As noted by a student in class, the physical addresses could be interleaved across DRAM chips with granularity larger than one byte. For example, we could put bytes 0-3 on DRAM 0, 4-7 on DRAM 1, etc. In that case, we would transmit a strided pattern of bytes over the bus each cycle (e.g. byte 0 from DRAM 0, byte 4 from DRAM 1, etc.), but that's okay, as long as we eventually obtain the whole cache line we want to load.
jmc
Kayvon also mentioned that one possible optimization is to load first the specific word that the memory request asked for and return it so that the processor can begin working with it, while the rest of the cache line finishes loading in. Of course, this would require changes to the semantics of how cache lines are loaded and processors' expectations about them.
ykt
This optimization is very interesting. If the word was suppose, somewhere in the middle of the cacheline, then ideally the controller would read those bits first and then read the others.
Levy
@ykt
The begin of cacheline is supposed to be aligned. Therefore, we can assume that all the read issued to DIMM is always at the beginning.
themj
In this case, once you load in one (row, column), you get a 64-bit cache line, which is the desired result in most cases. The same effect can be reached by interleaving the bytes more coarsely (up to 8 bytes on each DRAM).
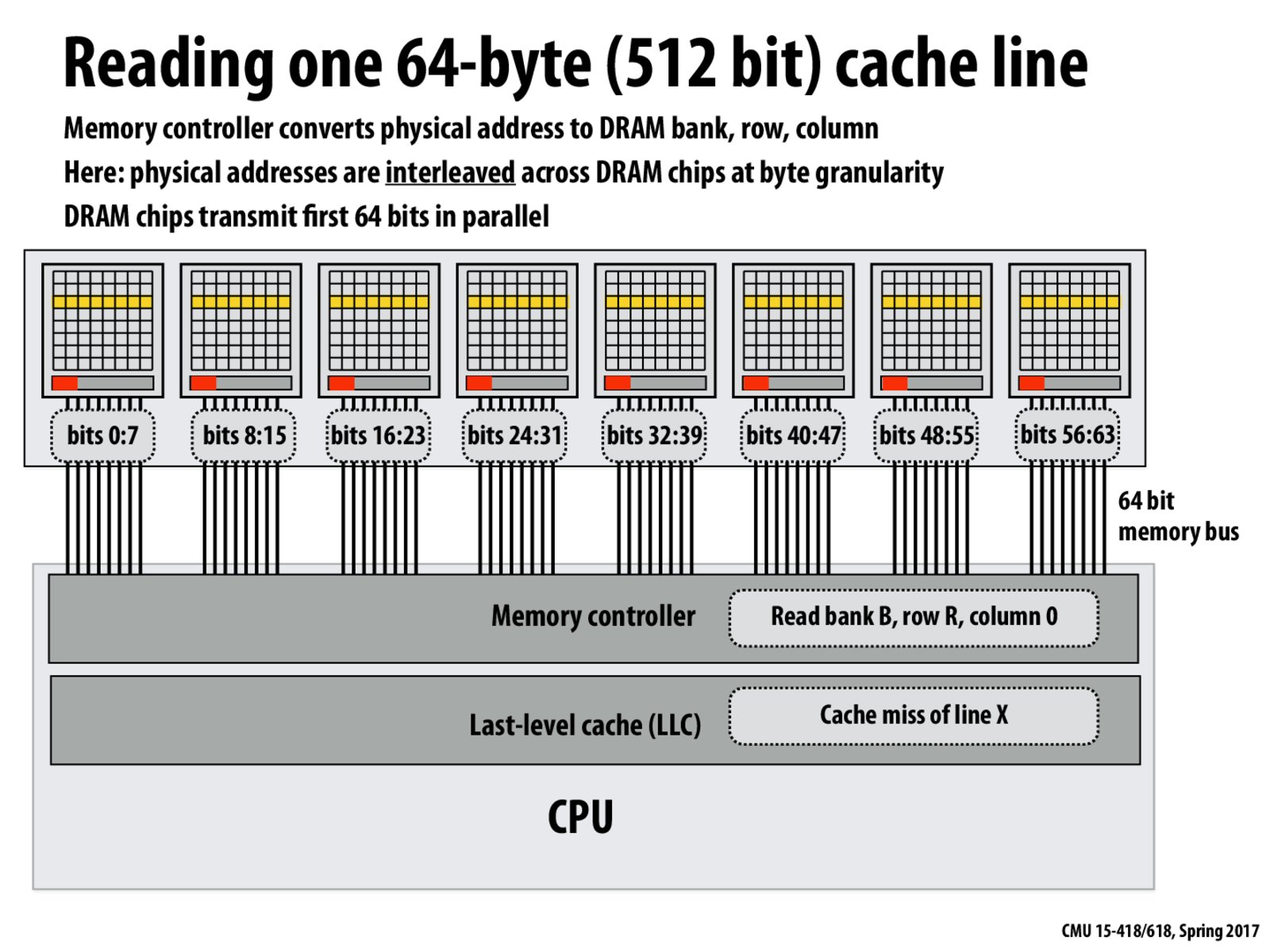
As noted by a student in class, the physical addresses could be interleaved across DRAM chips with granularity larger than one byte. For example, we could put bytes 0-3 on DRAM 0, 4-7 on DRAM 1, etc. In that case, we would transmit a strided pattern of bytes over the bus each cycle (e.g. byte 0 from DRAM 0, byte 4 from DRAM 1, etc.), but that's okay, as long as we eventually obtain the whole cache line we want to load.
Kayvon also mentioned that one possible optimization is to load first the specific word that the memory request asked for and return it so that the processor can begin working with it, while the rest of the cache line finishes loading in. Of course, this would require changes to the semantics of how cache lines are loaded and processors' expectations about them.
This optimization is very interesting. If the word was suppose, somewhere in the middle of the cacheline, then ideally the controller would read those bits first and then read the others.
@ykt
The begin of cacheline is supposed to be aligned. Therefore, we can assume that all the read issued to DIMM is always at the beginning.
In this case, once you load in one (row, column), you get a 64-bit cache line, which is the desired result in most cases. The same effect can be reached by interleaving the bytes more coarsely (up to 8 bytes on each DRAM).