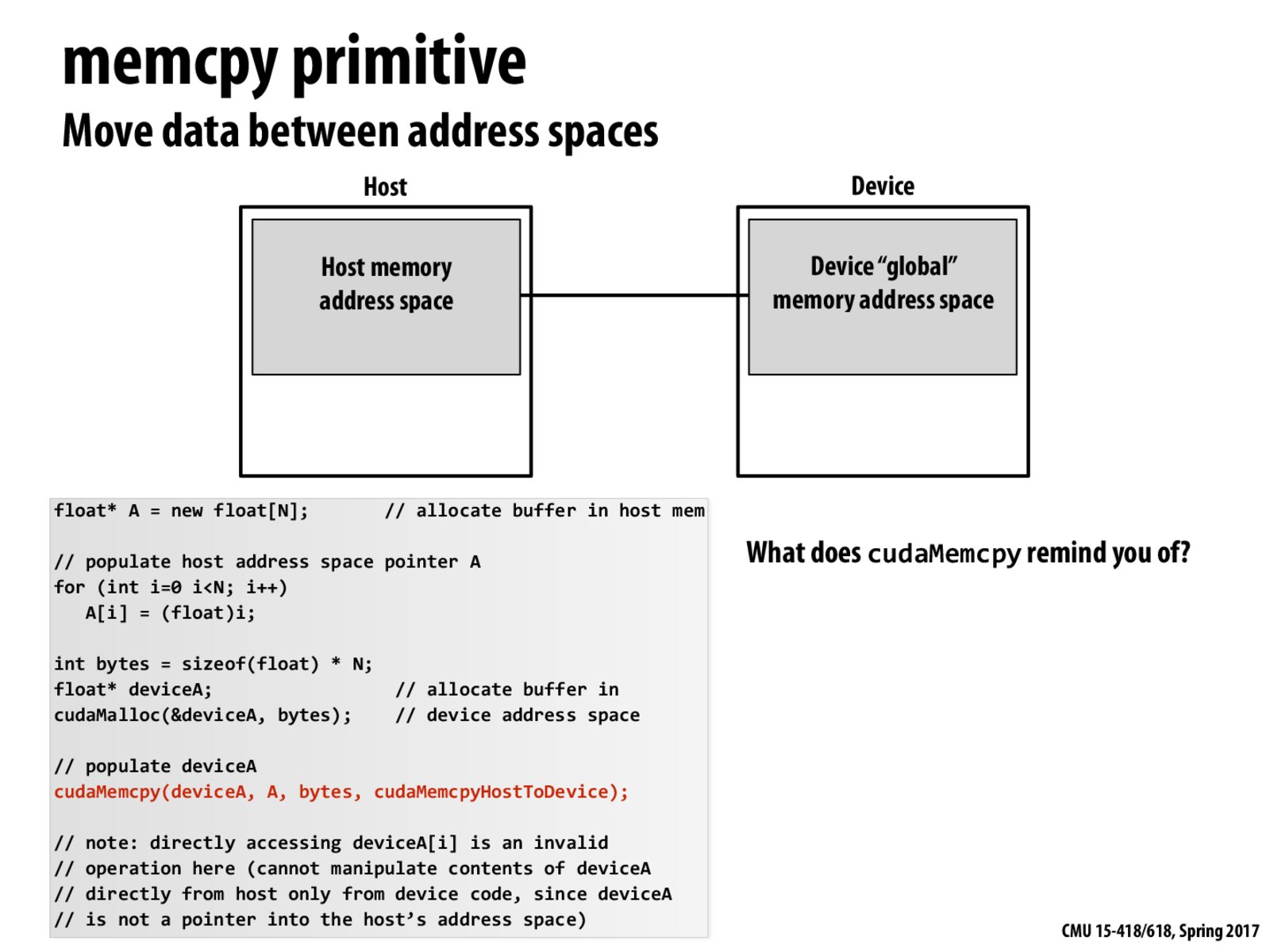
cudaMemcpy is like one big message being sent to the GPU.
bazinga
If the C program directly dereferences deviceA[i], it may lead to seg fault or return garbage since its part of the GPU's address space rather than the CPU's address space.
