Question 1: At this point in the example (after four thread blocks have been assigned to cores), the scheduler can no longer assign thread blocks to cores. Why not? What must occur before block 4 can be assigned.
Question 2: Would it have been a valid scheduling policy for the GPU to reverse the order in which thread blocks are assigned to processors? E.g., first assign block 999, then 998, ... (or even assign blocks to core in random order)
nemo
Block 4 cannot be assigned because the binary file contains that each block needs 520 bytes of shared memory. The scheduler will check for this amount of memory, and as it is not available currently (1536 - 2*520 = 496 < 520), it won't assign block 4 to any of the cores. As soon as any of the 4 blocks (0-3) finish execution, memory will be available and block 4 will be assigned.
Yes, any scheduling policy would be valid. The thread blocks can be scheduled in any order.
I have a question. It is mentioned that each block must execute 128 threads. Each core can execute only 32 threads simultaneously. In slide 75 we learn that THREADS_PER_BLK cannot be more than the number of threads a core can run at once. So, this should give a compile-time error? Is there something I am missing?
Update - I think I get it. By 'execution on one core at once', it means that it should be able to assign execution contexts to all the CUDA threads in a block, and simultaneous execution is not mandatory. That actually makes sense and explains the deadlock argument we discuss in slide 75.
pagerank
I agree with @nemo 's answers to the two questions, and the explanation to herself/himself's question.
sstritte
At this point the scheduler can no longer assign thread blocks to cores because although we have enough execution context, we do not have enough shared memory available to support the allocation. So, the scheduler must wait until one of the running thread blocks completes. At that point, the scheduler can use those newly available resources to run block 4.
koala
For question 2, we can assign the thread blocks because we can assume that there are no dependencies. However, we cannot break up each block since the threads in each block may communicate with each other through shared memory.
lfragago
I agree with nemo in question 1. Only because the code in the kernel specifies the use of shared memory of size 520 bytes for each block we can't assign more than two blocks in an execution context. However, if we had not declared the use of shared memory in each block, then we could have assigned much more blocks per execution context!
rrudolph
In assignment 2, we faced a tradeoff of how much shared memory to use in each thread block, vs how many contexts could be assigned to each core.
pajamajama
I agree with the answers to the questions given above. To reiterate, for question 1, the scheduler can no longer assign thread blocks to cores because there is insufficient shared memory space to support allocation for a third block. Note that this occurs because we allocated 520 bytes of shared memory; if we didn't need to allocate the 520 bytes of shared mem, we'd be able to fit 3 blocks on a core because (128 threads for a block to execute * 3 blocks) = 384 threads and the execution context has storage space for 384 threads.
For question 2, the GPU can schedule blocks in any order. As long as there are resources available, thread blocks can be scheduled. Once the resources run out, the scheduler must wait until one of the thread blocks completes execution (in this case, any of the blocks 0 - 3) before continuing on to assign the next block (block 4) with the newly available memory.
