To handle latency of DRAM Access:
1. Pipeline
2. Multithread
3. Get more data in one go.
jkorn
Something else that was not mentioned that was DRAM needs to be refreshed, because capacitors lose charge over time. In particular, data for each row is temporarily latched and rewritten after a certain number of cycles so that it's value is maintained (for instance, a capacitor maintaining a bit value 1 will eventually read a 0 if its charge is not refreshed). RAM that doesn't need to be refreshed is called SRAM (static RAM) which is much more expensive (stores memory in latches which require more capacitors and transistors than DRAM, which has just one capacitor and transistor per bit), and therefore less common (often used in L1 caches, but not main memory).
paracon
If you precharge after every column access, you are assuming no spacial locality. The second scenario is optimising for the case of spacial locality.
rootB
Although drawn as the first step in the previous slides, precharge is for actually closing an opened row and getting ready for new row's activation. I am confused about what was mentioned in the lecture: why does having more precharge executions (after each column access instead of only when new row is accessed) save time? Shouldn't this extra precharge execution adds latency?
ayy_lmao
@rootB I think what is happening here is that DRAM can respond to the CPU after the column access, and then perform precharge. That way the precharge is not part of the latency because it has already responded to the CPU.
lfragago
Whenever we read a row from the DRAM into the row buffer, we actually discharged the capacitors corresponding to that row in the DRAM, so when we replace the row that is in the row buffer, we need to charge back the row in the DRAM ( to not lose the information we had in that row). That is why the Precharge (PRE) step is needed.
rootB
@ayy_lmao, then worst case latency in the slide shouldn't include PRE, right?
atadkase
@rootB When the PRE step occurs after every column access, the DRAM does that step between memory requests. In that case, the worst case latency would not include PRE. However, if the memory request queue is full, then PRE step still takes time, and would be on the critical path of the system.
sadkins
I am a bit confused about when PRE and RAS are necessary. From my understanding each time we read from a new row in DRAM we have to activate(RAS) it, but do we also have to precharge(PRE) the row buffer each time we move a new row to the row buffer?
