In lecture, we originally thought this version would perform better due to spacial locality, because each instance touches a bunch of elements right next to each other. Although our reasoning was on the right track, the conclusion is actually incorrect! In order to hit the same cache line, we need to give different instances adjacent values. This way, at any moment in time, the SIMD load instruction is retrieving adjacent data.
pagerank
I thought this was better at the first glance, though I am also considering about caching. I thought each instance keeps an independent piece of cache. In this way, it would be better if an instance is dealing with a block of data regarding the spatial locality. But in reality, the cache is shared with the gang.
If you also made mistakes here, is this your reason? Upvote it to let me know!
ykt
Also, with this approach, we will still get cache hits on the next three iterations, given that they are not moved out of the cache for some reason. But, I guess issuing memory load of 4 cache lines at once would give worse performance compared to issuing memory load of one cache line per iteration. This maybe because, it would be easier to hide latency with the latter cache.
eosofsky
Just to clarify what @pagerank said, since the gang/instance abstraction is implemented as SIMD instructions (see slide 11), all instances within a single gang must run on one core. As shown in lecture 2, the L1 and L2 caches are on the core and the L3 cache is shared by all cores. Thus you are correct in saying that all caches are shared by a gang and each instance does not have an independent cache.
hpark914
This is worse than the previous version with interleaved assignment because if you look at each iteration across the instances, spatial locality is worse here than in the interleaved assignment.
anonymous
Actually, this version uses gather/scatter to access memory while the previous version uses vector loads and stores to access memory. So, the previous version is better in performance.
fxffx
The blocked assignment of program instances is worse than the interleaved assignment, because the latter can utilize a single load instruction to load data for each instance at one time, but the former can not.
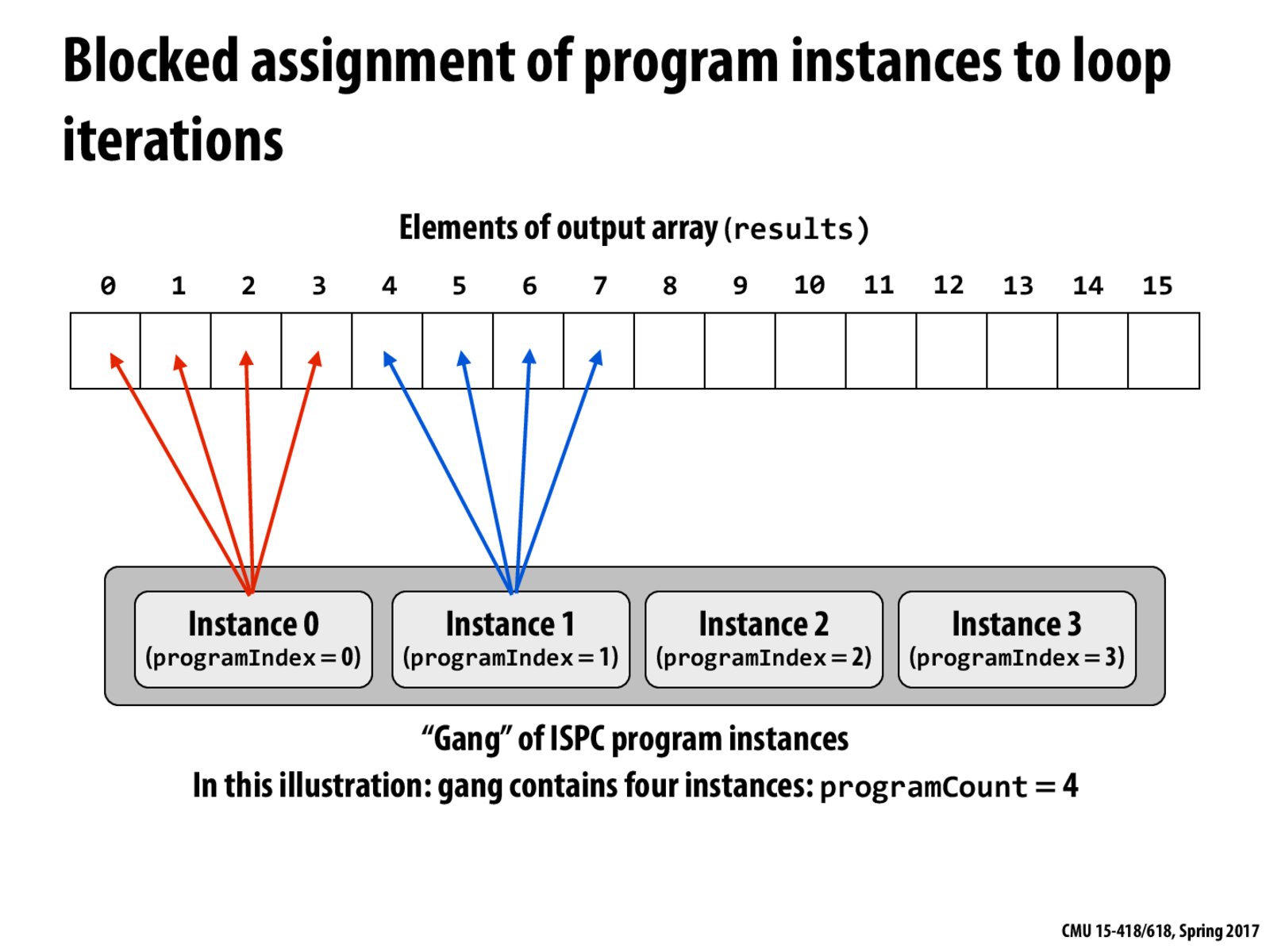
In lecture, we originally thought this version would perform better due to spacial locality, because each instance touches a bunch of elements right next to each other. Although our reasoning was on the right track, the conclusion is actually incorrect! In order to hit the same cache line, we need to give different instances adjacent values. This way, at any moment in time, the SIMD load instruction is retrieving adjacent data.
I thought this was better at the first glance, though I am also considering about caching. I thought each instance keeps an independent piece of cache. In this way, it would be better if an instance is dealing with a block of data regarding the spatial locality. But in reality, the cache is shared with the gang.
If you also made mistakes here, is this your reason? Upvote it to let me know!
Also, with this approach, we will still get cache hits on the next three iterations, given that they are not moved out of the cache for some reason. But, I guess issuing memory load of 4 cache lines at once would give worse performance compared to issuing memory load of one cache line per iteration. This maybe because, it would be easier to hide latency with the latter cache.
Just to clarify what @pagerank said, since the gang/instance abstraction is implemented as SIMD instructions (see slide 11), all instances within a single gang must run on one core. As shown in lecture 2, the L1 and L2 caches are on the core and the L3 cache is shared by all cores. Thus you are correct in saying that all caches are shared by a gang and each instance does not have an independent cache.
This is worse than the previous version with interleaved assignment because if you look at each iteration across the instances, spatial locality is worse here than in the interleaved assignment.
Actually, this version uses gather/scatter to access memory while the previous version uses vector loads and stores to access memory. So, the previous version is better in performance.
The blocked assignment of program instances is worse than the interleaved assignment, because the latter can utilize a single load instruction to load data for each instance at one time, but the former can not.