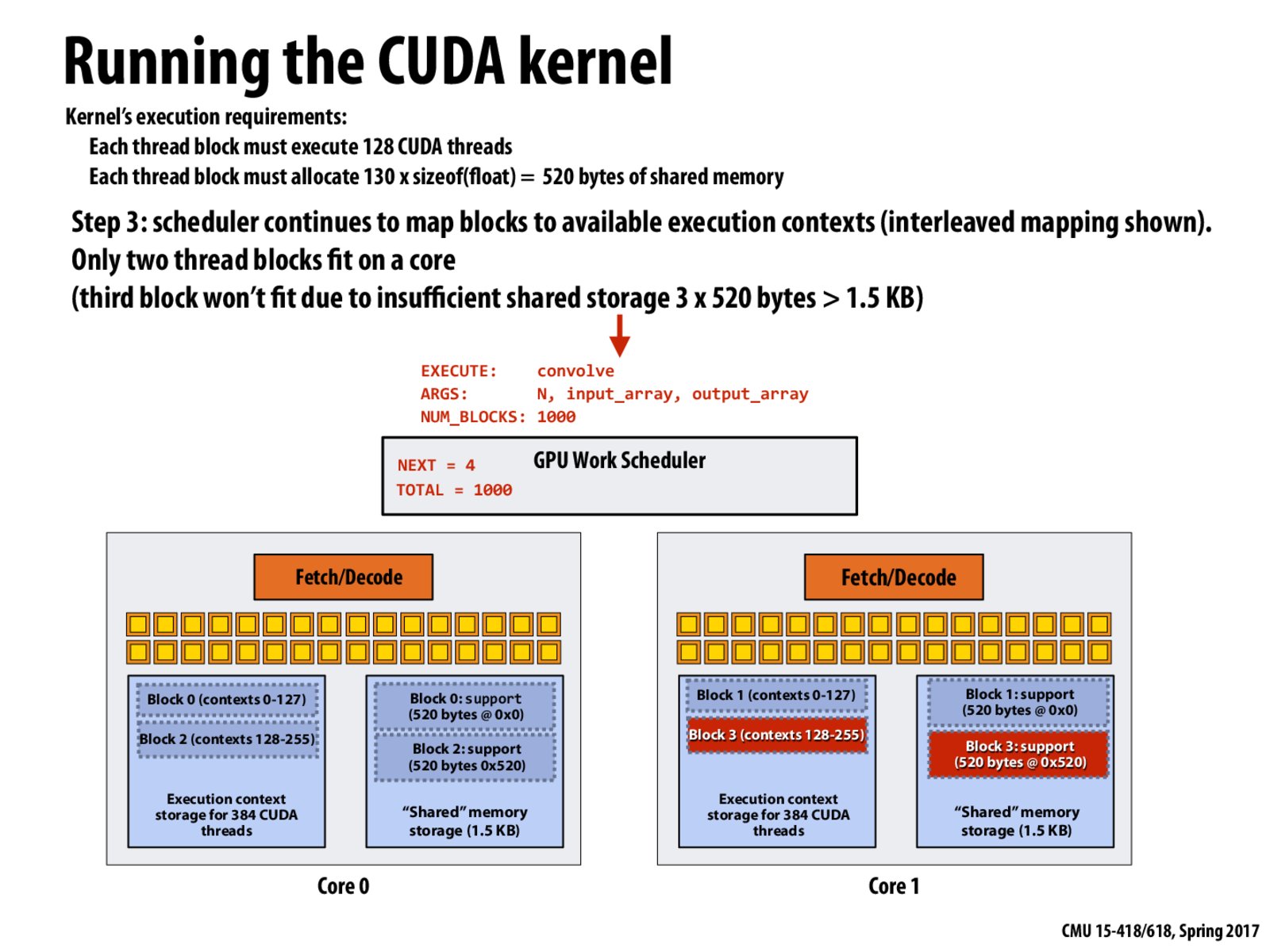
Question 1: At this point in the example (after four thread blocks have been assigned to cores), the scheduler can no longer assign thread blocks to cores. Why not? What must occur before block 4 can be assigned.
Question 2: Would it have been a valid scheduling policy for the GPU to reverse the order in which thread blocks are assigned to processors? E.g., first assign block 999, then 998, ... (or even assign blocks to core in random order)
Block 4 cannot be assigned because the binary file contains that each block needs 520 bytes of shared memory. The scheduler will check for this amount of memory, and as it is not available currently (1536 - 2*520 = 496 < 520), it won't assign block 4 to any of the cores. As soon as any of the 4 blocks (0-3) finish execution, memory will be available and block 4 will be assigned.
Yes, any scheduling policy would be valid. The thread blocks can be scheduled in any order.
I have a question. It is mentioned that each block must execute 128 threads. Each core can execute only 32 threads simultaneously. In slide 75 we learn that THREADS_PER_BLK cannot be more than the number of threads a core can run at once. So, this should give a compile-time error? Is there something I am missing?
Update - I think I get it. By 'execution on one core at once', it means that it should be able to assign execution contexts to all the CUDA threads in a block, and simultaneous execution is not mandatory. That actually makes sense and explains the deadlock argument we discuss in slide 75.
I agree with @nemo 's answers to the two questions, and the explanation to herself/himself's question.
At this point the scheduler can no longer assign thread blocks to cores because although we have enough execution context, we do not have enough shared memory available to support the allocation. So, the scheduler must wait until one of the running thread blocks completes. At that point, the scheduler can use those newly available resources to run block 4.
For question 2, we can assign the thread blocks because we can assume that there are no dependencies. However, we cannot break up each block since the threads in each block may communicate with each other through shared memory.
I agree with nemo in question 1. Only because the code in the kernel specifies the use of shared memory of size 520 bytes for each block we can't assign more than two blocks in an execution context. However, if we had not declared the use of shared memory in each block, then we could have assigned much more blocks per execution context!
In assignment 2, we faced a tradeoff of how much shared memory to use in each thread block, vs how many contexts could be assigned to each core.
I agree with the answers to the questions given above. To reiterate, for question 1, the scheduler can no longer assign thread blocks to cores because there is insufficient shared memory space to support allocation for a third block. Note that this occurs because we allocated 520 bytes of shared memory; if we didn't need to allocate the 520 bytes of shared mem, we'd be able to fit 3 blocks on a core because (128 threads for a block to execute * 3 blocks) = 384 threads and the execution context has storage space for 384 threads.
For question 2, the GPU can schedule blocks in any order. As long as there are resources available, thread blocks can be scheduled. Once the resources run out, the scheduler must wait until one of the thread blocks completes execution (in this case, any of the blocks 0 - 3) before continuing on to assign the next block (block 4) with the newly available memory.