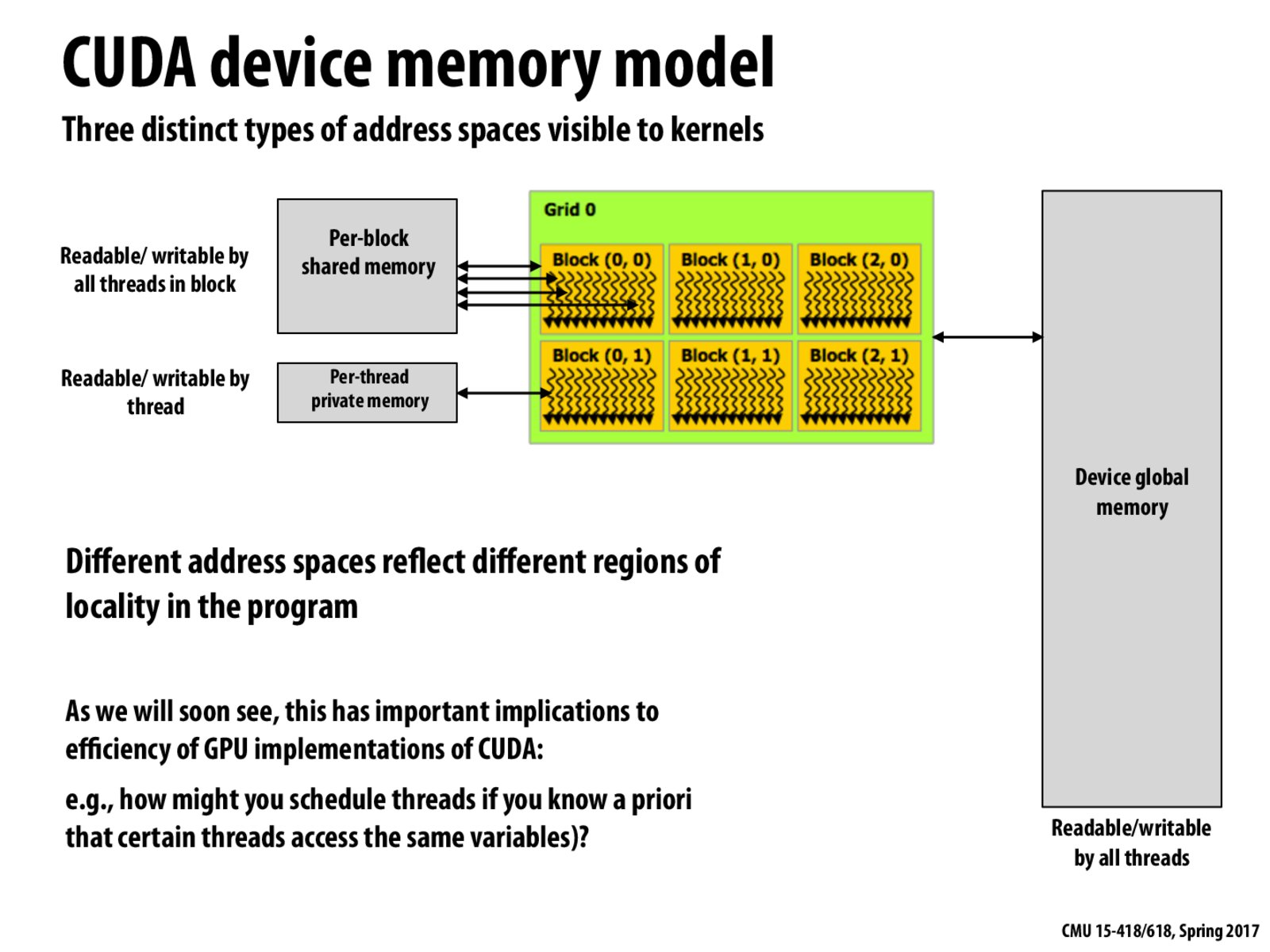
"Having different address spaces simplifies the assignment of threads, since not all memory has to be accessible to all threads." I'm not sure I understand how this works.
bazinga
I think it would simplify synchronization across threads. For example, threads in different thread-blocks do not have to worry about locking accesses to block-level shared data.
