In this situation, since the entire cache line is on the same chip, we read 1 byte of the cache line every clock cycle. This means we have a latency of 64 cycles in this example. We could improve this by interleaving bytes between the chips so that we can read bytes in parallel.
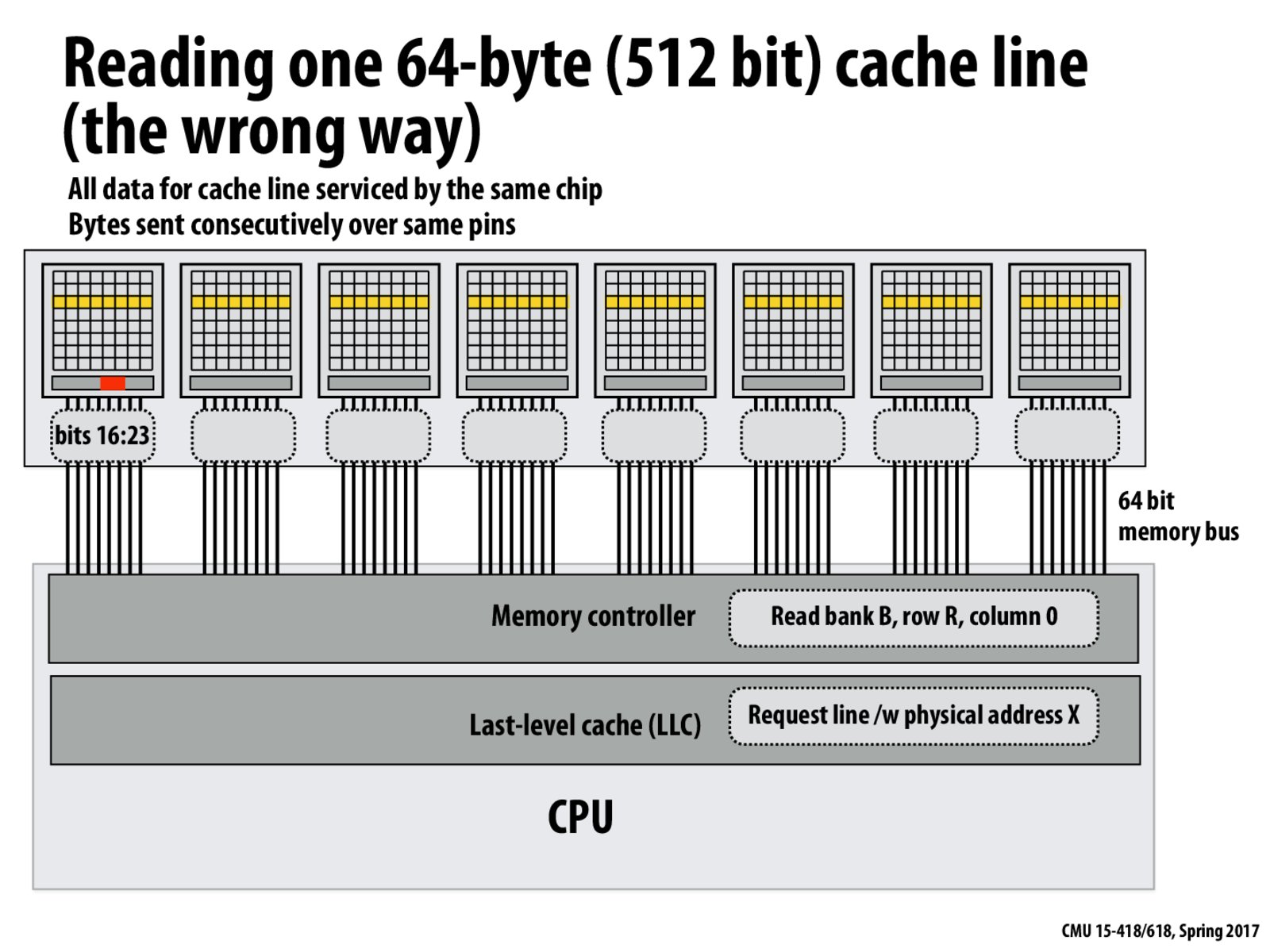
In this situation, since the entire cache line is on the same chip, we read 1 byte of the cache line every clock cycle. This means we have a latency of 64 cycles in this example. We could improve this by interleaving bytes between the chips so that we can read bytes in parallel.