If we have S shards, then going through the entire graph requires O(S^2) streaming reads/writes. The cool thing about this is that the number of streaming reads/writes is independent of the total number of vertices and edges (other than sizing the shards such that each subgraph fits in memory).
Master
Could someone explain this slide to me? If we have too many shards, so we will have to read from them, does the continuous access benefit still exist?
Also, suppose we want to access data required to process subgraph containing vertices in shard3, then we need to access region near the end of shard1 and shard2. Since we are don't know the exact range, we still have to scan all the data in the shards, right?
Of course, it looks better than unsorted case as we at least can early terminate in some cases. But I didn't see many improvements as claimed to be here.
lya
@Master The idea is that we partition edges according to the destination vertices of them, and sort each shard by the source vertices. In this case, the accesses will be continuous on disks, instead of random. For example, if we need all the edges containing vertices 1 and 2, we could take the whole shard 1, and access two consecutive blocks on shard 2 and 3.
Too many shards may degrade the performance, as the number of loads is linear with number of shards and length of the corresponding shard. However, the shards should be partitioned in a reasonable way, e.g. each shard spans a few pages.
We do not have to scan all the entries from the beginning, since we could use trivial space to store a structure like skip list, which gives hints about the beginning of each source vertex.
holard
Is it ever beneficial to partition based on connectivity (i.e. try to keep cliques in the same shard)? Or does that introduce too much complexity?
hdd
I think if partition is done based on connectivity, then a few graph nodes which have lot of connections could be in the first half of the graph tightly interconnected to each other and there might be one edge to another section of the graph which are sparsely connected to each other. In that case, we might have a scenario where there is unequal distribution as well as irregular accesses where a few requests always go out to other node and vice versa, i guess because that depends on the dynamic nature of the graph, might be too much complex in nature.
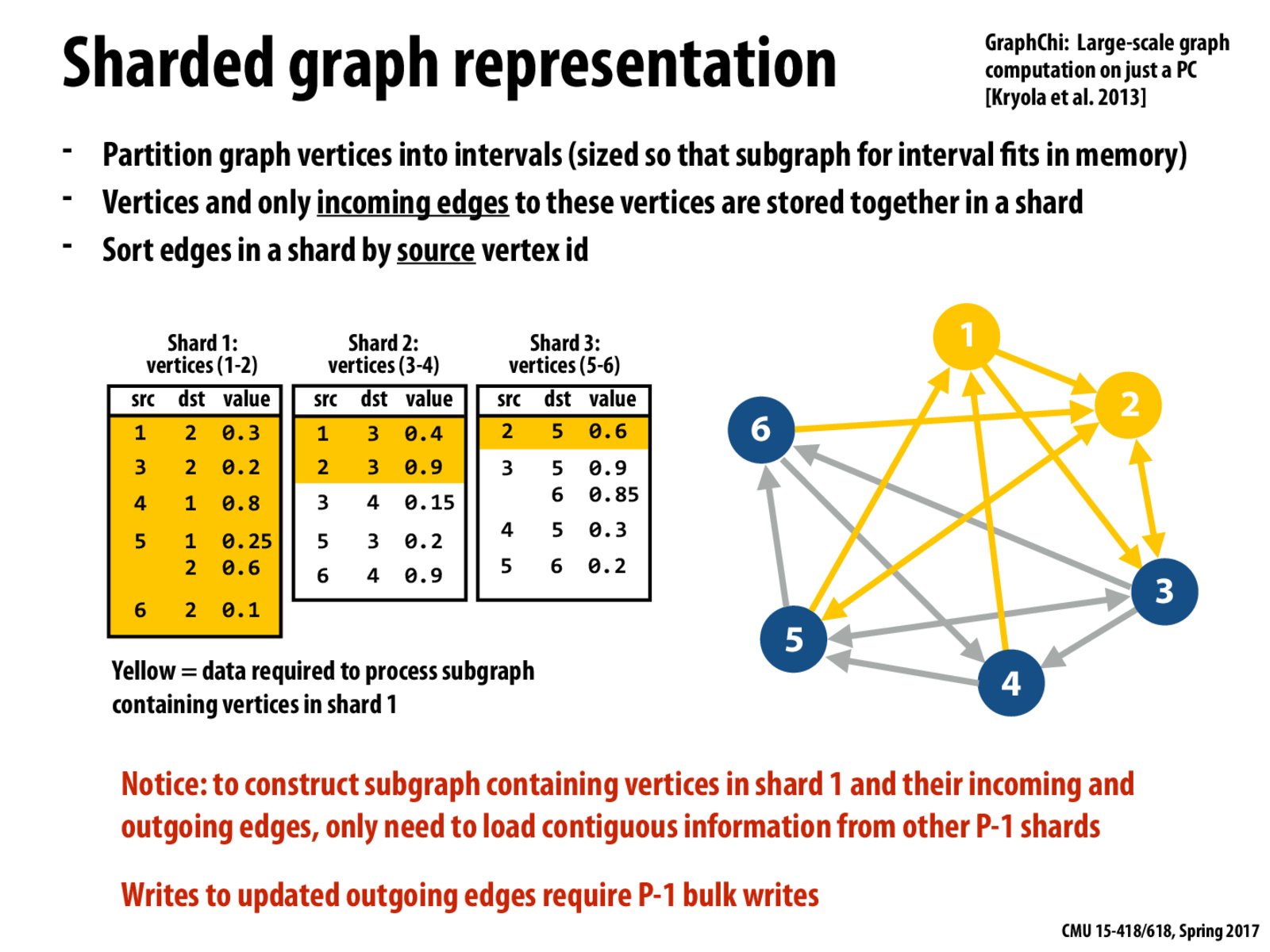
If we have S shards, then going through the entire graph requires O(S^2) streaming reads/writes. The cool thing about this is that the number of streaming reads/writes is independent of the total number of vertices and edges (other than sizing the shards such that each subgraph fits in memory).
Could someone explain this slide to me? If we have too many shards, so we will have to read from them, does the continuous access benefit still exist?
Also, suppose we want to access data required to process subgraph containing vertices in shard3, then we need to access region near the end of shard1 and shard2. Since we are don't know the exact range, we still have to scan all the data in the shards, right?
Of course, it looks better than unsorted case as we at least can early terminate in some cases. But I didn't see many improvements as claimed to be here.
@Master The idea is that we partition edges according to the destination vertices of them, and sort each shard by the source vertices. In this case, the accesses will be continuous on disks, instead of random. For example, if we need all the edges containing vertices 1 and 2, we could take the whole shard 1, and access two consecutive blocks on shard 2 and 3.
Too many shards may degrade the performance, as the number of loads is linear with number of shards and length of the corresponding shard. However, the shards should be partitioned in a reasonable way, e.g. each shard spans a few pages.
We do not have to scan all the entries from the beginning, since we could use trivial space to store a structure like skip list, which gives hints about the beginning of each source vertex.
Is it ever beneficial to partition based on connectivity (i.e. try to keep cliques in the same shard)? Or does that introduce too much complexity?
I think if partition is done based on connectivity, then a few graph nodes which have lot of connections could be in the first half of the graph tightly interconnected to each other and there might be one edge to another section of the graph which are sparsely connected to each other. In that case, we might have a scenario where there is unequal distribution as well as irregular accesses where a few requests always go out to other node and vice versa, i guess because that depends on the dynamic nature of the graph, might be too much complex in nature.