Question: This would be a very good slide for someone to try and summarize the point of.
Cake
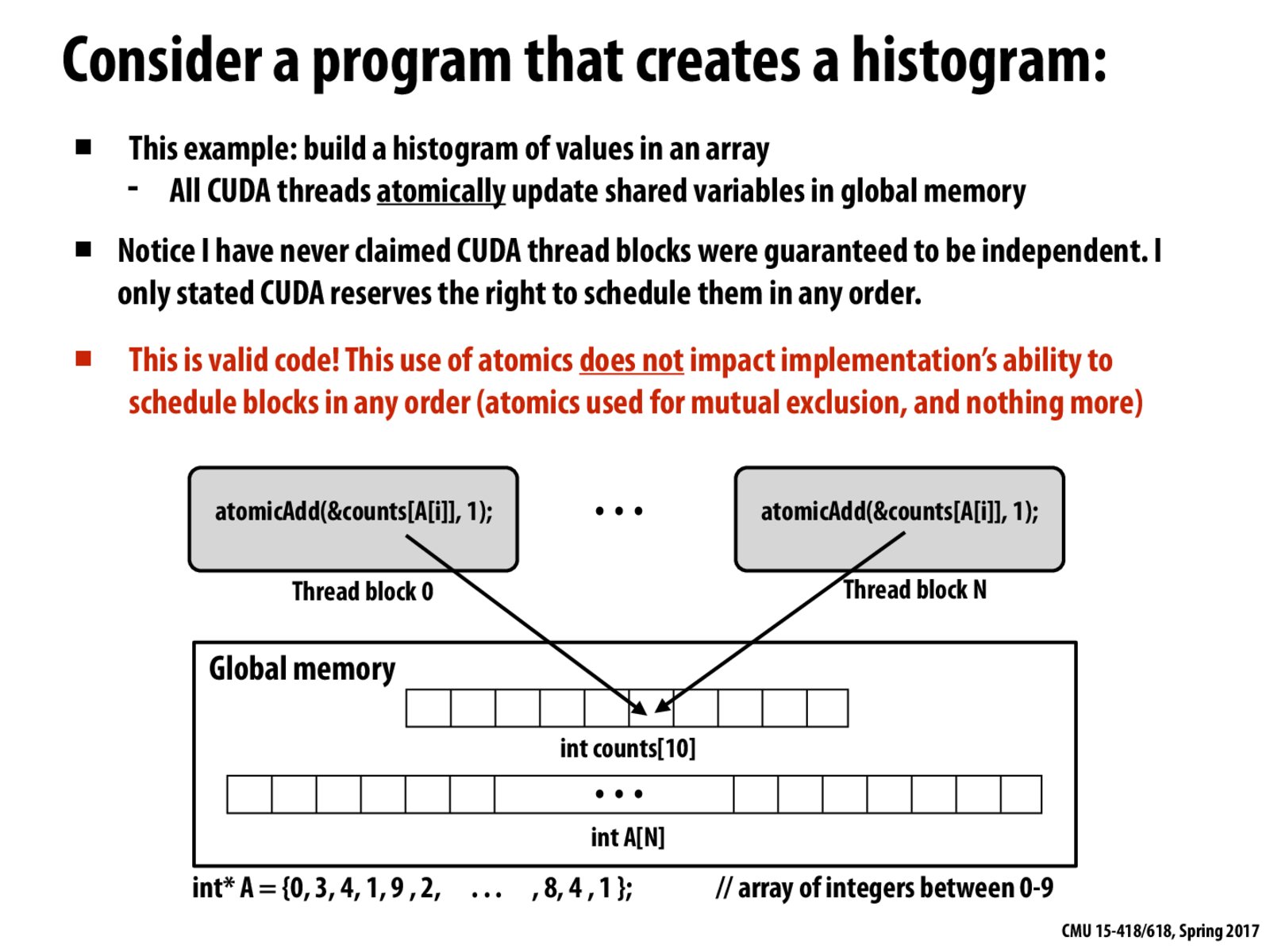
CUDA thread blocks can be executed or scheduled to run independently of each other, but the notion of "independence" exhibited by these thread blocks does not extend to independence of data or memory accessed.
jiangyifan2bad
The point I learnt from these two slides was: the best way to judge if CUDA block code is valid is to check whether the blocks can be scheduled in any order. Though the code in this slide does not guarantee independency, atomic is properly used so that the requirement of "scheduled in any order" is still reserved.
ZoSo
Even though the thread blocks can be scheduled independent of one another, there might still be dependencies in that if a thread from a thread block is holding a lock on a global data, another thread in a different thread block trying to access the same data location will have to wait - which essentially means that even thread blocks might not always be running completely in parallel.
mnshaw
Thread blocks aren't guaranteed to be independent, and can write and read from the same place in memory. CUDA thread blocks can be scheduled though, which is where you may want to be more thoughtful.
ask
CUDA thread blocks have independent execution. However, this does not guarantee order of execution amongst the thread blocks. For instance, if you have a hundred thread blocks and a hundred non-associative operators, and each block is responsible for performing one of the operators on the array element and storing the result in place,
(Ex. A[i] = A[i] "operator[blockIndex]" A[i])
then, we are not guaranteed that the operations are performed in the order in which the operators are stored.
Question: This would be a very good slide for someone to try and summarize the point of.
CUDA thread blocks can be executed or scheduled to run independently of each other, but the notion of "independence" exhibited by these thread blocks does not extend to independence of data or memory accessed.
The point I learnt from these two slides was: the best way to judge if CUDA block code is valid is to check whether the blocks can be scheduled in any order. Though the code in this slide does not guarantee independency, atomic is properly used so that the requirement of "scheduled in any order" is still reserved.
Even though the thread blocks can be scheduled independent of one another, there might still be dependencies in that if a thread from a thread block is holding a lock on a global data, another thread in a different thread block trying to access the same data location will have to wait - which essentially means that even thread blocks might not always be running completely in parallel.
Thread blocks aren't guaranteed to be independent, and can write and read from the same place in memory. CUDA thread blocks can be scheduled though, which is where you may want to be more thoughtful.
CUDA thread blocks have independent execution. However, this does not guarantee order of execution amongst the thread blocks. For instance, if you have a hundred thread blocks and a hundred non-associative operators, and each block is responsible for performing one of the operators on the array element and storing the result in place,
(Ex. A[i] = A[i] "operator[blockIndex]" A[i])
then, we are not guaranteed that the operations are performed in the order in which the operators are stored.