Also, cudaMemcpy reminds us of the message passing model to share data across different address spaces.
amg
Is there a reason cudaMemcpyHostToDevice is optional? It seems that the direction to copy should be obvious at runtime given two pointers to different address spaces. When would you want or need to specify direction?
Copies count bytes from the memory area pointed to by src to the memory area pointed to by dst, where kind specifies the direction of the copy, and must be one of cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, or cudaMemcpyDefault. Passing cudaMemcpyDefault is recommended, in which case the type of transfer is inferred from the pointer values. However, cudaMemcpyDefault is only allowed on systems that support unified virtual addressing. Calling cudaMemcpy() with dst and src pointers that do not match the direction of the copy results in an undefined behavior.
holard
How does the cost of the cudaMemcpy operation compare to things like memory latency and synchronization overheads in other parallel frameworks?
-o4
CUDA 6 introduces unified memory. That means there is a certain amount of memory that is managed by the system and developer can pretty much treat them as accessible from both CPU and GPU. More details here
ZoSo
More clarity on global and shared memory in CUDA can be found here
rsvaidya
Now that there is Unified Memory in CUDA 6 and above, we would still want to use the cudaMemcpy operations as an optimization. Since we as programmers would know the data which will be needed by GPU and if we transfer it specifically to GPU it will be nearer to GPU and improve performance.
sreevisp
In addition to unified memory from CUDA 6, unified virtual addressing has been available since CUDA 4, which allows a GPU to access pointers from other GPUs or host memory. This functionality is not as powerful as unified memory, but was an important stepping stone.
Should we compute the actual address like deviceA + i?
mario
I don't think you're supposed to use deviceA in the host code. I believe that it is only used for the GPU functions.
tkli
deviceA might be used in host code in order to access a value in the array. I believe using cudaMemcpy on deviceA + i is the correct way of reading/writing to this value.
SR_94
Correct me if I am wrong but I think we can we access the device pointers from host if we are using unified memory otherwise the only way to access device memory from host is to copy it back to the host.
cudaMemcpy is like one big message being sent to the GPU.
If the C program directly dereferences deviceA[i], it may lead to seg fault or return garbage since its part of the GPU's address space rather than the CPU's address space.
Also, cudaMemcpy reminds us of the message passing model to share data across different address spaces.
Is there a reason
cudaMemcpyHostToDeviceis optional? It seems that the direction to copy should be obvious at runtime given two pointers to different address spaces. When would you want or need to specify direction?Wasn't 100% sure, so I had to look it up. From the CUDA runtime API documentation...
Copies count bytes from the memory area pointed to by src to the memory area pointed to by dst, where kind specifies the direction of the copy, and must be one of cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, or cudaMemcpyDefault. Passing cudaMemcpyDefault is recommended, in which case the type of transfer is inferred from the pointer values. However, cudaMemcpyDefault is only allowed on systems that support unified virtual addressing. Calling cudaMemcpy() with dst and src pointers that do not match the direction of the copy results in an undefined behavior.
How does the cost of the cudaMemcpy operation compare to things like memory latency and synchronization overheads in other parallel frameworks?
CUDA 6 introduces unified memory. That means there is a certain amount of memory that is managed by the system and developer can pretty much treat them as accessible from both CPU and GPU. More details here
More clarity on global and shared memory in CUDA can be found here
Now that there is Unified Memory in CUDA 6 and above, we would still want to use the cudaMemcpy operations as an optimization. Since we as programmers would know the data which will be needed by GPU and if we transfer it specifically to GPU it will be nearer to GPU and improve performance.
In addition to unified memory from CUDA 6, unified virtual addressing has been available since CUDA 4, which allows a GPU to access pointers from other GPUs or host memory. This functionality is not as powerful as unified memory, but was an important stepping stone.
More on UVA here.
How should we address "deviceA[i]"?
Should we compute the actual address like deviceA + i?
I don't think you're supposed to use deviceA in the host code. I believe that it is only used for the GPU functions.
deviceA might be used in host code in order to access a value in the array. I believe using cudaMemcpy on deviceA + i is the correct way of reading/writing to this value.
Correct me if I am wrong but I think we can we access the device pointers from host if we are using unified memory otherwise the only way to access device memory from host is to copy it back to the host.