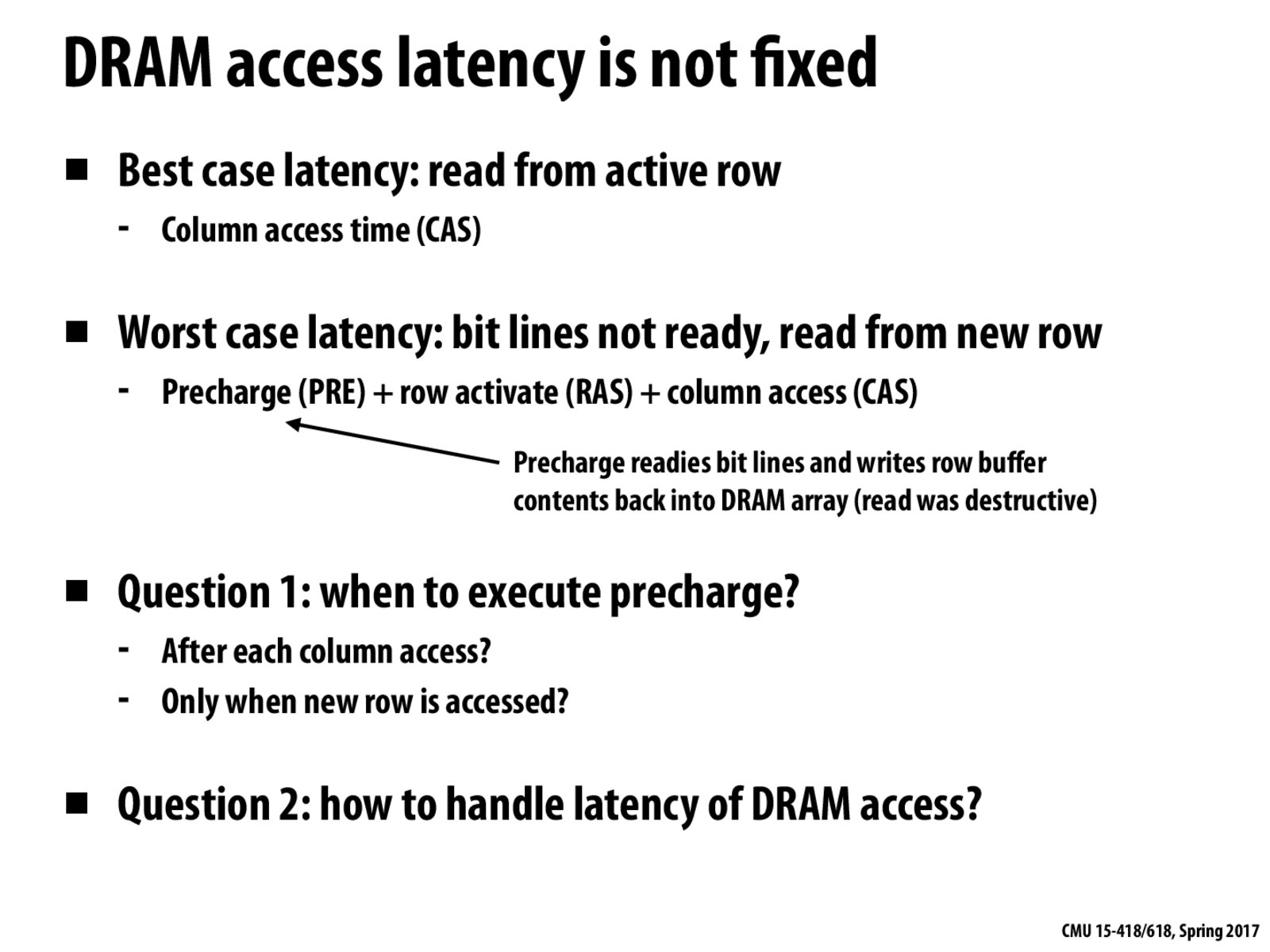
Only execute precharge when a new row is accessed
To handle latency of DRAM Access:
1. Pipeline
2. Multithread
3. Get more data in one go.
Something else that was not mentioned that was DRAM needs to be refreshed, because capacitors lose charge over time. In particular, data for each row is temporarily latched and rewritten after a certain number of cycles so that it's value is maintained (for instance, a capacitor maintaining a bit value 1 will eventually read a 0 if its charge is not refreshed). RAM that doesn't need to be refreshed is called SRAM (static RAM) which is much more expensive (stores memory in latches which require more capacitors and transistors than DRAM, which has just one capacitor and transistor per bit), and therefore less common (often used in L1 caches, but not main memory).
If you precharge after every column access, you are assuming no spacial locality. The second scenario is optimising for the case of spacial locality.
Although drawn as the first step in the previous slides, precharge is for actually closing an opened row and getting ready for new row's activation. I am confused about what was mentioned in the lecture: why does having more precharge executions (after each column access instead of only when new row is accessed) save time? Shouldn't this extra precharge execution adds latency?
@rootB I think what is happening here is that DRAM can respond to the CPU after the column access, and then perform precharge. That way the precharge is not part of the latency because it has already responded to the CPU.
Whenever we read a row from the DRAM into the row buffer, we actually discharged the capacitors corresponding to that row in the DRAM, so when we replace the row that is in the row buffer, we need to charge back the row in the DRAM ( to not lose the information we had in that row). That is why the Precharge (PRE) step is needed.
@ayy_lmao, then worst case latency in the slide shouldn't include PRE, right?
@rootB When the PRE step occurs after every column access, the DRAM does that step between memory requests. In that case, the worst case latency would not include PRE. However, if the memory request queue is full, then PRE step still takes time, and would be on the critical path of the system.
I am a bit confused about when PRE and RAS are necessary. From my understanding each time we read from a new row in DRAM we have to activate(RAS) it, but do we also have to precharge(PRE) the row buffer each time we move a new row to the row buffer?