Note: Chi comes from Chihuahua. Since GraphLab mascot was a Labrador, and GraphChi is about processing big graphs on really small machines, the GraphChi folks went with the Chihuahua inspiration.
axiao
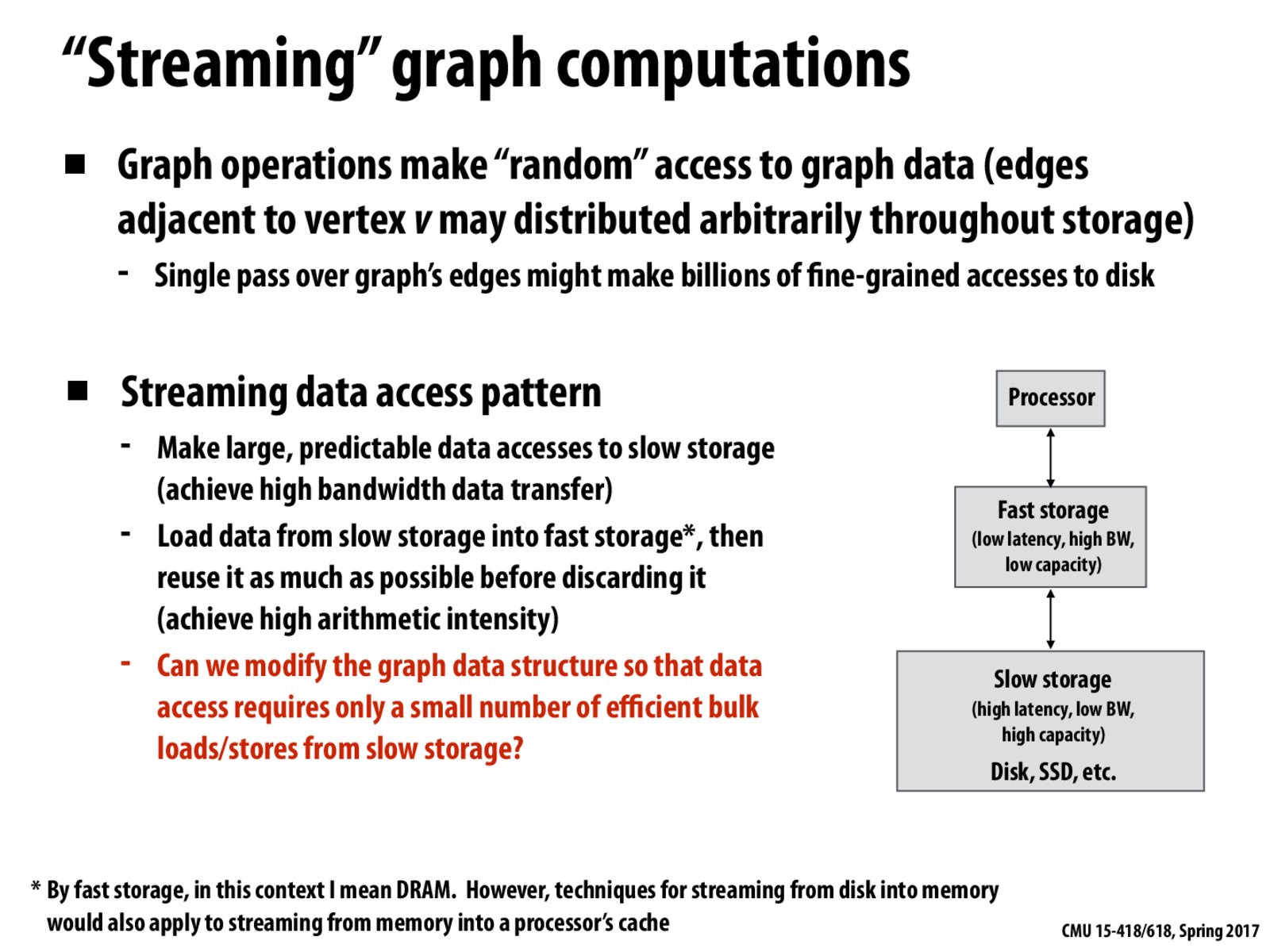
A streaming data access pattern is critical for high performance when the graph is too big to fit in memory. If we just naively laid out the graph in disk, then the random access pattern of graph operations would result in many disk seeks, each which takes about 10ms to perform, which might make it infeasible to perform the billions of fine-grained accesses to disk as mentioned in the slide.
A streaming disk read, however, takes about 30ms to read 1MB of data. This is orders of magnitude more efficient than reading 1MB of data with 1000 disk seeks each reading 1KB of data!
Unlike disks SSDs can perform random accesses more efficiently but suffer from repeated writes that can cause flash blocks to wear off. So the restriction for having to read large contiguous regions is more relaxed and sometimes we may want to place contiguous data in 2 different flash pages because they can be read in parallel. Are there any implementations of graphlab like libraries with SSD storage in mind?
GraphChi: https://www.cs.cmu.edu/~pavlo/courses/fall2013/static/papers/osdi2012-graphchi.pdf
GraphChi code: https://github.com/GraphChi
Note: Chi comes from Chihuahua. Since GraphLab mascot was a Labrador, and GraphChi is about processing big graphs on really small machines, the GraphChi folks went with the Chihuahua inspiration.
A streaming data access pattern is critical for high performance when the graph is too big to fit in memory. If we just naively laid out the graph in disk, then the random access pattern of graph operations would result in many disk seeks, each which takes about 10ms to perform, which might make it infeasible to perform the billions of fine-grained accesses to disk as mentioned in the slide.
A streaming disk read, however, takes about 30ms to read 1MB of data. This is orders of magnitude more efficient than reading 1MB of data with 1000 disk seeks each reading 1KB of data!
Source for latency numbers: Numbers Everyone Should Know from Jeff Dean
Unlike disks SSDs can perform random accesses more efficiently but suffer from repeated writes that can cause flash blocks to wear off. So the restriction for having to read large contiguous regions is more relaxed and sometimes we may want to place contiguous data in 2 different flash pages because they can be read in parallel. Are there any implementations of graphlab like libraries with SSD storage in mind?