BestBunny
@khans I believe the question on the slide is linked to your comment. If we know that certain threads access the same variables, then these threads can be assigned to the same core or same chip at which point the fast-access on chip memory described on Slide 55 can be used for the memory that needs to be shared across these threads. By doing so, we prevent the cost of unnecessarily accessing DRAM since the data didn't have to be accessible to all the threads in the first place.
cwchang
@BestBunny: If certain threads access the same variables, why don't we just put them on the same block instead? That way, the variable being accessed can be stored on the share memory per block. Wouldn't that be a more efficient way?
BestBunny
My understanding is that threads in a block are assigned together due to the dynamic scheduling policy that respects resource requirements as also mentioned on slide 55, so they would typically be put together on the same core or chip which further enables utilization of the previously mentioned fast-access chip memory.
But then that leads me to the question of: what if the warps necessary to execute a particular block are not accessible within one core/chip but only across multiple cores/chips? So then, does the location of the block-shared memory change based on the scheduling of the threads in a block (within one core vs. across multiple cores)?
whitelez
@BestBunny: I think this slide could explain your question Slide 57. The warps will access the data from the shared memory of all warps (if data existed), or it will just fetch the data for its own purpose. However, I think if it really have this problem, then the better solution will be fixing the code, since it is clearly not efficient.
ykt
From what I've understood, one thread block has to be assigned to a single core, a major reason being that all the threads within a block need to be able to access the same shared memory. If a thread block cannot be allocated to any single core, then the block distribution would fail.
sandeep6189
It says that only three types of address space are visible to kernels. Shouldn't it be 4? i.e, i) individual memory block per thread ii) Shared memory for entire thread block iii) Special memory pool localised for a group of threads iv) global memory accessible to all GPU cores? Are my assumptions correct ?
"Having different address spaces simplifies the assignment of threads, since not all memory has to be accessible to all threads." I'm not sure I understand how this works.
I think it would simplify synchronization across threads. For example, threads in different thread-blocks do not have to worry about locking accesses to block-level shared data.
@khans I believe the question on the slide is linked to your comment. If we know that certain threads access the same variables, then these threads can be assigned to the same core or same chip at which point the fast-access on chip memory described on Slide 55 can be used for the memory that needs to be shared across these threads. By doing so, we prevent the cost of unnecessarily accessing DRAM since the data didn't have to be accessible to all the threads in the first place.
@BestBunny: If certain threads access the same variables, why don't we just put them on the same block instead? That way, the variable being accessed can be stored on the share memory per block. Wouldn't that be a more efficient way?
My understanding is that threads in a block are assigned together due to the dynamic scheduling policy that respects resource requirements as also mentioned on slide 55, so they would typically be put together on the same core or chip which further enables utilization of the previously mentioned fast-access chip memory.
But then that leads me to the question of: what if the warps necessary to execute a particular block are not accessible within one core/chip but only across multiple cores/chips? So then, does the location of the block-shared memory change based on the scheduling of the threads in a block (within one core vs. across multiple cores)?
@BestBunny: I think this slide could explain your question Slide 57. The warps will access the data from the shared memory of all warps (if data existed), or it will just fetch the data for its own purpose. However, I think if it really have this problem, then the better solution will be fixing the code, since it is clearly not efficient.
From what I've understood, one thread block has to be assigned to a single core, a major reason being that all the threads within a block need to be able to access the same shared memory. If a thread block cannot be allocated to any single core, then the block distribution would fail.
It says that only three types of address space are visible to kernels. Shouldn't it be 4? i.e, i) individual memory block per thread ii) Shared memory for entire thread block iii) Special memory pool localised for a group of threads iv) global memory accessible to all GPU cores? Are my assumptions correct ?