2.Thread block 1 will run infinitely and thread block 0 will never run.
emt
If the CUDA implementation runs block 0 first, it'll complete block 0 and then use the core to run thread block 1. The program will behave as expected.
But if the implementation runs block 1 first, then block 1 will be sitting there waiting for the code in thread block 0 to set that value. However, thread block 0 will never run because the core is being used to run block 1. Thus, the code does not follow the assumption that thread blocks need to be able to be scheduled in any order.
eourcs
It seems like the pertinent thing to note here is that CUDA doesn't have the concept of scheduling for fairness. Thus, thread block 1 being scheduled first and running in perpetuity is perfectly valid ordering.
nishadg
I am a bit confused about these built in atomic functions in CUDA and how they are implemented? Are there locks for each address, an interval of addresses, or does the scheduler just make sure that nothing is scheduled that uses that memory address?
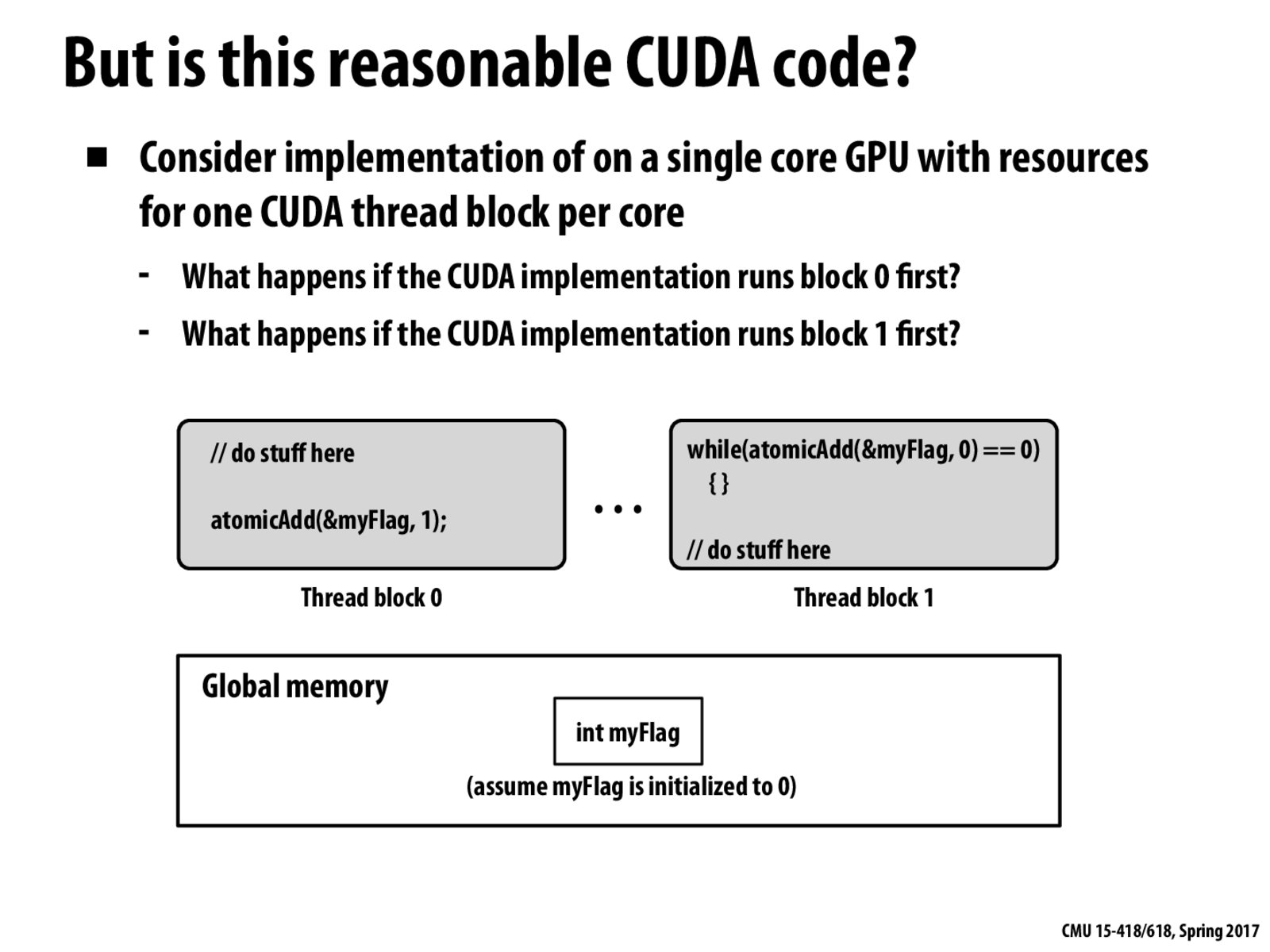
//do stuff herecode is executed//do stuff herecode1.Program runs well.
2.Thread block 1 will run infinitely and thread block 0 will never run.
If the CUDA implementation runs block 0 first, it'll complete block 0 and then use the core to run thread block 1. The program will behave as expected.
But if the implementation runs block 1 first, then block 1 will be sitting there waiting for the code in thread block 0 to set that value. However, thread block 0 will never run because the core is being used to run block 1. Thus, the code does not follow the assumption that thread blocks need to be able to be scheduled in any order.
It seems like the pertinent thing to note here is that CUDA doesn't have the concept of scheduling for fairness. Thus, thread block 1 being scheduled first and running in perpetuity is perfectly valid ordering.
I am a bit confused about these built in atomic functions in CUDA and how they are implemented? Are there locks for each address, an interval of addresses, or does the scheduler just make sure that nothing is scheduled that uses that memory address?